
Since Microsoft announced Azure Synapse Analytics back at the Ignite conference in 2019, the data community has expressed a lot of excitement and skepticism. A lot of people thought that integrating so many different components like MPP warehousing, Spark, pipelines, data flows and more would be a really hard task to pull off, or that they would just bundle them up on the same screen with no real integration happening.
Fast forward to today. The service is now generally available (GA) and I can say it’s a very pleasant surprise! Not only are all the features in one single workspace, but the integration is really there. You can process tables from SQL with Spark and vice versa, you can tap into the data lake storage service seamlessly and it serves as the universal glue to connect any service to the power of Synapse.
Most importantly, Microsoft hasn’t taken their foot off the pedal and we continue to see a steady trickle of updates and new capabilities coming out every month. In this post I’ll summarize the main updates I’ve spotted.
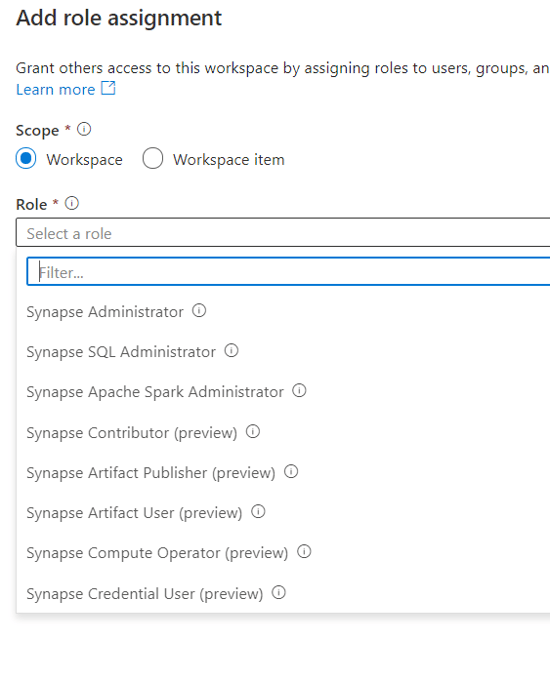
Improved RBAC controls
When Microsoft released the service, the RBAC (role-based access control) roles available were not very granular. They provided far too much functionality on each role rather than drilling down for more granular control.
That’s been addressed now with multiple new roles that control more specific features and can be combined with storage, Azure subscription RBAC and Github to secure all layers of a Synapse solution.
This is especially important for Synapse since it was designed as a collaborative environment. It’s critical for any implementation that an organization can satisfy their security requirements by configuring proper segregation of duties.
Lower pricing for storage
Microsoft has lowered the monthly cost of storage for the dedicated SQL Pools by 90 percent! Whereas Azure SQL Data Warehouse (the previous incarnation) was priced at a level that was OK for production but not really attractive for non-prod workloads, Synapse is now only $23/month* for 1TB.
This makes Synapse storage cost competitive with all other cloud DwaaS offerings like RedShift, Bigquery or Snowflake. It also opens the service up to be widely used as a learning tool. You can start it up, use it and discard it after one week, for example, while keeping the cost below the $20 to $30 dollar mark for storage plus several hours of compute consumption.
I’d still like to see a proper non-prod pricing for the compute side of the price equation, but this is a good first step.

(*Note: prices are in US dollars and are accurate at the time of publication)
Source control integration
The Synapse workspace now allows all your artifacts to be source controlled to either GitHub or Azure Repos. This means you can work on multiple branches and submit pull reviews straight from your workspace interface.
It also means that you can follow whatever branching standard you use on your team. You can have multiple team members collaborating by creating different artifacts (notebooks, pipelines, etc.) and use the source control infrastructure as the way to merge everything back into one bundle for release.
I tested this capability by creating a new Synapse workspace from scratch — 100 percent empty — then syncing it to my GitHub repo. It worked with no issues and every single artifact was imported to the new workspace without problems. This means we can use this to implement proper lifecycle management of the scripts through different Synapse environments (DEV-> TEST -> PROD).
New serverless T-SQL features
The set of allowed T-SQL constructs in the serverless engine continues to expand, with support added for STRING_AGG, OFFSET/FETCH, Pivot/Unpivot, SESSION_CONTEXT and CONTEXT_INFO.
This is a good signal that the serverless engine is here to stay, and Microsoft plans to continue adding features until it reaches parity with the “stateful” dedicated SQL pool engine. The context functions are especially interesting since they open the door to easily maintaining some state between different serverless calls without having to rely on some sort of state external table on storage.
There’s a lot of work Microsoft can still do to optimize and improve the serverless engine — after all it’s the newest feature introduced by Synapse — so I expect many updates in 2021 on this topic.
Improved notebook cell controls
They’ve made a small quality of life improvement to the notebook experience; each cell has now an easy-to-reach menu to change the cell type, remove it or move it around the notebook.
It’s not particularly life-changing, but it’s a good sign that more things are coming. I’m really excited to see what else Microsoft has up their sleeves on the notebook space as it’s an area where the GUI and visuals can really add to the overall experience.
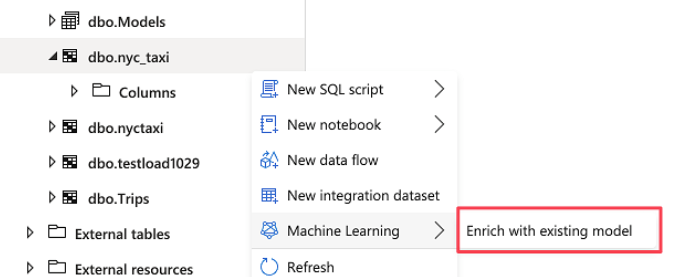
ML integration
Microsoft has now added integration between Synapse and the Azure Auto ML services by allowing you to score a table against an existing model by simply following a visual wizard. This capability has been part of SQL Server for a while but it was all done through code. This isn’t really something that would be considered for production use, but for casually evaluating a model it’s a big time saver.
I wouldn’t be surprised if at some point we see some integration of the actual model authoring experience in the Synapse workspace itself as well, but at this point it’s too early to tell.
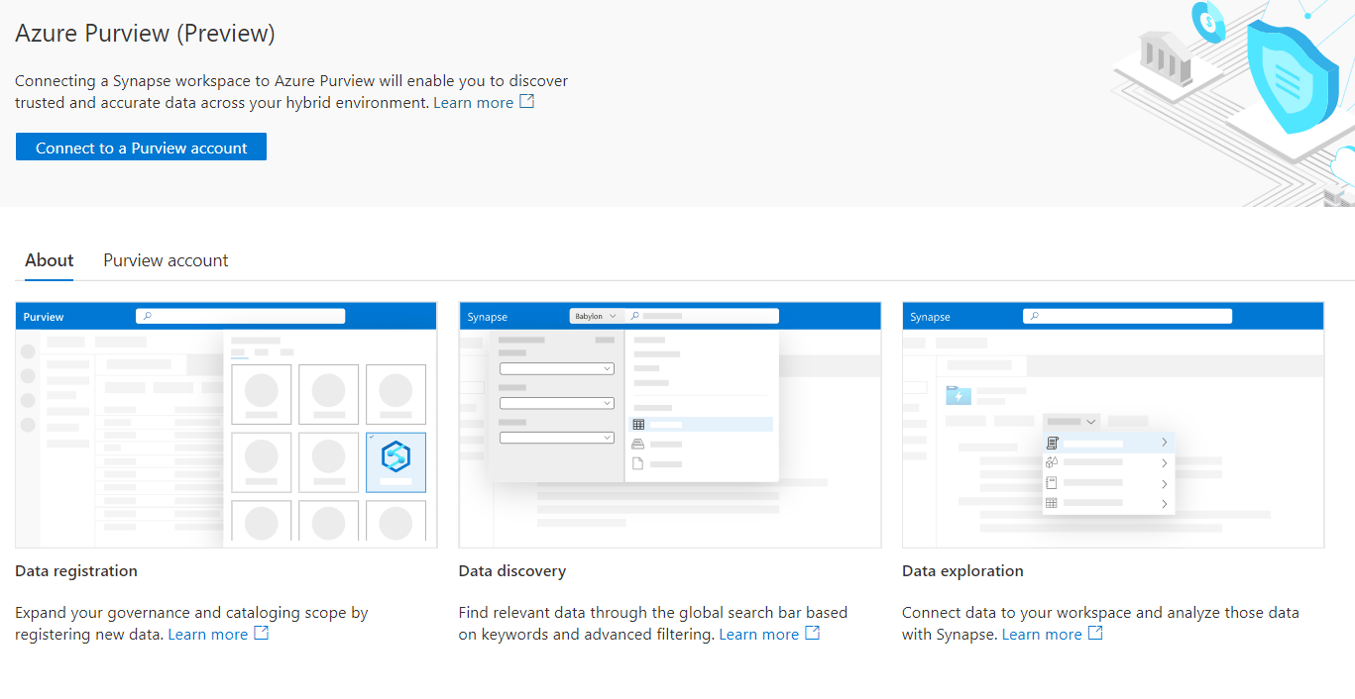
Azure Purview Integration
Along with the GA release of Synapse, Microsoft also announced the preview of Azure Purview. Purview is a data catalog, tagging and lineage service that can crawl all the Azure data services and will likely extend to on-premises sources as the product develops.
The Synapse workspace now has the option of connecting to a Purview account so that all your Synapse tables are crawled by Purview and thus added to your living data catalog.
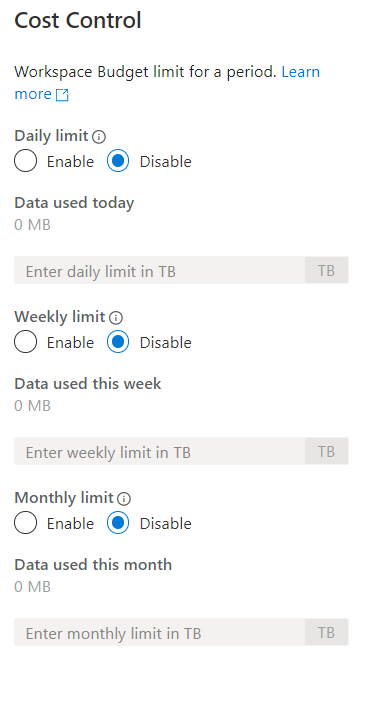
Cost quotas for serverless
One concern that folks often have with serverless offerings is the possibility of runaway costs. Since you pay by the data processed per query, it is hard to forecast the cost of every month if the workload is quite variable. One developer/analyst can also inadvertently blow through a lot of money by running a very heavy query.
To mitigate this issue, Microsoft has introduced cost control capabilities for the serverless SQL engine, with the ability to set daily, weekly and monthly limits.
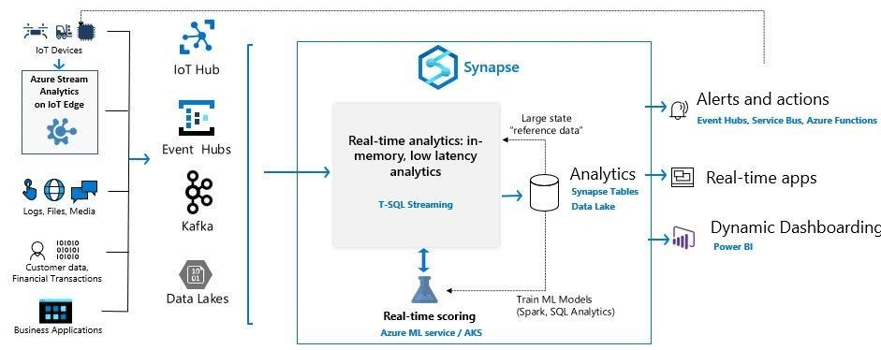
Native T-SQL streaming
For a long time I’ve mentioned that I wouldn’t be surprised if eventually the same idea behind “Stream Analytics” was embedded somewhere in the Synapse service. It looks like it’s finally here in a gated preview that allows streaming from Event Hubs, IOT Hubs, Kafka or Azure storage with egress capacity of up to 200 Mbps (enough for a lot of use cases).
This streaming implementation is not some simple afterthought. Microsoft is adding capabilities like time window functions, DDL support for manipulating streaming objects and in-memory computation of the real-time operations to minimize latency as much as possible.
Once the streaming is done into the Synapse engine, you can process it with your business logic and aggregations through native T-SQL queries. You can even use the ML capabilities built-into the SQL engine to do real-time scoring. This is just another piece of the grander data platform puzzle that clients won’t need to put together themselves since it will be a turnkey capability built right into Synapse.
Conclusion
All this has happened in just the first few months of the year. I’m really excited by what the future holds for this service. The barrier of entry for large scale analytics both financially and from a learning curve perspective has never been lower!


