In our previous post we discussed the five phases of data governance programs. These include define, design, build, transition and measure. These phases allow us to plan work, execute, and understand a program’s impact while adjusting future prioritization and maximizing impact to the organization. Building upon this lifecycle, we now discuss the functional capabilities that are provided by data governance teams to enable and empower the organization. In addition to the organizational elements needed for successful data governance, we discuss organizational models and relative levels of distributed decision making for maximizing organizational velocity.
While the scale of a data governance organization will fluctuate based on the scale of the business, the regulatory risk to the organization and the level of digital technology adoption, there are five key components that will be present in any data governance team. These could be roles played by a small set of individuals, or functions with dedicated teams to focus on delivering based organizational scale.
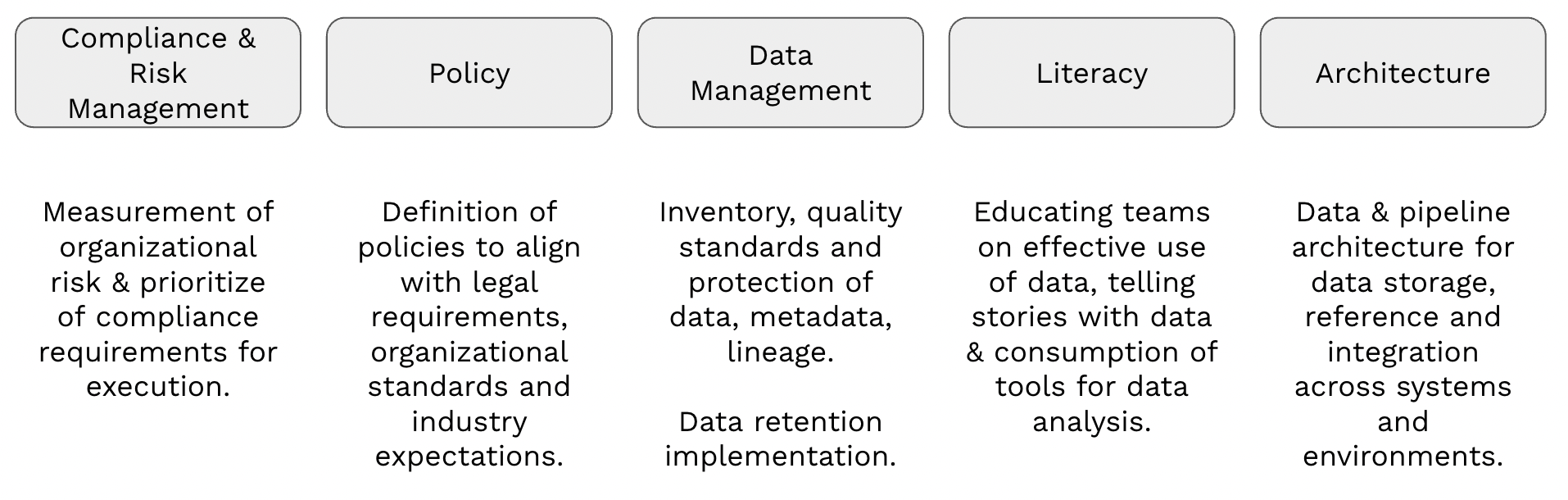
- Compliance & Risk Management. This function is about ensuring that compliance obligations, risks & remediations are captured, tracked through completion and prioritized to minimize exposure to the enterprise. This function focuses on the holistic organization view of risk and obligations while advising individual business units on point decisions regarding prioritization of work, risk reduction and investments.
- Policy. The policy team is a working group that spans the data governance function, but also HR, compliance, legal, and facilities teams. Their role is to identify policies to be written, facilitate their creation with other partner teams, and drive the training and awareness of them through the literacy function.
- Data Management. Data management is the function responsible for managing how data moves around the organization, how it is stored and feeding requirements into technical architecture teams for design & later implementation. This domain typically focuses on data retention, protection, lineage, and the associated metadata for managing across the enterprise. The data management function is the path from policy definition to practical application and usability in the organization.
- Literacy. The data literacy function is about enabling the entire organization to effectively use data, communicate with data and to leverage the available tools and technology. Data literacy is often associated with learning and development programs to ensure training material is available and aligned with industry treads, as well as used to reinforce the corporate priorities, objectives, and standards. Additional reading on data literacy can be found here.
- Architecture. The architecture function is central to ensuring that engineering teams have reusable patterns for implementation and integration. While the enterprise may have an architecture function as well, they’re close partners to the architects focused on the data governance function. The data governance architecture role is about understanding and influencing where and how data is created, how it is moved about the organization, and how data is stored and protected. This architecture team becomes the bridge between policy, data management, and technology implementation.
Each of these is a function that a modern data governance program will require to be effective. The organizational structure for these can vary wildly based on an organization’s size, maturity with data consumption, number of legacy technology platforms, and the level of regulatory oversight experienced. As you begin to think about how best to structure the organization around these functions, different models–including centralized and federated–can support building scale and speed simultaneously with the organizational structure.
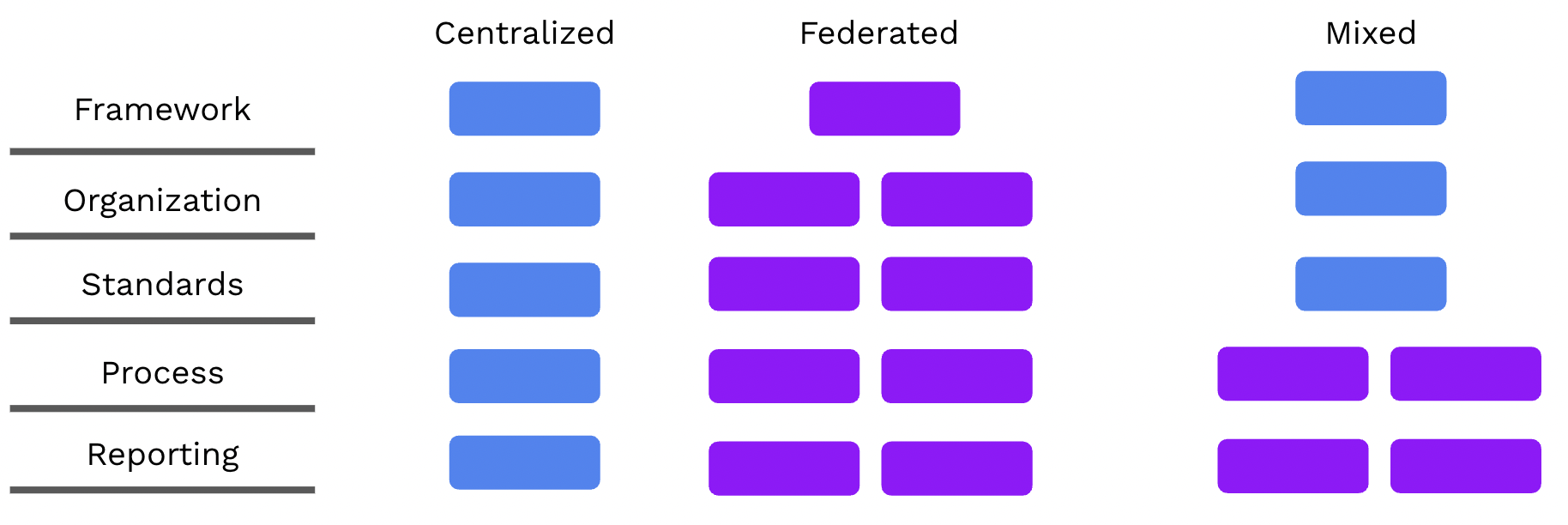
- Centralized. Centralized organizational models are typically found in larger, more established organizations. They are also more common in very highly regulated industries where the risk of non-compliance is costly. The centralized model will often operate the slowest because of the need to make centralized decisions and a high level of process rigor common in longer-lifetime organizations. Centralized models provide an advantage to organizations beginning their data governance journey due to the ability to enable and coordinate with a smaller number of people who are all part of the same organization. Many times, organizations will move from centralized to distributed models as their data governance programs mature.
- Federated. Many digital native organizations will begin with a federated model for data governance. They’ll distribute the execution of making decisions, prioritizing work and implementing to the teams closest to executing and nearest their customer base. Federated teams provide an advantage for risk based decision making being made closest to the teams implementing technology and controls, but can have limitations to central visibility and corporate wide risk for executive leadership.
- Mixed. The reality with most organizations is that a pure centralized or distributed model does not allow for a balance of risk management and implementation. Most organizations leverage a hybrid where policy and priorities are set centrally, allowing teams to make their own decisions on implementation and measurement of impact.
The mixed model allows for centralized working teams that share knowledge, share approaches, and contribute to common data literacy needs while also allowing teams at different places of technology adoption to implement policies in the way that is right for them. The most effective mixed organizations ensure feedback loops where all learnings in distributed teams are shared with the centralized teams for reuse and consumption across other teams.
In addition to the communication and feedback loops, there are other key considerations when designing your organizational model.
- Geographic Impacts. As organizations expand into new geographies, there are added complexities to their data storage architectures, their customer base and regulatory requirements. This geographic growth will often trigger a move towards more mixed organizational models, allowing decisions to be made locally about data governance needs and policies in a specific region to ensure alignment with local legal experts, customer needs and available technical capabilities.
- Visibility. As organizations grow in a federated or mixed model, visibility into compliance can grow challenging. Visibility can include compliance and audit obligations, as well as inventory of data assets, private information, and third party contractual obligations. A mixed model should consider how best to provide uniform visibility across the enterprise to compliance, policy enforcement, exceptions, and workarounds to best manage enterprise wide risk.
- Data Complexity. Organizations vary on the complexity and sensitivity of their data assets. For organizations that collect simple data without identifying individuals, a lower risk posture is present, allowing for more decisions to be made at business unit or team levels. For organizations managing highly sensitive data that identifies consumers or has legal obligations, including healthcare data, the need for more central policy definition and literacy programs is critical in ensuring all teams have been properly trained on legal obligations and tools available for data protection.
- Partnership Complexity. For organizations that exchange data with third parties, an added dimension comes into account for data governance. Many times, that partnership will include forms of data governance policy that the third-party must follow for data retention, destruction, or later transfer to downstream entities. Where these types of needs are present, a focused working team including legal, technical, and policy representation is present to discuss and formalize the organization’s approach in leveraging third-party data or sharing data with third parties.
There are two primary dimensions to a data governance program. First there are the functions necessary to be successful, including compliance and risk management, policy, data management, literacy, and architecture. Second, there’s the organizational model for how these capabilities are structured across the enterprise, typically in a mixed model between centralized and federated teams. The intersection of desired speed for the organization and the inherent risk in their operating market will define the appropriate level of mixed organizational structure.
In our next discussion, we’ll explore how to kickstart your data governance programs. We’ll discuss the needs of an organization starting a new program, as well as those of an organization looking to restart an existing program to better align with changing business needs, set a new vision, and accelerate their executions.
Feel free to share your questions in the comments and subscribe so you don’t miss the next post.

