The problem
When building data pipelines, it’s very common to require an external API call to enrich, validate or obfuscate data using external services. This might happen with streaming or batch pipeline. The situation is the same: call external services from a data pipeline in an efficient way and at the same time, and avoid any quota limit around those external services.
To tackle this issue, we need to assess the framework and tooling capabilities. In this case, I’m going to provide the details of how I would do it if the pipeline were a Dataflow job, and I will use Java for the sample job since it is commonly used for this kind of pipeline.
Possible solutions
Dataflow (Apache Beam) does not offer any caching options. This is fine if we take into consideration the shared-nothing architecture approach used in its design, but sometimes we need that feature in order to efficiently process some workloads. The closest thing would be Stateful processing, which we can use even though it is used for other purposes and with the implication that the state is distributed and partitioned by key and window. We can also use a solution based on stateful processing, but it’s more complex and has some additional trade-offs. Remember, we are looking to cache objects that are the result of an interaction with an external service.
One possible solution would be to cache the frequent API calls or group them in a bulk API operation. The latter is not always possible, but if we have control over the design of the API, it would result in better performance and resource utilization in some situations.
What to cache
First of all, we need to understand what API responses and objects are cacheable. Good candidates would be objects that:
- Don’t change often (whatever often means for the business around them)
- Are responses of idempotent calls
- We know the time to live (TTL)
Where to cache it
There are many alternatives, but we need an out-of-process cache for keeping the state live independent of the job threads and worker lifecycle; otherwise, we will lose it.
We could use any distributed cache: Hazelcast, Memcached and Redis would be good options.
Google Cloud offers the Memorystore managed service, which is compatible with Memcached and Redis, and any Memcached client implementation is useful. I saw a few samples from Google that use the Spymemcached client, so I will use the same for my example.
Before running the code
We need to make the initial setup of our Google Cloud project components, so let’s assume we have a project to play with.
Before running the code, we need to set up a few things:
- VPC
- Default VPC would be OK for running the sample code, but feel free to create a new one and adjust the parameters to pass to the Dataflow job.
- GCP bucket for staging files and serve as temp location
- Pubsub topic and subscription for that topic
- Service account with Dataflow worker permissions, storage admin access to GCS, Memorystore editor and PubSub subscriber
Additionally we need to get an API key for the weather service—for that, go to the OpenWeather site and follow the steps to get an API key for the free tier.
Sample Job with Memorystore
The example job will process messages from pubsub in a streaming fashion. The payload of the messages models simple sensor data that requires some enrichment with the local temperature.
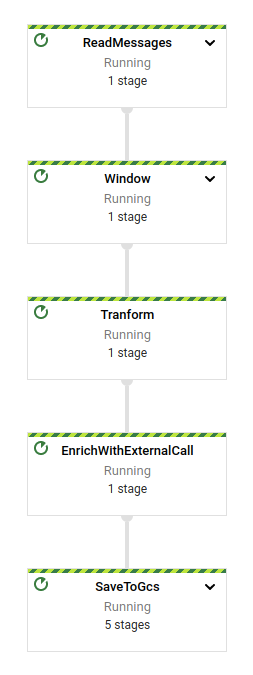
The job will take the message and perform a lookup on the cache first in the EnrichWithExternalCall step. If there is a hit, the cached data will be used; otherwise it will perform an external call to the weather service to get the data. We are assuming that the temperature for the same location is asked over and over again for different sensors in the same area, so it makes perfect sense to cache that for a given range of time. If we know how frequently the temperature is updated, we can set that as TTL for the cached object.
MEMORYSTORE SETUP
Let’s create a memory store instance:
# Enable de API gcloud services enable memcache.googleapis.com #Create the cache instance gcloud beta memcache instances create df-cache --node-count=1 --node-cpu=1 --node-memory=1GB --region=us-west1 #Get instance details gcloud beta memcache instances describe df-cache --region=us-west1
Note:
Other than the default, VPC is used for the memcached instance. Be aware that the network has to be authorized to access the cached instance.
TUNING THE EXECUTION SCRIPT
Now let’s tune our execution script. Open the file df_cache_run.sh in the root directory and change the following parameters:
| Param |
Description |
| subnetwork | Name of the subnet used for running worker nodes. If you created a new VPC with subnets, replace it with that reference. |
| serviceAccount | Replace it with the service account that was created and has the required permissions for running the sample code. |
| project | The GCP project ID. |
| stagingLocation | Set the bucket name used by dataflow for staging files. |
| tempLocation | Set the bucket name used by dataflow for temp files. The same bucket for the staging location can be used. |
| subscription | Pubsub subscription reference from where the job will read messages. |
| dataBucket | Bucket where output data will be written. |
| cacheEndpoint | Host and port of the cache instance. |
| cacheTTL | TTL of the cached service response. |
| weatherApiKey | Generated API key from OpenWeather site. |
| Region | Region where the job should run. |
There are more parameters in the script, but those are standard to any Dataflow job.
Notice that I’m not using auto-scaling: I want to replicate the scenario where more than one worker is accessing the cache. In this sample, I’m not grouping the messages by any criteria, so while different workers may handle messages for the same city, it should leverage what was cached and not ask the API the data for the same city twice.
EXECUTING THE JOB
Once the settings were changed in the script, let’s run it and wait for the job to be running.
./df_cache_run.sh
If everything went OK, we will see a successful message at the end indicating that we were able to submit the job:

The next step is to check if the job is running, which we can do from the Google Cloud console or by command line. From the console, the status of the job can be observed by accessing the Jobs options in the Dataflow menu:
PUBLISHING MESSAGES
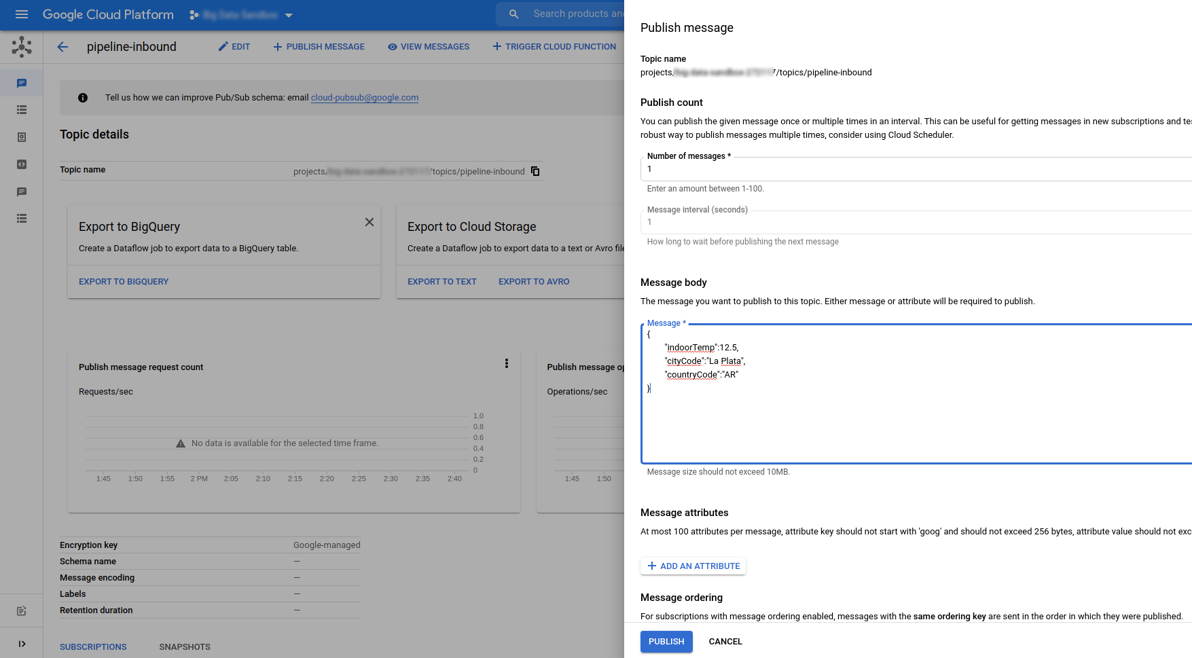
Once the job is running, we are ready to send our first message and see if the cache is working.
From the Pubsub topic that was created for running the sample in the Google Cloud Console, publish a message with the following JSON payload:
JOB COUNTERS
The first time it will fetch the data from the API (if the city and country combination is valid) and cache the result. To validate this, I’ve added counters that will provide that information. This information is available in the Dataflow job page along with other parametrization used by the job:
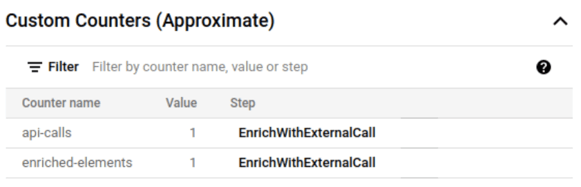
This tells that one API call was done and one element was enriched. If we send the message multiple times for the same city and country combination, we will see that just the enriched elements counter increases.
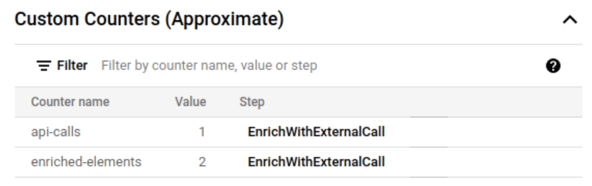
The elements are cached by one minute as it was specified in the parameters, so if we repeat the message, we will see that the API calls counter increased after one minute.
THINGS TO NOTICE
There are still a few things to tune in this example. The first is that we are not dealing with race conditions on multiple threads or workers, which means that more than one API call can be done for the same city and country combination until one of the threads sets the corresponding key in the cache.
For instance, if we trigger a massive amount of messages in a short period of time for a city that is not cached, multiple threads might try to get the value for the city and cache it:
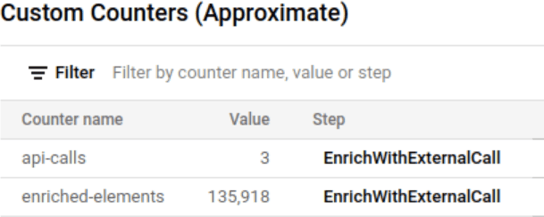
The second thing is that we are not throttling the API calls—if there is a quota limit, we still could hit it, especially if there are more cities than requests per seconds allowed. To mitigate the problem using this approach, we could adjust the windowing function and use a trigger based on time or element count while grouping the messages by city during that window. As a consequence, though, we would be adding latency to the processing time of the events.
The third and final thing is that I’m not providing any error handling in the pipeline. That’s out of the scope of the post, so be aware that any failure will prevent the event from processing.
STATELESS CACHING JOB CODE
The code for the pipeline is very simple, which shows how powerful the beam model is:
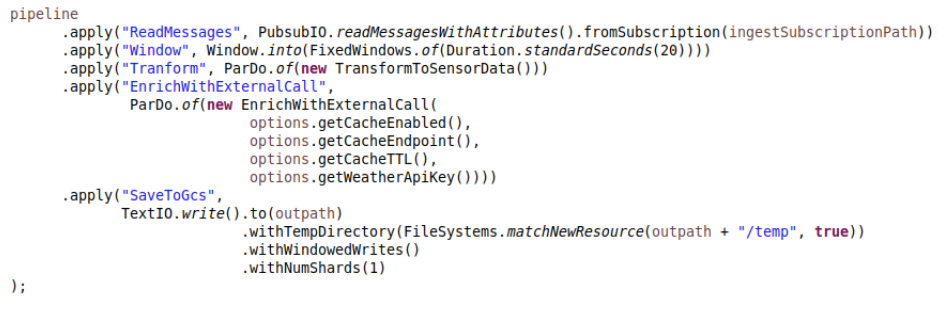
At this point, we can delete the Memorystore instance and stop the Dataflow job, thus saving costs from the Google Cloud console.
Sample job with stateful processing
Next I’ll explore an option for avoiding quota limits with stateful processing. The strategy groups elements to enrich under a given key. Once we have a determined quantity of elements to query or a given time range passed, we make the API calls for those elements.
If we make a few adjustments to the work done for the previous pipeline, we transform the pipeline into a stateful one:
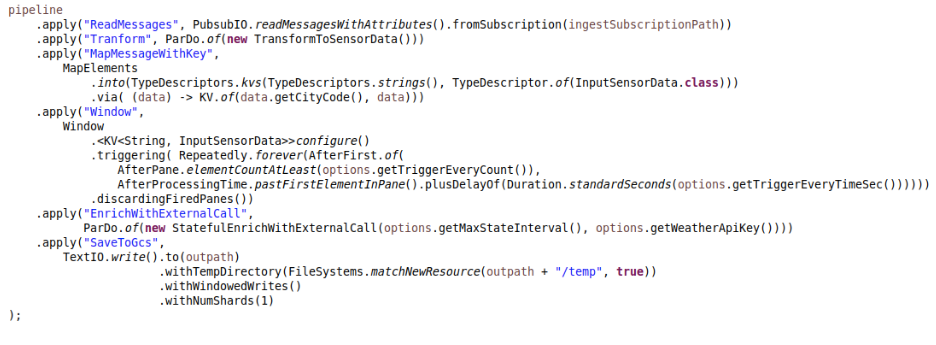
In the DoFn, we have to add the state declarations and the timer for invalidating the cache (otherwise we might be using stale data):
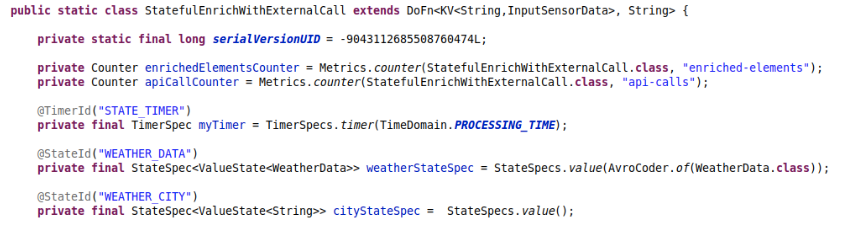
Then on the processElement, we need to reference the state and the timer and set the corresponding timeout:
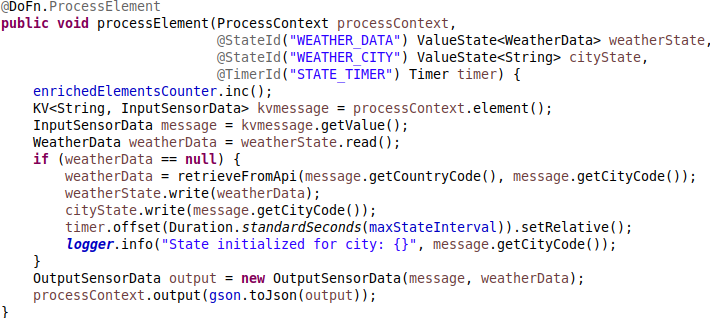
Finally, we clean the cache after the time elapsed:

TUNING THE EXECUTION SCRIPT
Now let’s tune the other execution script. Open the file df_stateful_run.sh in the root directory and change the following parameters:
| Param |
Description |
| subnetwork | Name of the subnet used for running worker nodes. If you created a new VPC with subnets, replace it with that reference. |
| serviceAccount | Replace it with the service account that was created and has the required permissions for running the sample code. |
| project | The GCP project ID. |
| stagingLocation | Set the bucket name used by dataflow for staging files. |
| tempLocation | Set the bucket name used by dataflow for temp files. The same bucket for staging location can be used. |
| subscription | Pubsub subscription reference from where the job will read messages. |
| dataBucket | Bucket where output data will be written. |
| maxStateInterval | Maximum time in MS that objects are kept in storage before performing external service invocation. |
| triggerEveryCount | Minimum number of elements to buffer before trigger processing. |
| triggerEveryTimeSec | Time elapsed before triggering processing in seconds. |
| weatherApiKey | Generated API key from OpenWeather site. |
| Region | Region where the job should run. |
EXECUTING THE JOB
Let’s run the new job using the new settings:
./df_stateful_run.sh
Like in the previous job, we will see a successful message indicating that the job was submitted if everything worked.
Now let’s proceed in the same way as before. Wait for the job to become ready and publish the messages in the topic. We can try with more cities:
{
"indoorTemp":-5,
"cityCode":"Ottawa",
"countryCode":"CA"
}
{
"indoorTemp":0,
"cityCode":"New York",
"countryCode":"US"
}
At the same time, check the worker logs to see how the state is saved and cleaned after the time elapsed:
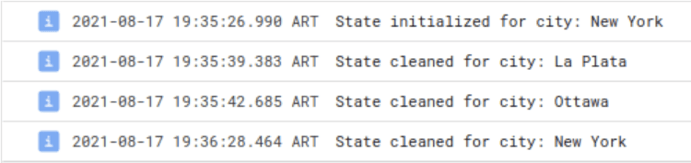
Finally, check the counters to verify how many times the API was invoked and how many elements were enriched.
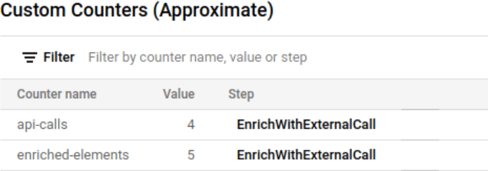
This option does not suffer the race conditions of the previous design because the grouping takes place per key and window, which is at the level the state is segregated. If we can support a little bit more latency, this option will outperform the first one in terms of avoiding quota limits.
SOURCE CODE
All the source code was shared on Github; feel free to experiment with it. I’m also including some tests for DoFn verification and a simple class that can be used for publishing events massively, in case you would like to make a more intensive test. The project uses Maven, so it would be easy to adapt it to other needs and build and deploy it.
That’s all folks! I hope you found this exercise interesting and useful.

