
Introduction
In my travels to visit many customers over the last few years, I often see my customers creating many or all of their MySQL InnoDB tables using auto-increment primary keys. Many Object Relational Mappers do this by default on behalf of the user. Once the tables are all created with auto increment primary keys, then the database designer/developer goes about assigning alternate keys that they will actually use to access the data. Most of the time the auto-increment key is simply there to ensure that there is a unique key on the table and it's often not used as an access path. This is a common design pattern, but is it the best way to create tables using MySQL? I am witting this blog to present the case that it’s a pretty bad idea most of the time.Why it’s a bad Idea
There are four reasons why, which I will explain in some depth later in the post but for now, they are:- Auto increment keys used indiscriminately are a waste of the primary key access which is always the fastest way to get to a row in a table.
- Auto increment locks can and do impact concurrency and scalability of your database.
- In an HA replication environment using standard Async Replication, auto increment risks orphan rows during a master failure event.
- If you are lucky enough to need to scale writes beyond a single server and end up having to shard auto increment no longer produces unique keys.
What are the alternatives
What can I use instead you might ask? Well, there are a few good answers to that as well.- Use UUID instead. It's larger, uglier and even more meaningless looking than an auto increment key, but it avoids most, if not all, of the issues above.
- My favorite, is to use a natural key. This is not always possible, but I often see tables with an auto increment primary key and then one or more unique secondary indexes. In this case, you simply replace the auto- increment key with your choice of already existing unique keys.
- Use a custom roll your own custom key generator. This is probably worthy of a lengthy blog all on its own.
The problem cases in a bit more depth
The waste of a primary key
MySQL InnoDB stores tables store the table data as part of the primary key’s B-Tree. Storing data this way makes access by primary key fast it also helps to keep the table well organized during inserts and deletes minimizing the impact of fragmentation over time. What this means is when access is made by a secondary index, first the secondary index B-Tree must be traversed and then the primary key index must be traversed. In addition, when the primary index is not used for access just to ensure uniqueness, there is the additional cost for maintaining a secondary index which could be the primary key index. As a result, it will take 2x additional work to access rows via secondary key, extra writes to maintain an additional B-Tree and InnoDB buffer pool space consumed by an additional B-Tree. [caption id="attachment_103606" align="alignnone" width="1201"]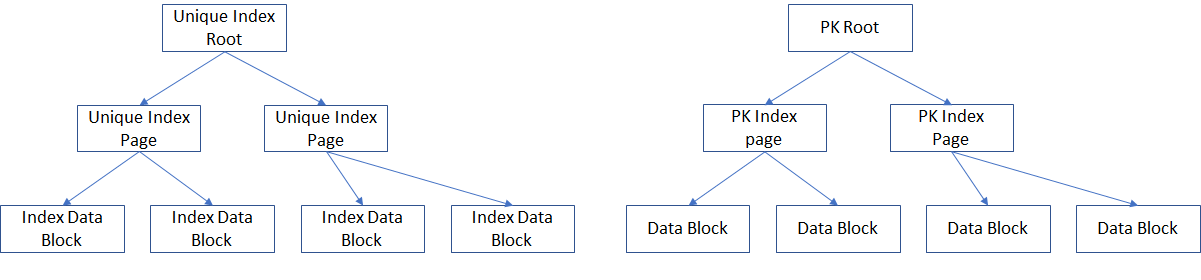 Unique secondary index with primary key in InnnoDB[/caption]
Unique secondary index with primary key in InnnoDB[/caption]
Auto-increment locks
When an insert is performed on a table with an auto increment key table level lock is placed on the table for inserts only until the transaction in which the insert is performed commits. When auto-commit is on, this lock lasts for a very short time. If the application is using manual commits, the lock will be maintained for a longer period. In some cases, I have seen this lock result in deadlocks when two or more transactions insert into multiple tables in differing order. Always a bad idea, but the very low granularity of auto-increment locks causes this to be especially problematic.Replication orphans
Standard MySQL replication is asynchronous by default this allows the master and slave to become disconnected without impacting the master’s operations. It also can result in updates to the master which are not replicated to the slave when the master fails. In a situation like this failing over to the slave will result in new rows going into auto increment tables using the same increment values used by the previous master. If the tables are using a method to generate primary keys other than auto-increment, when the original master becomes available the missing operations from the original master Binlog can be played against the new master with minimal risk. If auto-increment is used the Binlog entries will not be able to be used without modification. Note if Statement mode replication was used this issue is avoided, but there are bunch of other reasons why you really shouldn’t be using statement mode replication anymore.Lost uniqueness when sharding
If you get to the enviable point where you need to shard your database because you have just too much traffic going to your database for it to scale any further without sharding it, you will quickly find that the unique keys you get from auto-increment aren’t unique anymore. This causes problems when you want to merge shard data for analytics or if you need to recombine sharded data for any other reason, the no longer unique auto-increment primary keys get in the way.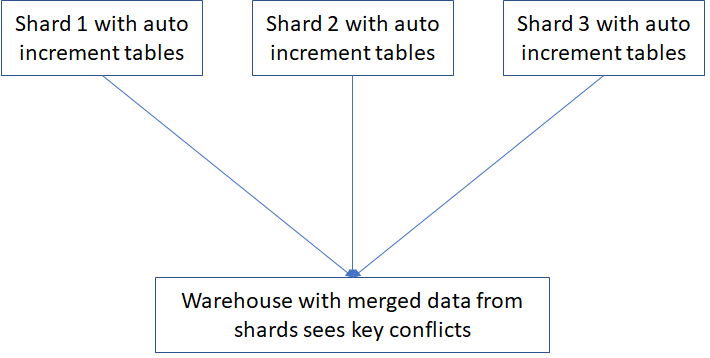
Primary Key Alternatives
Once it becomes apparent that auto-increment, as implemented in InnoDB, is not necessarily the great idea it once appeared to be, the question becomes what are the alternatives? I’ll offer four options here.Natural Key
By far and away the best choice is to use a natural key. By that, I mean one that has meaning outside of the database itself. Examples of Natural keys are National Identity numbers, State or Province identity number, timestamp, postal address, phone number, email address etc. These are generally already unique and have the advantage that they are already likely to have been used as secondary indexes anyway when you were creating your table with auto-increment primary keys. If you just simply use the existing Natural key as your primary key, you improve access to the table by that key and eliminate the cost of maintaining an extra index while avoiding the consequences of all of the problems I have already described.Modified Natural Key
In the case of a modified natural key, you have a natural key which you are fairly sure is mostly unique, but maybe not always. Maybe occasionally you will run into cases where it's not really going to be unique. The most common case is when you want to use a timestamp. Even if you make your timestamp down to the nanosecond there is always a small chance you will have two different processes attempting to insert into the same table with the same timestamp. By making your primary key a compound key with a small byte sized counter on the end, you can add duplicates by incrementing the small counter if an insert fails. If it fails again rinse and repeat. This only works when most of the time the natural key is fully unique.UUID
The use of a UUID (Universally Unique Identifier) has become popular in recent years as an alternative to auto- increment keys. See: https://en.wikipedia.org/wiki/Universally_unique_identifier UUIDs have the advantage of being unique much like auto-increment keys but they do not require table locks and they are unique within the constraints of their construction which often includes the generators MAC address, a timestamp and a unique value much like the kinds of value generated by the modified natural key approach above. To save space and minimize the impact on index block consumption UUIDs should be stored as binary(16) values instead of the Char(36) form they are usually seen. If insertion order is significant the bytes of a Type 1 UUID should be re-ordered as described here: https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/Custom Key generator
Finally you can go to a custom key generator. Custom key generators like UUIDs can produce universally unique keys with specific characteristics. I am not going to go into a lot of detail here but here are some examples of such generators:- Twitter snowflake: https://github.com/twitter/snowflake or https://github.com/RobThree/IdGen
- Icicle: https://github.com/intenthq/icicle


