When I started learning Cassandra, I noticed some concepts were not well explained, and it might be helpful for beginners to have information on a single topic in one place. This is how the idea of this blog was born. In it, I will go through what Cassandra’s consistency levels are, what options it has, and explain how they work so you can configure your database properly.
What is consistency level?
In Cassandra, a consistency level is the number of replicas responding before returning a reply to a user. Consistency in Cassandra is tunable, meaning that each client can consider what level of consistency and availability to choose. Moreover, it is assigned at the query level and can be configured for different service components. Users can choose different consistency levels for each operation, both for reads and writes. While choosing the consistency level for your operation, you should understand each level’s tradeoff between consistency and availability. Cassandra’s consistency can be strong or weak, depending on your chosen level.
The strong consistency formula is R+W>RF, where R = consistency for reads, W = consistency for writes, and RF = Replication Factor. If R+W<RF, consistency is considered weak.
As per Brewer’s theorem (also known as CAP theorem), Cassandra is, by default, located in the AP sector, which means it provides high availability and partition tolerance. But choosing, for example, Consistency Level = ALL (we will talk about it in detail later) will provide strong consistency, reducing availability, which will then move our cluster to the CP sector, which means that our cluster is consistent and partition tolerant. You should remember that Cassandra’s advantage is that it provides a lot of useful properties for availability, meaning that even if some of the nodes are down, a well-configured Cassandra cluster continues to work usually, which is a key feature of this database. Cassandra is generally recommended with some availability, as it was built for this need. Now, let’s proceed to an example that can better describe the Consistency Level. Imagine that you have a 4-node cluster within the same data center with a replication factor (RF) = 3 and consistency level (CL) = QUORUM. Data will be replicated to 3 nodes when a user inserts data (see p.1).
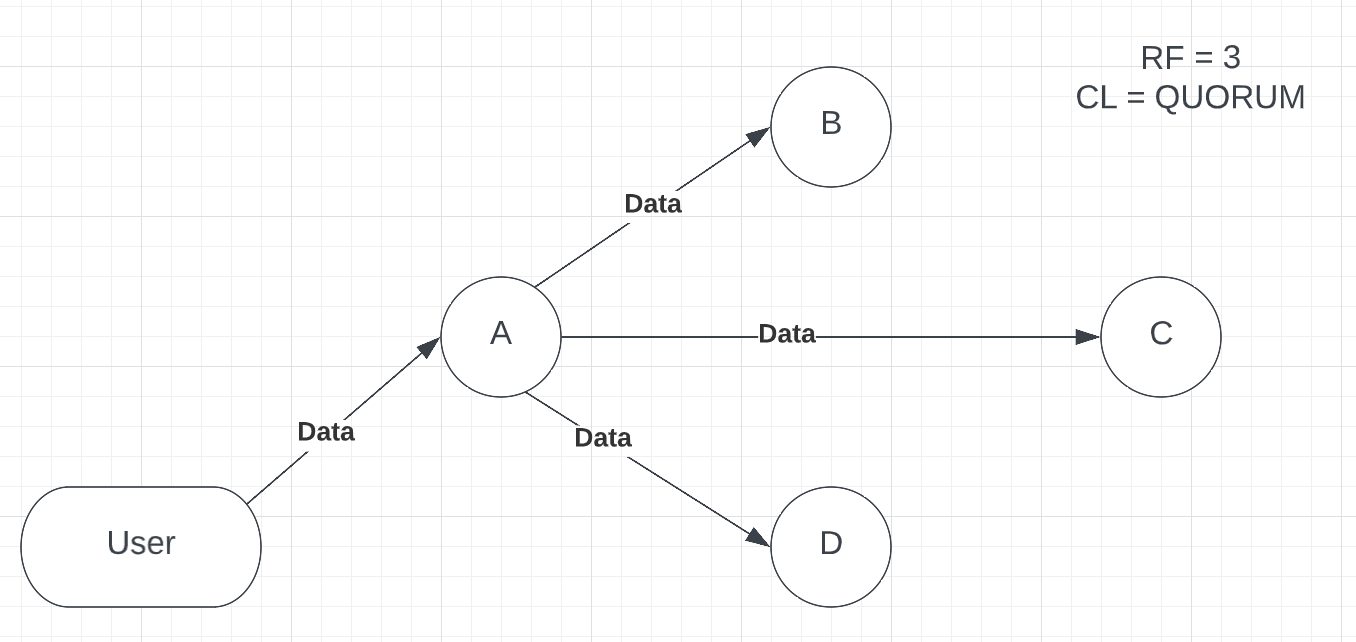 Picture 1 – inserting data into the Cassandra cluster
Picture 1 – inserting data into the Cassandra cluster
In this example, A is our Coordinator node, which receives data from the user input. As the replication factor is 3, data has been sent to nodes B, C and D, where it will be stored. Once data is stored, the replica node should respond to the coordinator node that the request has been successfully completed. In our example, when CL = QUORUM, 2 out of 3 replicas should acknowledge the request completion because, on QUORUM level, at least 51% of replicas should reply for an operation to succeed. Moreover, QUORUM is calculated as: (number of replicas / 2) + 1. Let’s assume that replicas B and C responded first (see p.2).
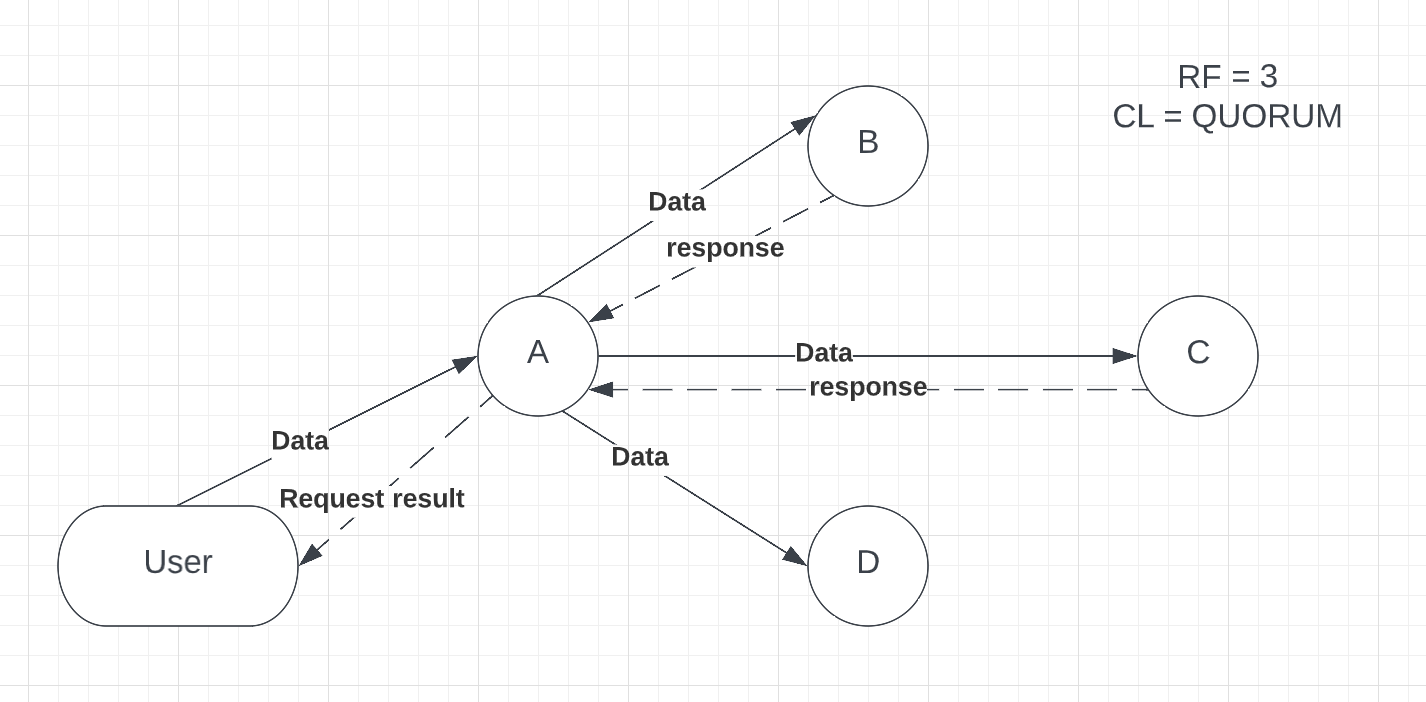
Picture 2 – Coordinator node (A) receives a response from nodes B and C, then sends the result to a user
After the replica’s response, the User will receive the result that the request succeeded. Furthermore, even if replica D fails to proceed with the request, it will not affect the result.
Now that you have a basic understanding of the Consistency Level, let’s dive deep into each available option.
CL = ALL
Consistency level = ALL provides the strongest consistency you can achieve in Cassandra. It will require each and every replica to send a response. Even if you have replicated your data to hundreds of nodes all over the globe, the request will not succeed if at least one replica fails to send a response (see p.3). NOTE: There is only ALL consistency in Cassandra; LOCAL_ALL is not provided
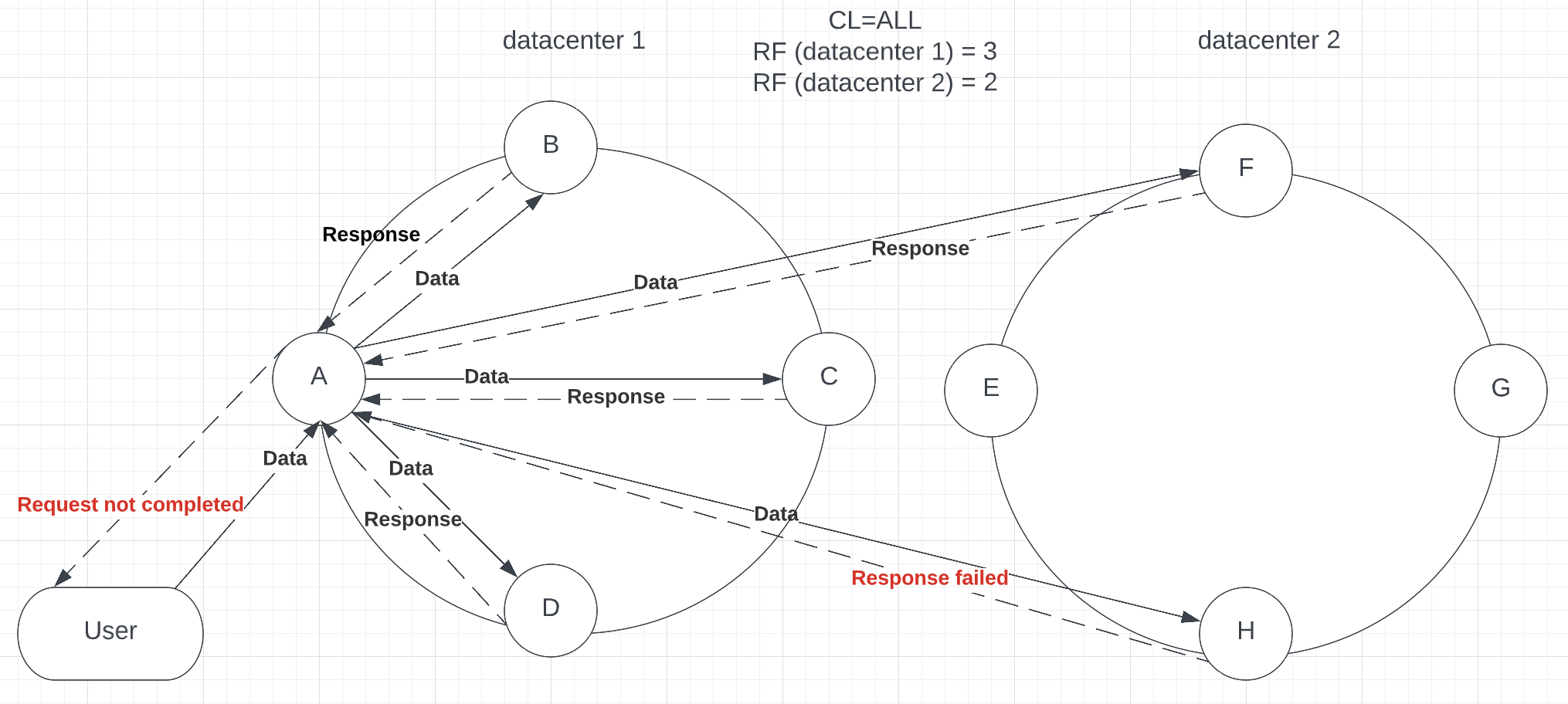
Picture 3 – Node H failed to respond, which caused the request failure
Of course, it improves consistency, but Cassandra’s main purpose is availability, as it has features such as hinted handoff (to be discussed in a future blog post), that even when a replica is down, the coordinator node stores a hint that helps to insert newest data after node return online. While setting this consistency level, your cluster is located in the CP part of the CAP theorem, which is not a proper use of Cassandra, as it sacrifices availability and performance. Your data centers might be spread across different continents all over the World, and it may take a long for the response, while the key feature of Cassandra is high availability. If you want your data to be fully consistent rather than available, use a relational database, as it provides solutions for your needs, while Cassandra specializes in data availability.
CL = EACH_QUORUM
Moving forward to the 2nd strongest consistency level Cassandra can propose – EACH_QUORUM. This level requires a majority of nodes in each data center to respond with success to complete a request (see p.4).
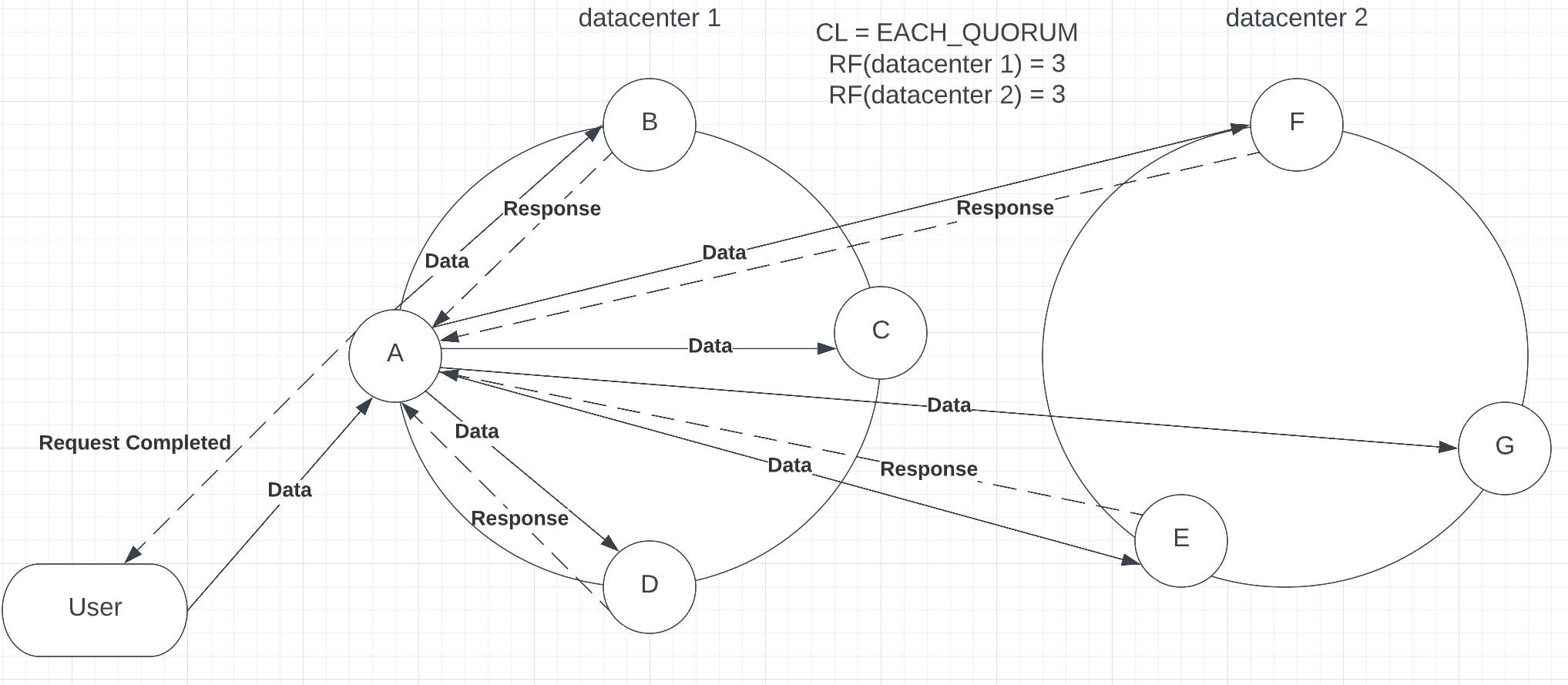
Picture 4 – Completed response with EACH_QUORUM consistency
As you can see from the provided example, the request has been sent to 6 nodes across 2 datacenters, and the coordinator node received a response from most nodes. Compared with ALL, this request is less consistent. Nevertheless, it provides a larger availability level, as not all nodes need to respond for the request to proceed. It is still highly latent, requiring another data center to participate. Access to another data center reduces the performance of the request. Moreover, when you decide to replicate a keyspace across more data centers, EACH_QUORUM will require more responses to complete the request, which may increase latency and reduce performance.
CL = QUORUM
The Consistency Level of Quorum requires a response from most replicas across a cluster. QUORUM provides strong consistency. For example, if you have 7 nodes, with RF = 4, the coordinator will ask for at least 3 nodes to send a successful response to complete the operation (see p.5).
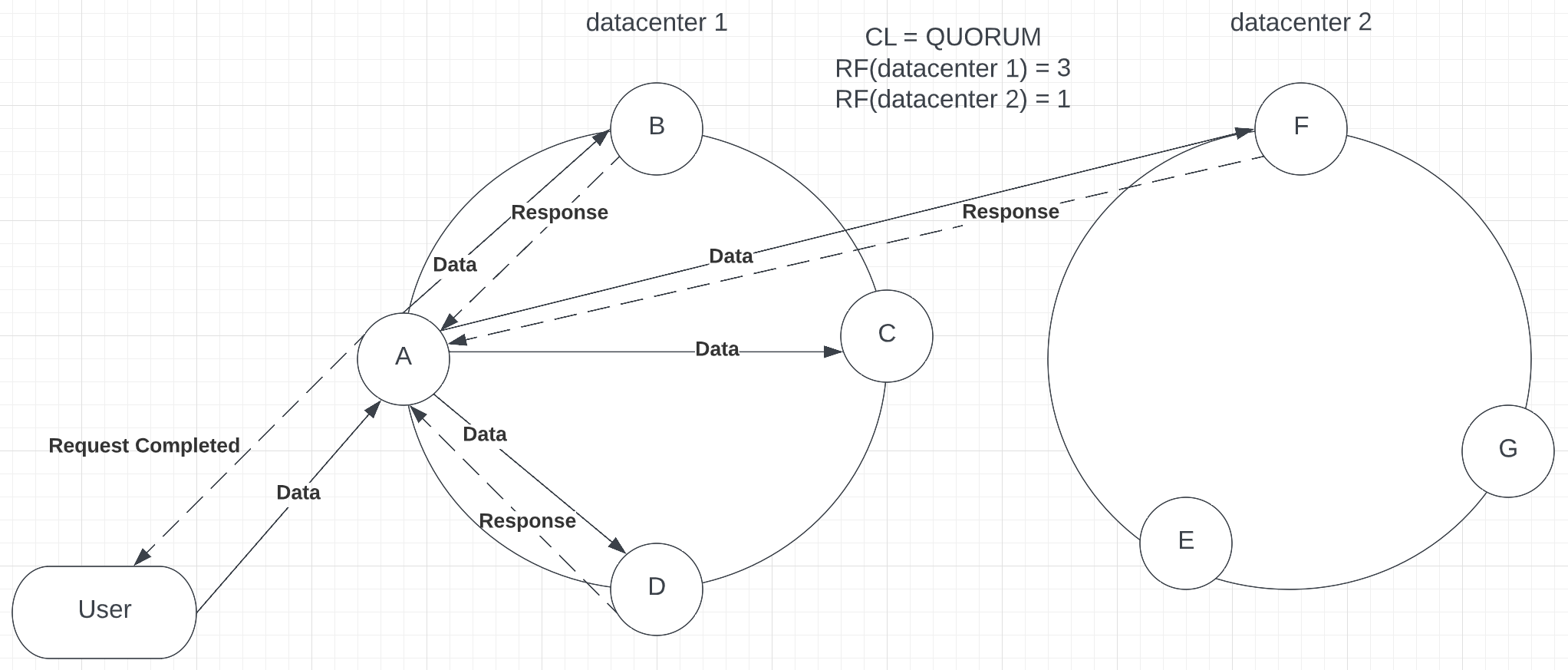
Picture 5 – Completed request with QUORUM consistency
One of the advantages of QUORUM is that even if replica C doesn’t send a response, the coordinator node can send a request to node F, located in a different data center. The difference between QUORUM and EACH_QUORUM is that in QUORUM the majority of replicas in the cluster need to respond, while EACH_QUORUM requires the majority of replicas IN EACH DATACENTER to reply. Because of that, the QUORUM level provides more availability than EACH_QUORUM and keeps strong consistency. On the other hand, it might require access to another data center, which, as we have mentioned above, can be highly latent. QUORUM is recommended in the properly configured cluster when the request will not leave the current data center.
CL = LOCAL_QUORUM
LOCAL_QUORUM still requires most replicas to respond, but only within the data center where the request has been taken (see p.6).
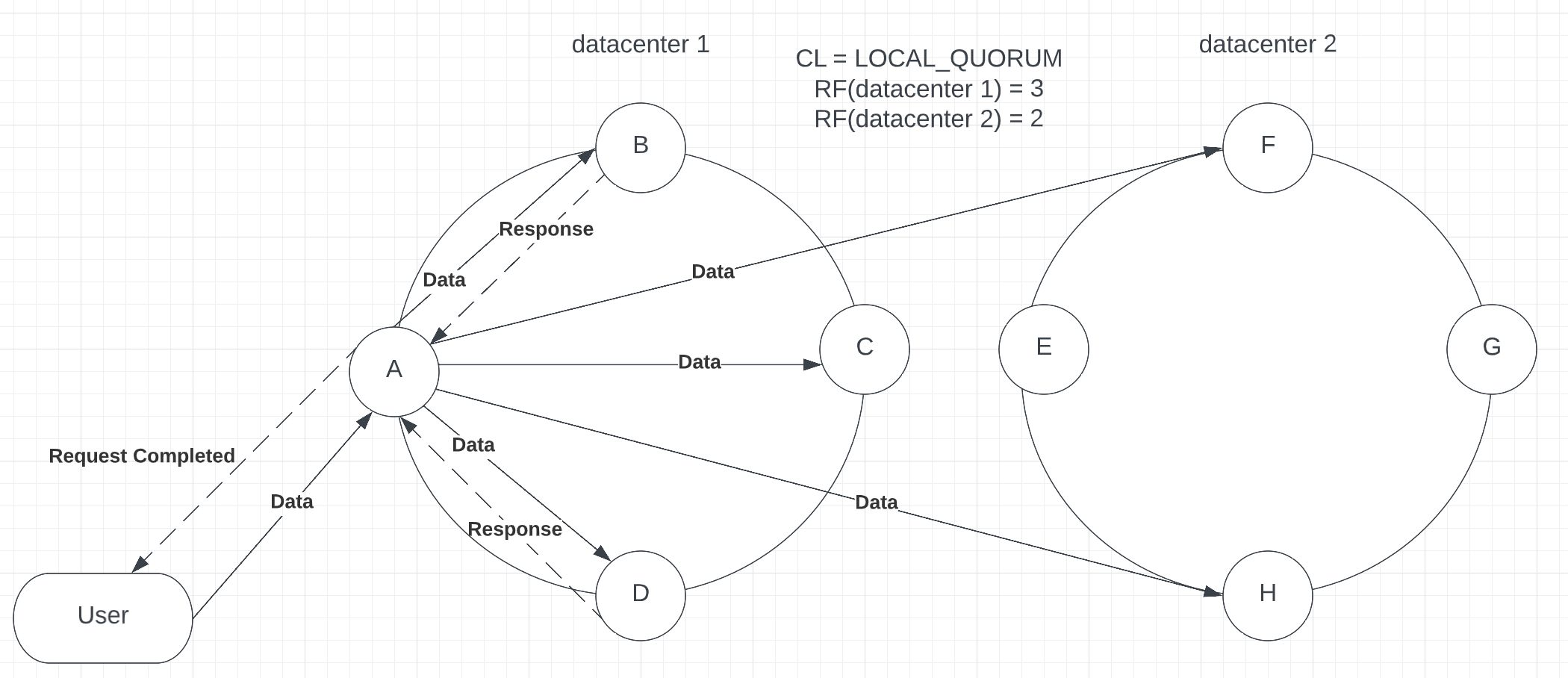
Picture 6 – Usage of LOCAL_QUORUM with multiple datacenters
Although LOCAL_QUORUM requires only local replicas to reply, it remains strongly consistent, as Cassandra features such as hints and read repairs keep data in sync. With LOCAL_QUORUM, the cluster is in the golden mean between availability and consistency, as it keeps data up-to-date. Also, it lowers latency, as the request doesn’t leave the borders of the current data center. This level is generally recommended for most production environments.
CL = numeric value
You can also use numeric values to provide consistency level. With the numeric values, consistency can be either strong or weak, depending on your chosen value and the number of replicas in the cluster. Only ONE, TWO, and THREE values can be applied. Otherwise, you will receive an error “Improver Consistency Command.” Let’s create a scenario when you have 4 nodes with RF = 3 and CL = 2 (see p.7.1). Then, the project manager decided to increase the number of nodes as the company grew and the data flow increased. Now, you have 7 nodes with RF = 5, keeping the same consistency (see p.7.2).
NOTE: Changing the replication factor is not recommended after release, only while adding a new data center. Please configure your data center’s replication factor before the public reveal. An example below is provided for a better understanding of the topic.
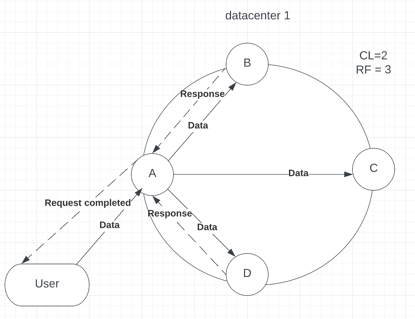
Picture 7.1 usage of CL = 2 within a small data center with 3 replicas
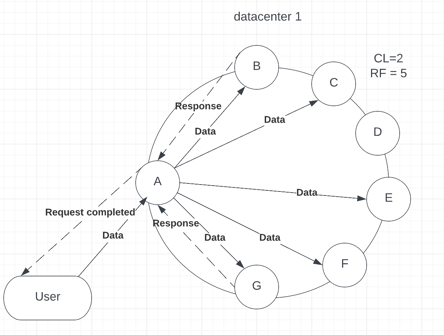
Picture 7.2 – usage of CL = 2 within a larger data center with 5 replicas
As you can see from the above example, increasing the number of replicas leads to lower consistency. The advantage of this consistency level is that you can select the constant number of replicas to respond to if compared with QUORUM, where the number will change depending on the number of replicas. On the other hand, this consistency is not flexible compared with QUORUM or LOCAL_QUORUM, where the number of successful replies scales automatically with the replication factor, keeping data consistent. Moreover, deploying more data centers and increasing the replication factor decreases data consistency across the cluster.
NOTE: Consistency Level number must be less or equal to the number of replicas. Otherwise, while processing a request, you will receive an error (see p.7.3):
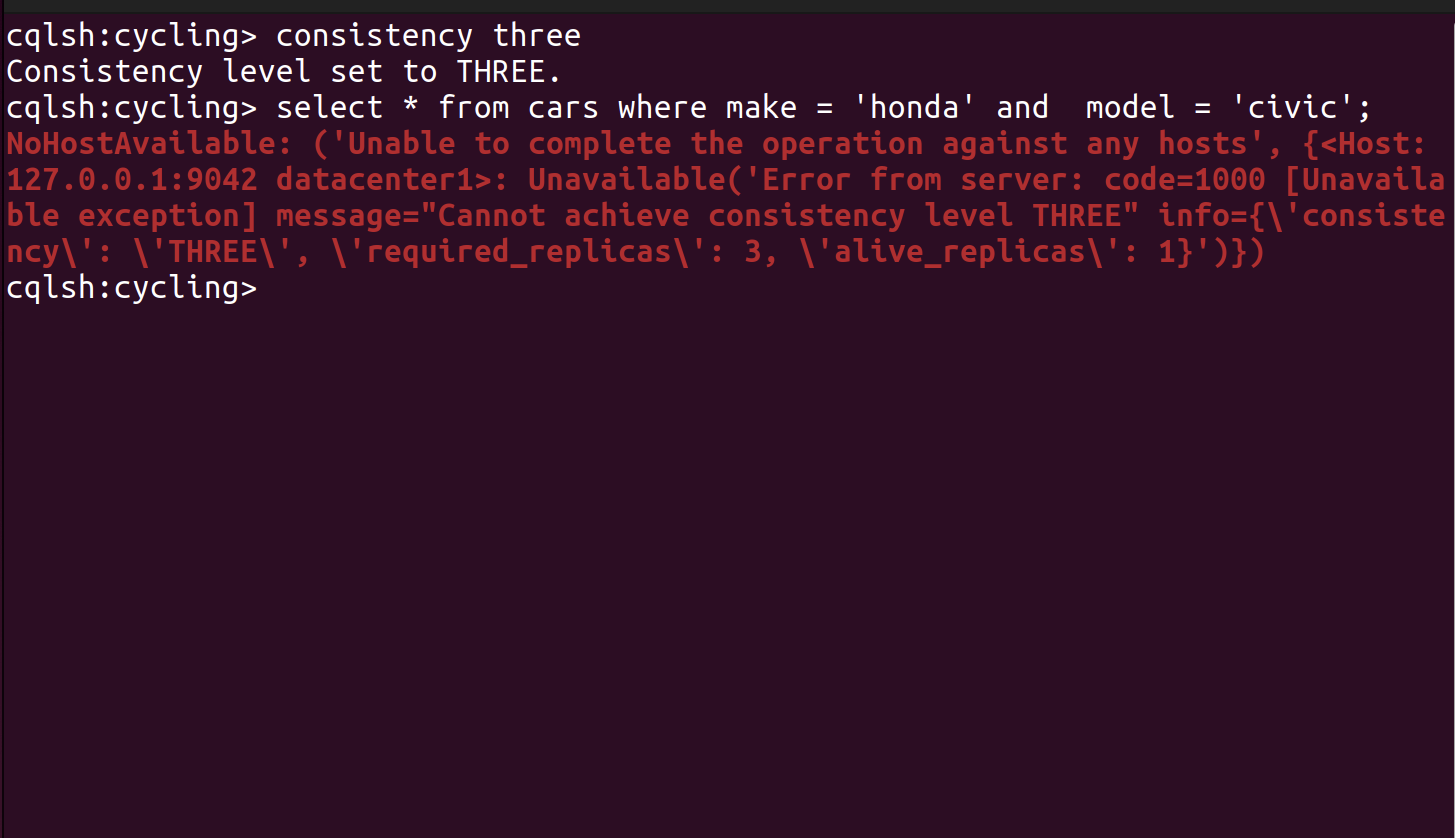 Picture 7.3 – an error occurs when the consistency level number is greater than the number of replicas
Picture 7.3 – an error occurs when the consistency level number is greater than the number of replicas
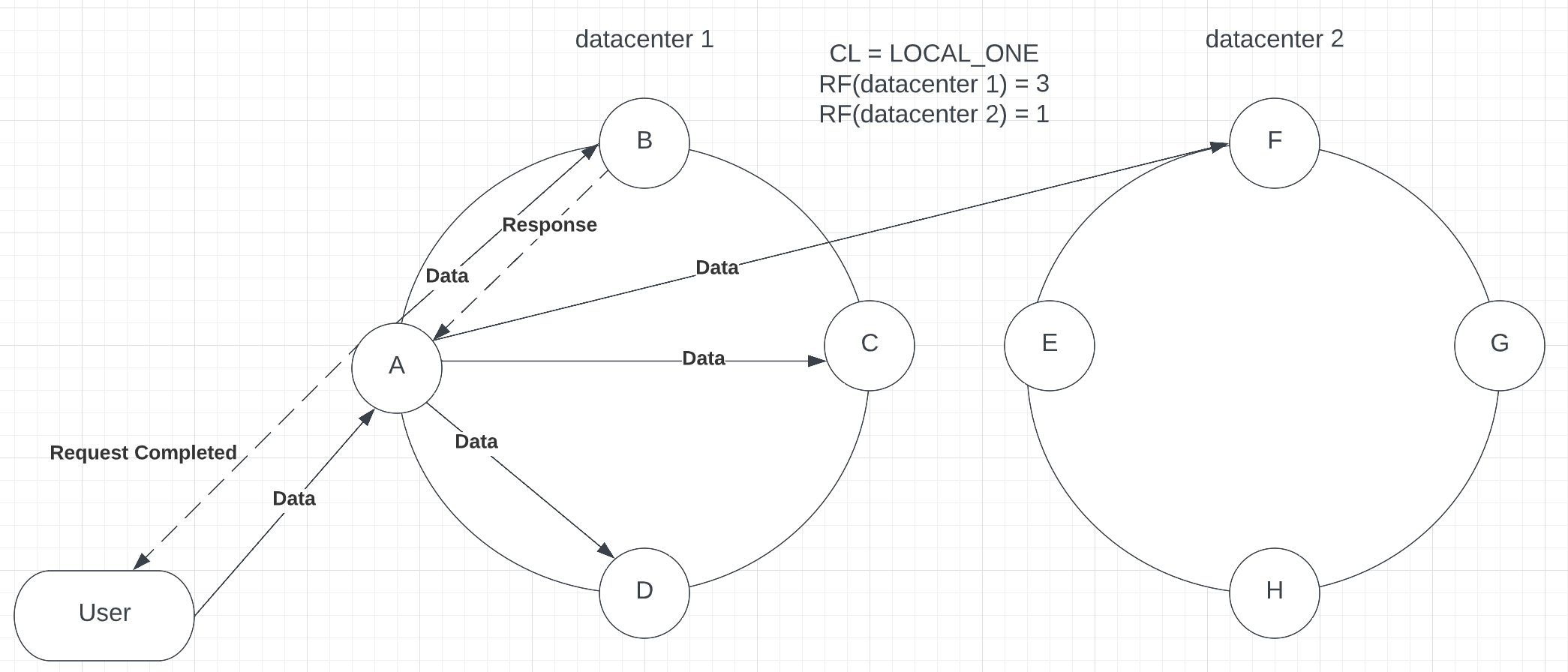
CL = LOCAL_ONE
Same as ONE but will require 1 acknowledgement within the local data center (see p.8).
Picture 8 – usage of LOCAL_ONE
As in LOCAL_QUORUM, consistency check applies only in the local data center. As it requires only one replica to reply, it reduces consistency for higher availability. A weak consistency level is recommended use with data that is not important to be consistent right away, such as the number of likes and shares on social media. NOTE: there is no LOCAL_TWO or LOCAL_THREE consistency, only LOCAL_ONE.
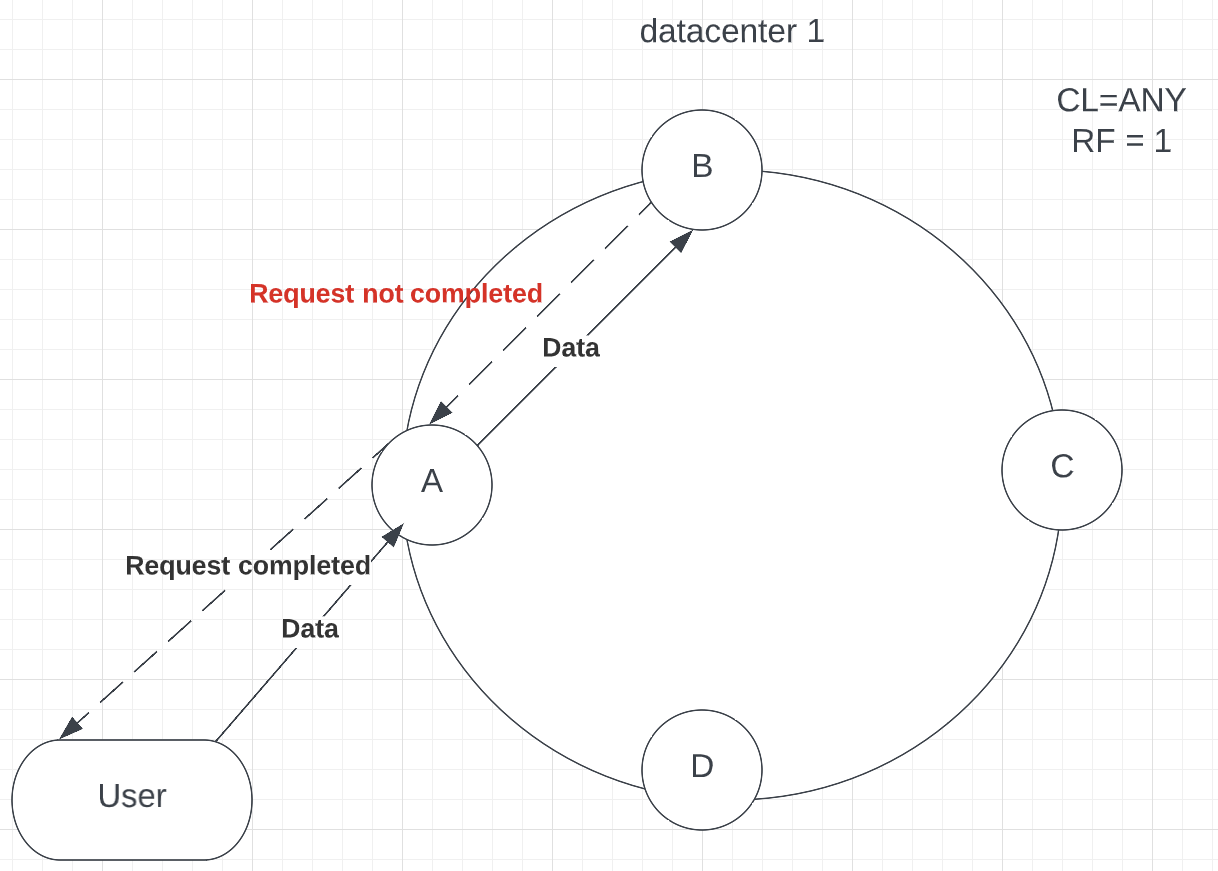
CL = ANY
Consistency level ANY can be applied with write requests only. Otherwise, the following error will be displayed (see p.9):
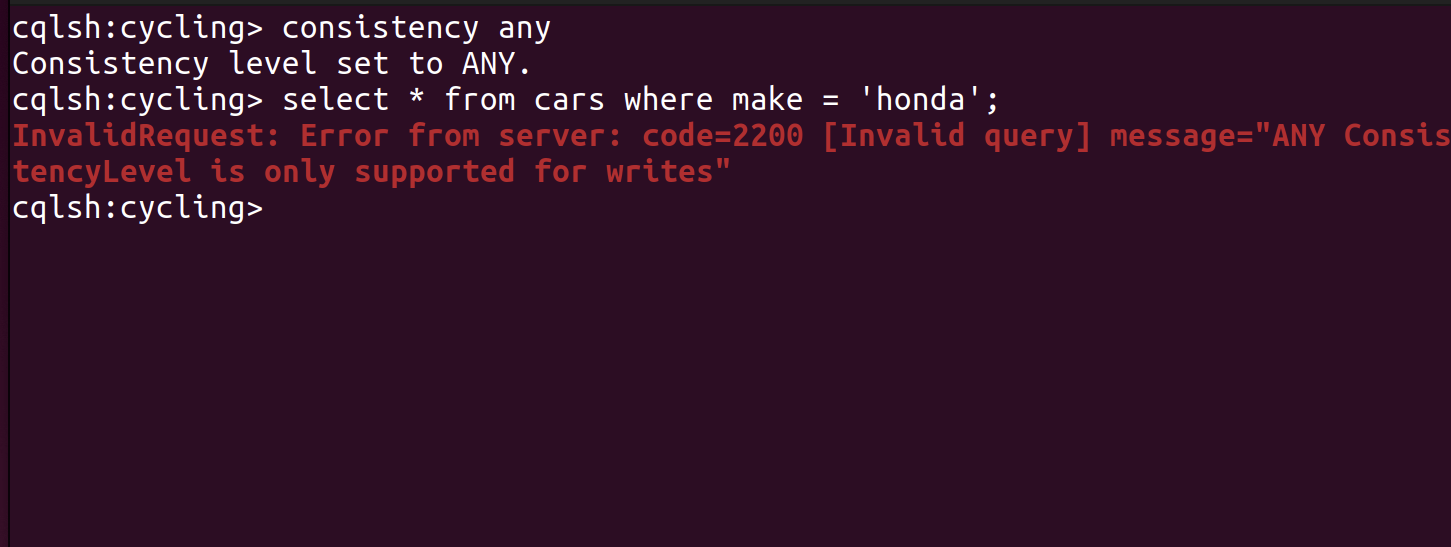 Picture 9 – an error occurs on reads with consistency level ANY
Picture 9 – an error occurs on reads with consistency level ANY
The ANY level doesn’t require a response from any of the replicas. It also is known as the consistency level, where requests can succeed without data being inserted into the database. It means that a request completion message will be sent to the User instantly, whether it succeeded or not. The coordinator node would store a hint if the replica node failed to process the data due to the outage. The default time for the hint to expire is 3 hours, meaning that the data will be lost if the replica does not come back online in that time. If all replica nodes are down at write time, ANY write is not readable until the replica node for that partition have recovered when hints are played. Here you can see the example where the replica didn’t store the data, but a request completion message has been sent back to the User (see p.10).
Picture 10 – response failed, but the User received a message that the operation has been succeeded
Consistency level ANY provides the highest availability in Cassandra, sacrificing consistency. This consistency level is not recommended in production environments as there is no guarantee for storing data, which can cause data loss.
SUMMARY
Consistency Level is a crucial Cassandra features that determine the system behaviour. A well-configured database can properly manage thousands and millions of queries per second, and consistency is essential. In this post, we have covered what Consistency Level is, how to configure it, what options it has, which are considered more consistent, and which provide higher availability.
We also discussed tradeoffs between consistency and availability for each level, which can give you a better understanding of the options and when to use them. Essential data, such as user information or product price, should be strongly consistent. They can be handled with QUORUM or LOCAL_QUORUM consistency, while product reviews can keep availability with levels ONE or LOCAL_ONE. Levels such as ALL and ANY are better to avoid in production environments, as they don’t provide needed availability or consistency and can cause performance downgrade or data loss.
Understanding each option’s level of consistency and availability is critical to developing a well-designed system that can handle vast amounts of data and high throughput of requests. After going through all the information above, I hope you will be able to do so and find an option that best suits your database.

