 In my previous post, I presented how external persistent volumes were handled by DC/OS on AWS and how persistent services would recover from a node failure. Now let's review how Kubernetes deals with similar situations, but on Google Cloud.
In my previous post, I presented how external persistent volumes were handled by DC/OS on AWS and how persistent services would recover from a node failure. Now let's review how Kubernetes deals with similar situations, but on Google Cloud.
Kubernetes on GCP in 10 mins
I used
this tutorial from Kubernetes documentation to generate a small cluster in GCP. TL;DR If you basically run the following command on your cloud shell, you should have a running cluster in about 5 minutes: [code language="bash"] gabocic@kubernetes-196513:~$ curl -sS https://get.k8s.io | bash [/code] I then installed the latest version of kubectl by downloading it from storage.googleapis.com directly. You can use
this link for more details about installing Kubernetes CLI.
A quick recap
In Part 1, I created a persistent service on DC/OS (i.e., a MySQL instance) using external persistent volumes. This means that the data was not actually stored on the node where the container was running, but on an AWS EBS volume. We also saw that upon failure, the volume would be moved and mounted transparently on the new node where the service is running. Let’s run a similar test on Kubernetes and see how it reacts.
Deploying a MySQL service
I chose to use the web GUI to interact with the cluster, so I first launched kubectl proxy from Google cloud shell and used the web preview feature to make the GUI available from my laptop. Additional details about how to do this can be found
here. For those new to Kubernetes, the
Create button on the upper right corner will allow you to create any Kubernetes resource by providing the correspondent YAML code.
To create the MySQL service, I used this example YAML:
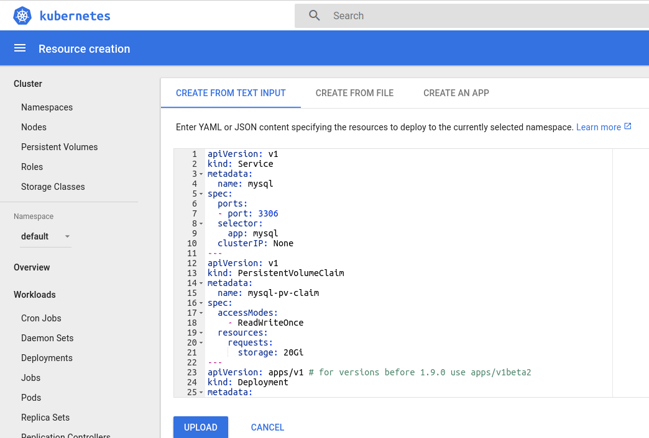 I’m not going to describe it in detail, but we are basically creating a
Deployment
for our MySQL instance, a
Persistent Volume Claim
and a
Service
to access the server. I copied the storage-related sections below so we can take a closer look:
I’m not going to describe it in detail, but we are basically creating a
Deployment
for our MySQL instance, a
Persistent Volume Claim
and a
Service
to access the server. I copied the storage-related sections below so we can take a closer look:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
From the snippet above, you can infer that we are requesting a persistent, 20Gib volume through a claim named mysql-pv-claim.
Further down the YAML text, we can see that the resultant persistent volume should be mounted on /var/lib/mysql:
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
After uploading the YAML objects description, you can now see we have our Deployment, Persistent Volume Claims and Services created and healthy.


 To see on which Kubernetes node our MySQL Docker container is running, you need to check the
mysql pod details (
kubernetes-minion-group-tj5w, in this case).
To see on which Kubernetes node our MySQL Docker container is running, you need to check the
mysql pod details (
kubernetes-minion-group-tj5w, in this case).
 To confirm the server is reachable and to create some test data, I connected to the instance using the kubectl syntax below. This will create a temporary pod running the MySQL client: [code language="bash"] gabocic@kubernetes-196513:~$ ./kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword [/code]
Now let’s see what happens when
kubernetes-minion-group-tj5w is stopped from the GCP console. As one would expect, all mysql components are marked as unhealthy, but the pod was not migrated to a healthy node. Why? Same as with DC/OS on AWS, Kubernetes nodes were created as part of an instance group, and stopping them would trigger a healing operation. To prevent this, I disabled autoscaling for the correspondent instance group and shut down the instance again. If you are wondering if the disk can be detached from a stopped machine, the answer is no, it can't. So I had to destroy the instance to allow the service migration to complete successfully. You can see on the screenshots below that after recovery, mysql is running on node
kubernetes-minion-group-tvf9 and that the persistent volume created for the service is also attached to this node.
To confirm the server is reachable and to create some test data, I connected to the instance using the kubectl syntax below. This will create a temporary pod running the MySQL client: [code language="bash"] gabocic@kubernetes-196513:~$ ./kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword [/code]
Now let’s see what happens when
kubernetes-minion-group-tj5w is stopped from the GCP console. As one would expect, all mysql components are marked as unhealthy, but the pod was not migrated to a healthy node. Why? Same as with DC/OS on AWS, Kubernetes nodes were created as part of an instance group, and stopping them would trigger a healing operation. To prevent this, I disabled autoscaling for the correspondent instance group and shut down the instance again. If you are wondering if the disk can be detached from a stopped machine, the answer is no, it can't. So I had to destroy the instance to allow the service migration to complete successfully. You can see on the screenshots below that after recovery, mysql is running on node
kubernetes-minion-group-tvf9 and that the persistent volume created for the service is also attached to this node.


Storage provisioner
When we queried the container mount metadata on DC/OS, we observed that it was using the REXRay driver. Doing the same for Kubernetes will show us that the volume was made available through a "bind" mount, pointing to a path in the local filesystem. How did our GCE volume make it to the node and how was it presented to the container? If we check our volume on the "Persistent volumes" section, you will find that there is a storage class associated with it (
Standard in this case). Going to the "Storage classes" menu in Kubernetes GUI, we can see the properties of our
Standard class. In this case, it is using the
kubernetes.io/gce-pd provisioner, which basically allows Kubernetes to manage GCE volumes. When creating a persistent volume, you can specify the class using
storageClassName. If not provided, it will default to the "default" class, which is
Standard in this case (you can check if a class is the default by checking its YAML configuration). Before a container is started on a node, the kubelet volume manager locally mounts all the volumes specified in the PodSpec under a directory for that pod on the host system. Once all the volumes are successfully mounted, it constructs the list of volume mounts to pass to the container runtime.
Conclusions
Kubernetes also provides the necessary mechanisms to transparently provision and handle external persistent volumes (GCE disks for this lab). Kubernetes will make sure that volumes associated with a service are mounted on the host and presented to the container when it is started. Unlike DC/OS, Kubernetes uses bind mounts and relies on a GCE-specific provisioner to create the volumes. Finally, it is the kubelet agent which is the one in charge of mounting the external volumes into the appropriate host.

