Data governance has become an essential agenda item for many organizations. The reasons are varied, but two of the most compelling ones are: (1) as the number of data assets grows, it becomes harder to properly control access to them; and (2) new and more stringent privacy regulations are increasing the calls for compliance. Snowflake provides a strong foundation that ensures high levels of governance on your data assets. In this post, we will showcase the main features with some examples. We assume you have some essential experience working with Snowflake and its access control features.
Governance requirements
The organizational setup in this post is inspired by an example in the Snowflake documentation but adapted to showcase data governance features. Consider an organization that keeps payroll and employee data in two separate databases: PROD_DB_FIN and PROD_DB_HR, respectively.
In this example, the data needs to be accessed by three business users and managed by a system administrator. The following diagram shows this setup:
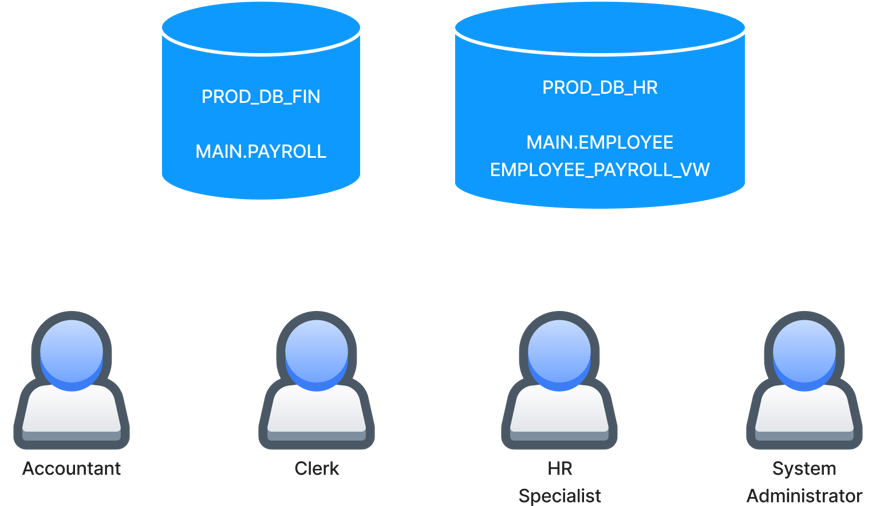
The organization needs to govern its data assets according to the following requirements:
- The accountant needs read/write access on PROD_DB_FIN to update payroll data but read-only access on PROD_DB_HR to read employee data. However, employees’ dates of birth in PROD_DB_HR should be kept private.
- The clerk helps the accountant do some administrative tasks, so she also needs access to both databases in read-only mode. Additionally, the clerk shouldn’t be able to read personal information such as date of birth in PROD_DB_HR or social insurance number (SIN) and salary in PROD_DB_FIN. The organization has employees in Canada and USA, but the clerk should have access only to the employees in Canada. The accountant takes care of the employees in the USA.
- The HR specialist needs read/write access on PROD_DB_HR to update employee data but read-only access on PROD_DB_FIN to read payroll data. Unlike the other roles, the HR specialist needs full access to personal information to perform her functions.
- The system administrator should manage both databases and implement the necessary controls to enforce the governance requirements. Only the system administrator should grant access to the databases.
Database objects
The code below shows the definition of the tables in PROD_DB_HR and PROD_DB_FIN, as well as the data that is initially loaded:
--
-- Permanent tables
--
-- SIN numbers encoded as base64 strings
CREATE OR REPLACE TABLE PROD_DB_HR.MAIN.EMPLOYEE (
EMPLOYEE_ID INTEGER,
FIRST_NAME STRING,
LAST_NAME STRING,
BIRTH_DATE DATE,
TITLE STRING,
DEPARTMENT STRING,
COUNTRY STRING,
SOCIAL_INSURANCE_NUMBER STRING
);
INSERT INTO PROD_DB_HR.MAIN.EMPLOYEE
VALUES
(1, 'Jason', 'Chapman', '1980-05-31', 'Director', 'Sales', 'Canada', 'OTk5LTk5OS05OTE='),
(2, 'Jennifer', 'Villanueva', '1996-03-14', 'Graphic Designer', 'Marketing', 'Canada', 'OTk5LTk5OS05OTI='),
(3, 'Wayne', 'Cooper', '2000-10-25', 'Software Developer', 'Product Development', 'USA', 'OTk5LTk5OS05OTM='),
(4, 'Anna', 'Thompson', '1971-06-28', 'Accountant', 'Finance', 'USA', 'OTk5LTk5OS05OTQ=');
CREATE OR REPLACE TABLE PROD_DB_FIN.MAIN.PAYROLL (
EMPLOYEE_ID INTEGER,
EFFECTIVE_DATE DATE,
SALARY_AMOUNT NUMERIC(10, 2)
);
INSERT INTO PROD_DB_FIN.MAIN.PAYROLL
VALUES
(1, '2005-01-01', 85000),
(2, '2010-05-12', 72000),
(3, '2020-03-22', 76000),
(4, '2018-08-05', 69000);
We will be querying the data in the databases using the EMPLOYEE_PAYROLL_VW view below, which simply joins the data from both tables:
--
-- Secure views
--
USE PROD_DB_HR.MAIN;
CREATE OR REPLACE SECURE VIEW EMPLOYEE_PAYROLL_VW
AS
WITH LAST_RAISE AS (
SELECT
EMPLOYEE_ID,
MAX(EFFECTIVE_DATE) AS EFFECTIVE_DATE
FROM PROD_DB_FIN.MAIN.PAYROLL
GROUP BY
1
)
SELECT
E.EMPLOYEE_ID,
E.FIRST_NAME,
E.LAST_NAME,
E.FIRST_NAME || ' ' || E.LAST_NAME AS FULL_NAME,
E.BIRTH_DATE,
E.TITLE,
E.DEPARTMENT,
E.COUNTRY,
E.SOCIAL_INSURANCE_NUMBER,
PP.SALARY_AMOUNT,
SI.EFFECTIVE_DATE AS LAST_RAISE_DATE
FROM PROD_DB_HR.MAIN.EMPLOYEE E
LEFT JOIN LAST_RAISE SI
ON E.EMPLOYEE_ID = SI.EMPLOYEE_ID
LEFT JOIN PROD_DB_FIN.MAIN.PAYROLL PP
ON E.EMPLOYEE_ID = PP.EMPLOYEE_ID
AND PP.EFFECTIVE_DATE = SI.EFFECTIVE_DATE;
Access control
The role hierarchy below implements the requirements outlined in the section above. At the top, you can find system-defined roles (green), which are created by default and come with privileges related to account management. It is not recommended to modify these roles to add entity-specific privileges. Instead, the recommended approach is to create “access roles” (blue) with the correct set of privileges on specific objects. Then, you grant these access roles to “functional roles” (yellow) based on requirements. Finally, you grant functional roles to users so that they can do their work on the databases.
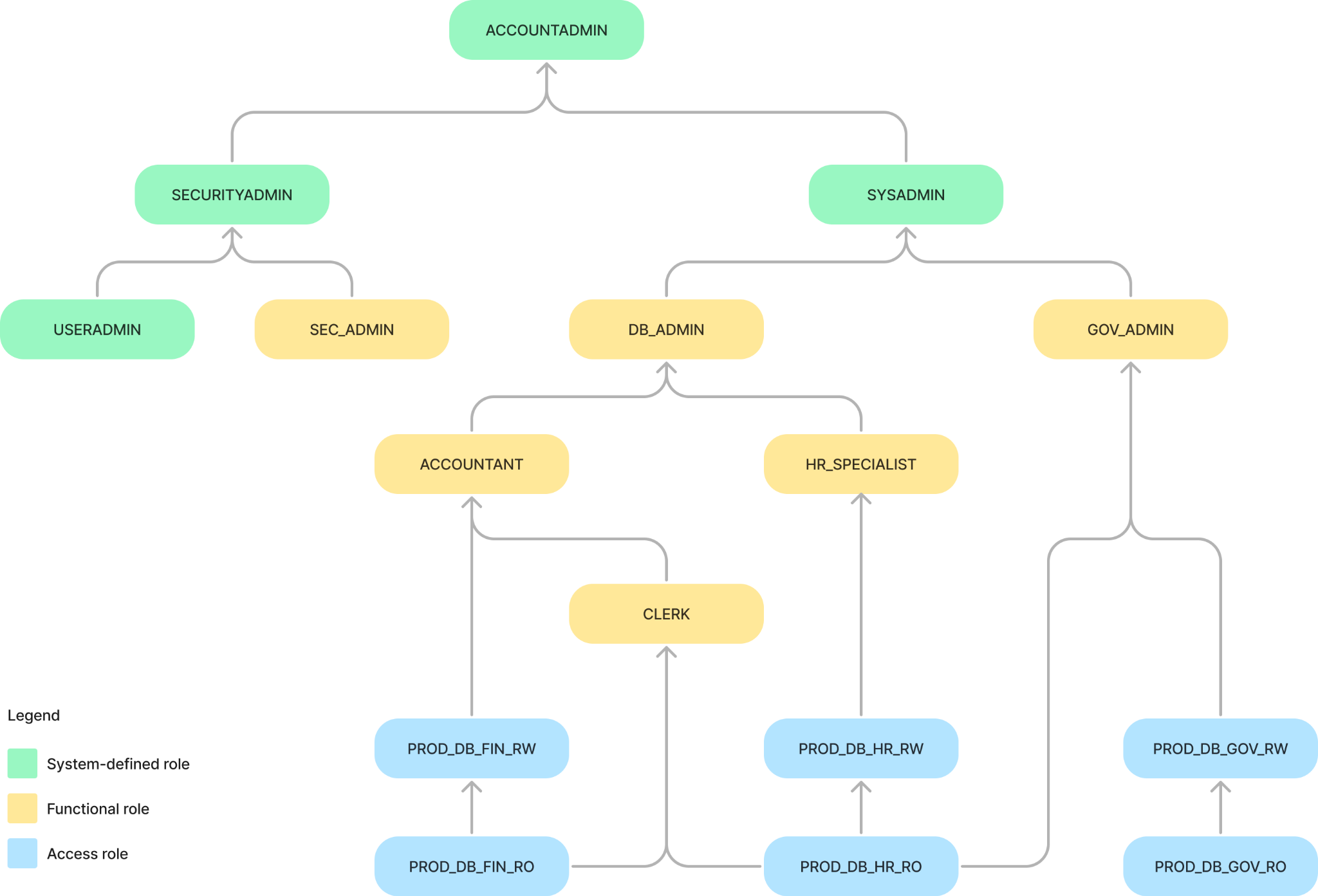
Admin roles
A user can be assigned more than one functional role, inheriting, in this way, the combined privileges of the assigned roles. For instance, in the role hierarchy, we defined the following administrative roles:
- DB_ADMIN: This role includes privileges to create database objects and virtual warehouses in the account.
- GOV_ADMIN: This role includes privileges to create tags, masking policies and row access policies in the account.
- SEC_ADMIN: This role includes privileges to grant/revoke user access roles.
As stated in the governance requirements section, this separation of roles allows database administration assignment, governance and security functions to three separate users if needed or to a single system administrator. Make sure to ultimately assign any custom role hierarchy to SYSADMIN. Otherwise, the account administrator cannot modify objects created by a custom role.
The code below shows the definition of the admin roles:
-- -- Custom admin roles -- USE ROLE SECURITYADMIN; CREATE OR REPLACE ROLE DB_ADMIN; CREATE OR REPLACE ROLE GOV_ADMIN; CREATE OR REPLACE ROLE SEC_ADMIN; GRANT ROLE DB_ADMIN, GOV_ADMIN TO ROLE SYSADMIN; GRANT ROLE SEC_ADMIN TO ROLE SECURITYADMIN; -- -- Grant privileges -- -- DB_ADMIN USE ROLE ACCOUNTADMIN; GRANT CREATE DATABASE ON ACCOUNT TO ROLE DB_ADMIN; GRANT CREATE WAREHOUSE ON ACCOUNT TO ROLE DB_ADMIN; -- GOV_ADMIN USE ROLE ACCOUNTADMIN; GRANT APPLY MASKING POLICY ON ACCOUNT TO ROLE GOV_ADMIN; GRANT APPLY ROW ACCESS POLICY ON ACCOUNT TO ROLE GOV_ADMIN; GRANT APPLY TAG ON ACCOUNT TO ROLE GOV_ADMIN; -- SEC_ADMIN USE ROLE SECURITYADMIN; GRANT CREATE USER ON ACCOUNT TO ROLE SEC_ADMIN; GRANT CREATE ROLE ON ACCOUNT TO ROLE SEC_ADMIN; GRANT MANAGE GRANTS ON ACCOUNT TO ROLE SEC_ADMIN;
Access roles
These roles should be granted privileges on a specific database or account objects at a granular level. In the role hierarchy, we defined read-only (RO) and read/write (RW) access roles at the database level only. However, in a real-life scenario, you will probably need to define roles at the schema or “group of tables” level.
The code below shows the definition of the access roles for the PROD_DB_FIN database:
USE ROLE SEC_ADMIN; -- PROD_DB_FIN -- Grant read-only permissions on database PROD_DB_FIN to PROD_DB_FIN_RO CREATE OR REPLACE ROLE PROD_DB_FIN_RO; GRANT USAGE ON DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RO; GRANT USAGE ON ALL SCHEMAS IN DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RO; GRANT SELECT ON ALL TABLES IN DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RO; GRANT SELECT ON FUTURE TABLES IN DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RO; -- Grant read-write permissions on database PROD_DB_FIN to PROD_DB_FIN_RW CREATE OR REPLACE ROLE PROD_DB_FIN_RW; GRANT INSERT,UPDATE,DELETE ON ALL TABLES IN DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RW; GRANT INSERT,UPDATE,DELETE ON FUTURE TABLES IN DATABASE PROD_DB_FIN TO ROLE PROD_DB_FIN_RW; -- Create role hierarchy GRANT ROLE PROD_DB_FIN_RO TO ROLE PROD_DB_FIN_RW;
Functional roles
As we will soon see, many data governance checks involve verifying the current user’s role. Therefore, it is essential to design a functional role hierarchy that aligns with business functions. In our role hierarchy, we defined a role for each business user: ACCOUNTANT, CLERK and HR_SPECIALIST. Moreover, notice how the ACCOUNTANT role inherits the CLERK role, allowing it to read the same databases as the CLERK. In addition, it can update the PROD_DB_FIN database because it inherits the PROD_DB_FIN_RW access role.
The code below shows the definition of the functional roles:
-- -- Functional roles -- USE ROLE SEC_ADMIN; -- ACCOUNTANT CREATE OR REPLACE ROLE ACCOUNTANT; GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE ACCOUNTANT; -- Grant access roles GRANT ROLE PROD_DB_FIN_RW TO ROLE ACCOUNTANT; -- Create role hierarchy GRANT ROLE ACCOUNTANT TO ROLE DB_ADMIN; -- CLERK CREATE OR REPLACE ROLE CLERK; GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE CLERK; -- Grant access roles GRANT ROLE PROD_DB_HR_RO TO ROLE CLERK; GRANT ROLE PROD_DB_FIN_RO TO ROLE CLERK; -- Create role hierarchy GRANT ROLE CLERK TO ROLE ACCOUNTANT; -- HR_SPECIALIST CREATE OR REPLACE ROLE HR_SPECIALIST; GRANT USAGE ON WAREHOUSE COMPUTE_WH TO ROLE HR_SPECIALIST; -- Grant access roles GRANT ROLE PROD_DB_HR_RW TO ROLE HR_SPECIALIST; -- Create role hierarchy GRANT ROLE HR_SPECIALIST TO ROLE DB_ADMIN; -- GOV_ADMIN -- Grant access roles GRANT ROLE PROD_DB_GOV_RW TO ROLE GOV_ADMIN; GRANT ROLE PROD_DB_HR_RO TO ROLE GOV_ADMIN;
Data governance policies
The role hierarchy in the previous section defines what can be done on different objects and by whom. However, it doesn’t restrict which records within a table a user can see or which values should be masked within a column. That’s where the data governance policies in this section come into play.
All data governance policies and tags are stored in the PROD_DB_GOV database under three schemas: MASKING, ROWACCESS and TAGS. Putting all the policies and tags in a single database allows us to centralize them and better restrict access to them. Please note that only the GOV_ADMIN role has read/write permissions on it.
The following diagram shows the PROD_DB_GOV database and its contents:

Column-level security
We implemented two types of column-level security features to satisfy the salary and SIN columns requirements. We defined a dynamic data masking policy for the salary column that hides the value depending on the current user’s role. The condition is straightforward: If the current user’s role cannot see the value, then return a NULL. Snowflake supports masking policies on tables and views. You can find additional information about column data masking in our company blog in this post.
The code below shows the definition of the dynamic data masking policy:
USE ROLE GOV_ADMIN;
USE WAREHOUSE COMPUTE_WH;
-- Dynamic data masking
CREATE OR REPLACE MASKING POLICY PROD_DB_GOV.MASKING.PAYROLL_SALARY_MASK AS (VAL NUMBER(10, 2)) RETURNS NUMBER(10, 2) -> CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTANT', 'HR_SPECIALIST') THEN VAL -- Only ACCOUNTANT and HR_SPECIALIST can see the actual value
ELSE NULL
END;
ALTER TABLE PROD_DB_FIN.MAIN.PAYROLL
MODIFY COLUMN SALARY_AMOUNT SET MASKING POLICY PROD_DB_GOV.MASKING.PAYROLL_SALARY_MASK;
We defined a masking policy for the SIN column that simulates decoding a value masked through external tokenization. In this approach, sensitive data is “tokenized” outside Snowflake, and the value needs to be “detokenized” at query runtime. Therefore, you usually need to call a third-party API through an external function. In this post, however, we just tokenized the SIN values using a base64 encoding function to keep things simple.
The code below shows the definition of the external detokenization masking policy:
USE ROLE GOV_ADMIN;
USE WAREHOUSE COMPUTE_WH;
-- External tokenization
CREATE OR REPLACE MASKING POLICY PROD_DB_GOV.MASKING.EMPLOYEE_SIN_DETOKENIZATION AS (VAL VARCHAR) RETURNS VARCHAR -> CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTANT', 'HR_SPECIALIST') THEN base64_decode_string(VAL) -- Using internal function
-- WHEN CURRENT_ROLE() IN ('ACCOUNTANT', 'HR_SPECIALIST') THEN external_function_decode(VAL) -- Using external function (AWS Lambda)
ELSE VAL
END;
ALTER TABLE PROD_DB_HR.MAIN.EMPLOYEE
MODIFY COLUMN SOCIAL_INSURANCE_NUMBER SET MASKING POLICY PROD_DB_GOV.MASKING.EMPLOYEE_SIN_DETOKENIZATION;
Row-level security
Column-level security allows you to mask values on specific columns. On the other hand, row-level security will enable you to filter out records in a table based on a particular condition. You can apply both types of security features to your tables and views. In this post, we defined a row access policy restricting access to only Canadian employees for the CLERK role. If the condition to filter out records is complex, you can use a mapping table to map roles to allowed values.
The code below shows the definition of the row access policy:
USE ROLE GOV_ADMIN;
USE WAREHOUSE COMPUTE_WH;
-- Row access policies
CREATE OR REPLACE ROW ACCESS POLICY PROD_DB_GOV.ROWACCESS.EMPLOYEE_COUNTRY_POLICY AS (COUNTRY VARCHAR) RETURNS BOOLEAN -> CASE
WHEN CURRENT_ROLE() IN ('CLERK') AND COUNTRY NOT IN ('Canada') THEN FALSE -- Hide employees outside Canada for CLERK
ELSE TRUE
END;
ALTER TABLE PROD_DB_HR.MAIN.EMPLOYEE
ADD ROW ACCESS POLICY PROD_DB_GOV.ROWACCESS.EMPLOYEE_COUNTRY_POLICY ON (COUNTRY);
Tag-based masking policies
Snowflake supports object tagging to help track sensitive data or resource usage on multiple types of database objects. You can find an overview of Snowflake’s object tagging in this post on our company blog.
Snowflake provides a convenient way to apply masking policies to a group of related columns using tags. First, you apply masking policies to a tag and then attach the tag to the associated columns. Snowflake will check the guidelines for the tag and apply one that matches the column type. For instance, in this post, we defined a PII tag to track Personal Identifiable Information (PII) columns in our tables. Next, we defined a PII_DATE_MASK masking policy for values of type DATE and applied it to the tag.
Finally, we attached the PII tag to the BIRTH_DATE column. As a result, the values on the BIRTH_DATE column are masked based on the conditions in the masking policy. The same tag can be applied to other DATE columns for the same result. Similarly, you could mask an “address” column by applying the same technique but using a masking policy for the type STRING.
The code below shows the definition of the tag and the tag-based policy:
USE ROLE GOV_ADMIN;
USE WAREHOUSE COMPUTE_WH;
-- Tag-based masking
CREATE OR REPLACE TAG PROD_DB_GOV.TAGS.PII;
-- Apply the PII tag to the BIRTH_DATE column
ALTER TABLE PROD_DB_HR.MAIN.EMPLOYEE
ALTER COLUMN BIRTH_DATE SET TAG PROD_DB_GOV.TAGS.PII='true';
-- Define the masking policy for the DATE data type
CREATE OR REPLACE MASKING POLICY PROD_DB_GOV.MASKING.PII_DATE_MASK AS (VAL DATE) RETURNS DATE -> CASE
WHEN CURRENT_ROLE() IN ('HR_SPECIALIST') THEN VAL
ELSE '1900-01-01'::DATE
END;
-- Apply the masking policy to the tag
ALTER TAG PROD_DB_GOV.TAGS.PII
SET MASKING POLICY PROD_DB_GOV.MASKING.PII_DATE_MASK;
Data classification
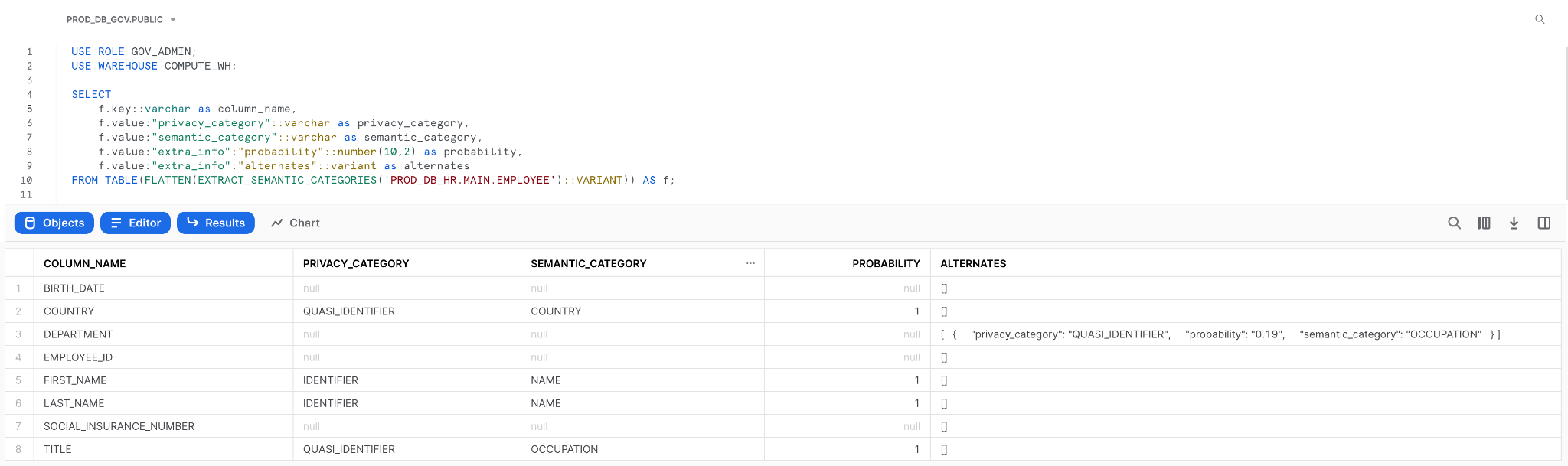
Snowflake provides data classification functions to help you identify and classify PII data in your tables. The EXTRACT_SEMANTIC_CATEGORIES function scans a table’s contents, giving you a result with the possible categories and their corresponding probabilities. The GOV_ADMIN role can run this function as part of his audit process to help him identify columns with PII information. The function’s result is on the EMPLOYEE table in the screenshot below. Note how the function returns nothing for the BIRTH_DATE and SOCIAL_INSURANCE_NUMBER columns. That is due to the masking policies that we have put in place.
Policy verification
Snowflake provides the POLICY_CONTEXT function to easily verify the query results returned from tables and views protected with data governance policies. We will use it to easily switch roles and verify the returned results.
Let’s query the EMPLOYEE_PAYROLL_VW view with the ACCOUNTANT role:

And now, let’s query the view with the HR_SPECIALIST role:

Finally, let’s query the view with the CLERK role:

Conclusion
Snowflake’s column-level and row-level security features allowed us to easily implement the data governance requirements outlined in the first section. Moreover, Snowflake’s role hierarchies allowed us to define custom roles to effectively control access to database objects. Another critical aspect of data governance is the use of metadata. In this post, we saw how tags can help identify and manage sensitive columns, but Snowflake provides many other metadata capabilities. The ACCOUNT_USAGE schema includes many views and functions to query object metadata, historical usage data, etc. For instance, an access history view allows you to track the read and write operations users perform. In contrast, an object dependencies view will enable you to determine the data lineage of your database objects.
All things considered, these features set Snowflake apart from other cloud data platforms in terms of security, governance and ease of management. However, to effectively govern your data assets, you must set up a data governance program encompassing technology, processes and people. Technology alone will not do it. Equally important, a data governance program will allow you to evolve your data governance structure as data volumes grow and new data streams emerge.
Thanks for reading. Feel free to drop any questions or share your thoughts in the comments.

