In this blog post, I would like to share some options that you can consider to model your cloud DW for better query performance. With a traditional EDW, we would either come up a STAR, Snowflake or similar schemas. These are nothing but a partially normalized data model more geared towards the measures that we would generally report on. In general, these models suit the DW databases that are row-based. Between row and columnar-based DW solutions, the key differences are with the way the data is actually stored in the disk. Here is a quick comparison between these stores.
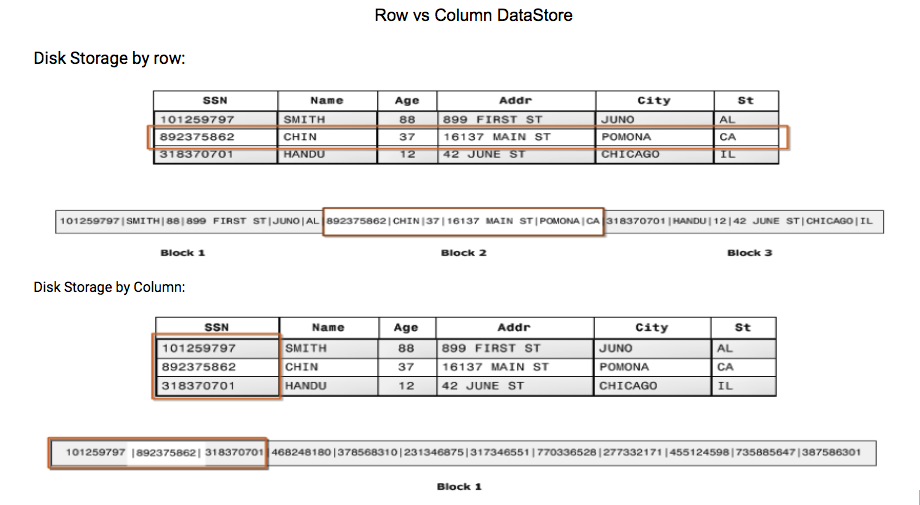 Cloud DW solutions like Redshift & BigQuery are MPP, OLAP and columnar models. Generally storage is not a concern, as storage costs are minimal with these options. With BigQuery especially, it is completely server-less and charges are only for the data columns processed and retrieved
.
Most of these handle well with STAR schema for data sizes up to couple TBs. At a petabyte scale, you will definitely want to consider optimizing your models to better serve your use cases.
With BigQuery or Redshift:
Cloud DW solutions like Redshift & BigQuery are MPP, OLAP and columnar models. Generally storage is not a concern, as storage costs are minimal with these options. With BigQuery especially, it is completely server-less and charges are only for the data columns processed and retrieved
.
Most of these handle well with STAR schema for data sizes up to couple TBs. At a petabyte scale, you will definitely want to consider optimizing your models to better serve your use cases.
With BigQuery or Redshift:
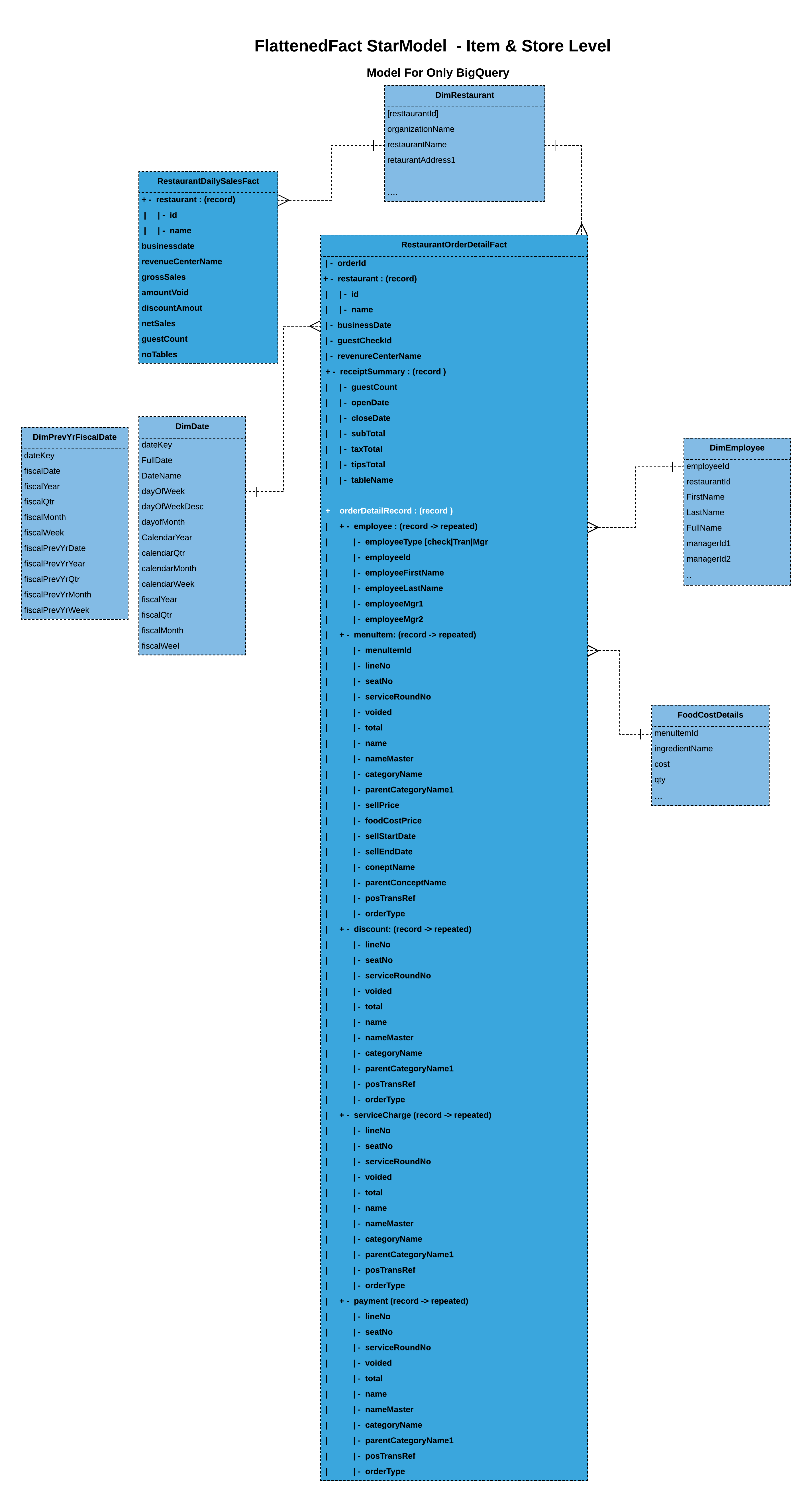
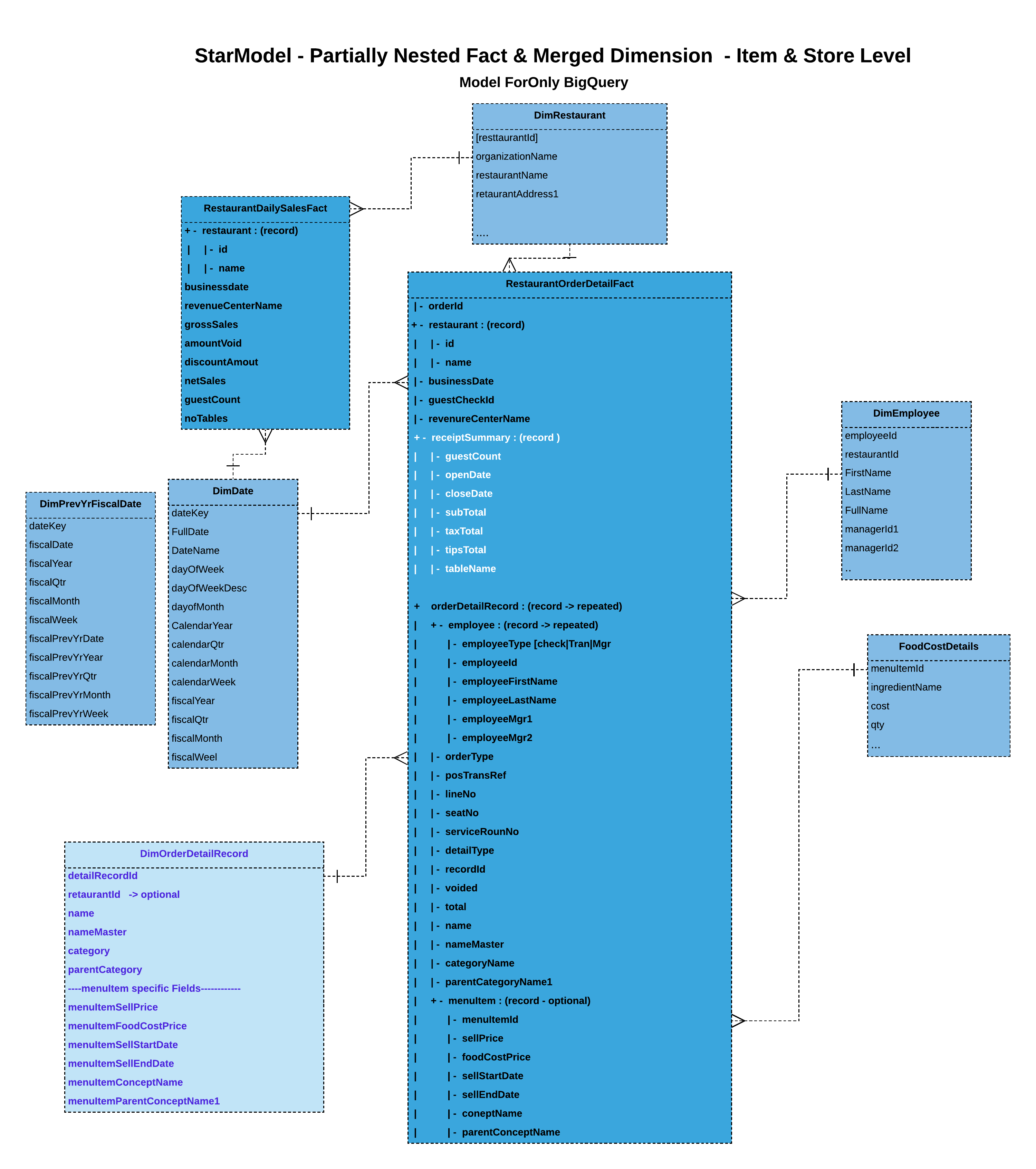
Here we attempt to nest some of the dimensional data along with the fact. This model allows to nest only the required dimensional to allow dimensional changes. Dimensional data is merged/denormalized as well to avoid joins.
Here we attempt to fully nest the dimensional data along with the fact to leverage BigQuery’s query performance. Again, consider using the previous approach if dimensional data were to change more often.
Cloud DW solutions like Redshift & BigQuery are MPP, OLAP and columnar models. Generally storage is not a concern, as storage costs are minimal with these options. With BigQuery especially, it is completely server-less and charges are only for the data columns processed and retrieved
.
Most of these handle well with STAR schema for data sizes up to couple TBs. At a petabyte scale, you will definitely want to consider optimizing your models to better serve your use cases.
With BigQuery or Redshift:
- Denormalize & Flatten: Performs well with large datasets when facts are denormalized and flattened. This allows you to reduce the number of joins that the query may operate on.
- Distribution keys: With Redshift, instead of denormalizing data, you have the option to specify the distribution keys that allow related data to be co-located. Based on the table's dependencies, you could choose an appropriate distribution key. But to begin with, if we have a right base model, we could plan to minimize the usage of distribution keys even with Redshift. The below sections will be focussing on that.
- Nested & repeated: While BQ performs well with star/snowflake schema model, it does best when denormalized, especially via its nested & repeated features. Nesting allows you to locate the relevant data (i.e, dimensional data along-with fact), and thereby avoid joins as well as improving query performance.
Cloud DW model options:
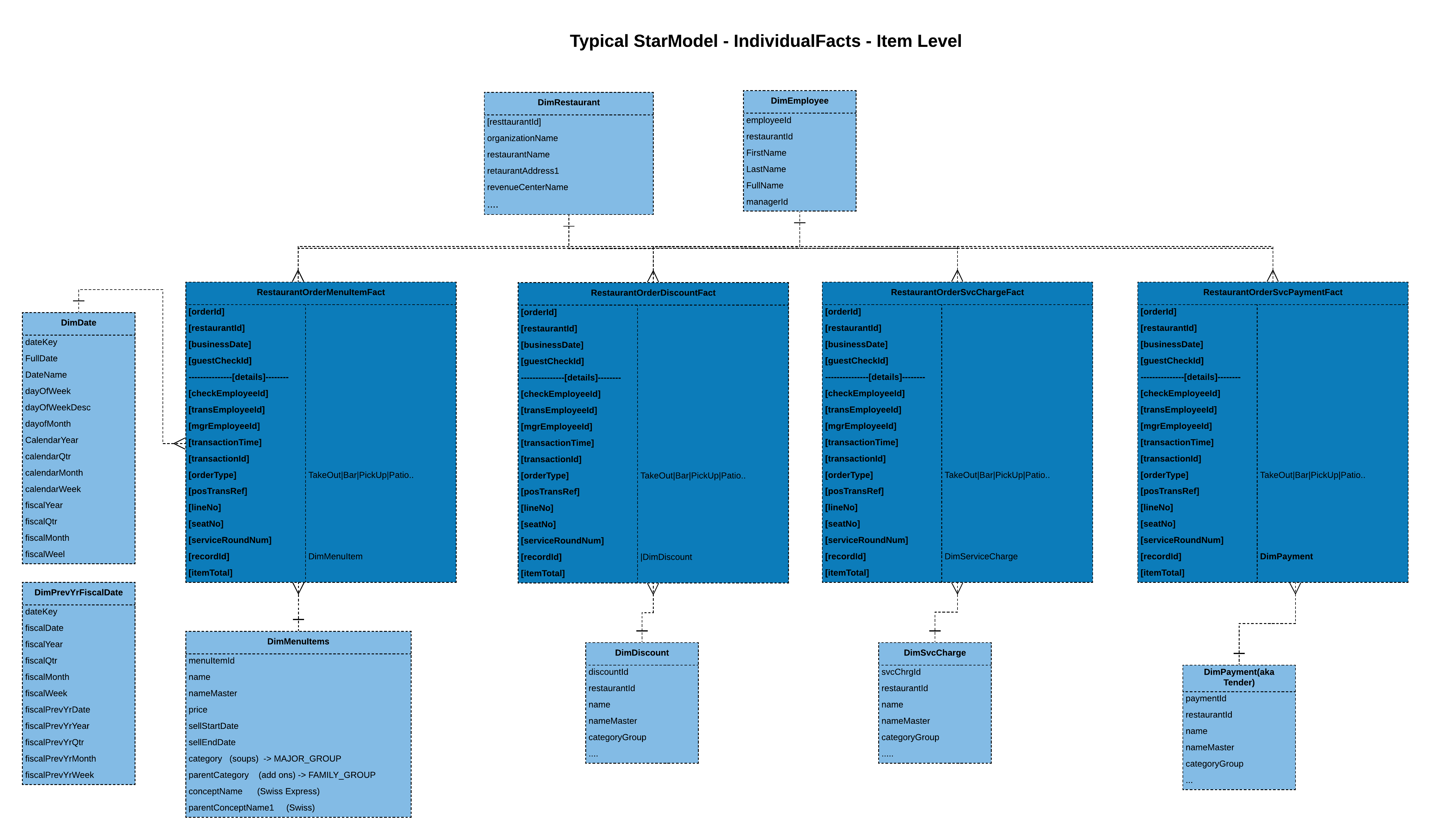
Merging facts:
Here we have considered merging/denormalizing facts, as most of the use cases in our case rely on analyzing the related measures. This way we can eliminate joins across facts.
Merging dimensional data:
As our dimension differs simply by its type, we could consider merging/denormalizing them as well. Again, this way we avoid joins here.
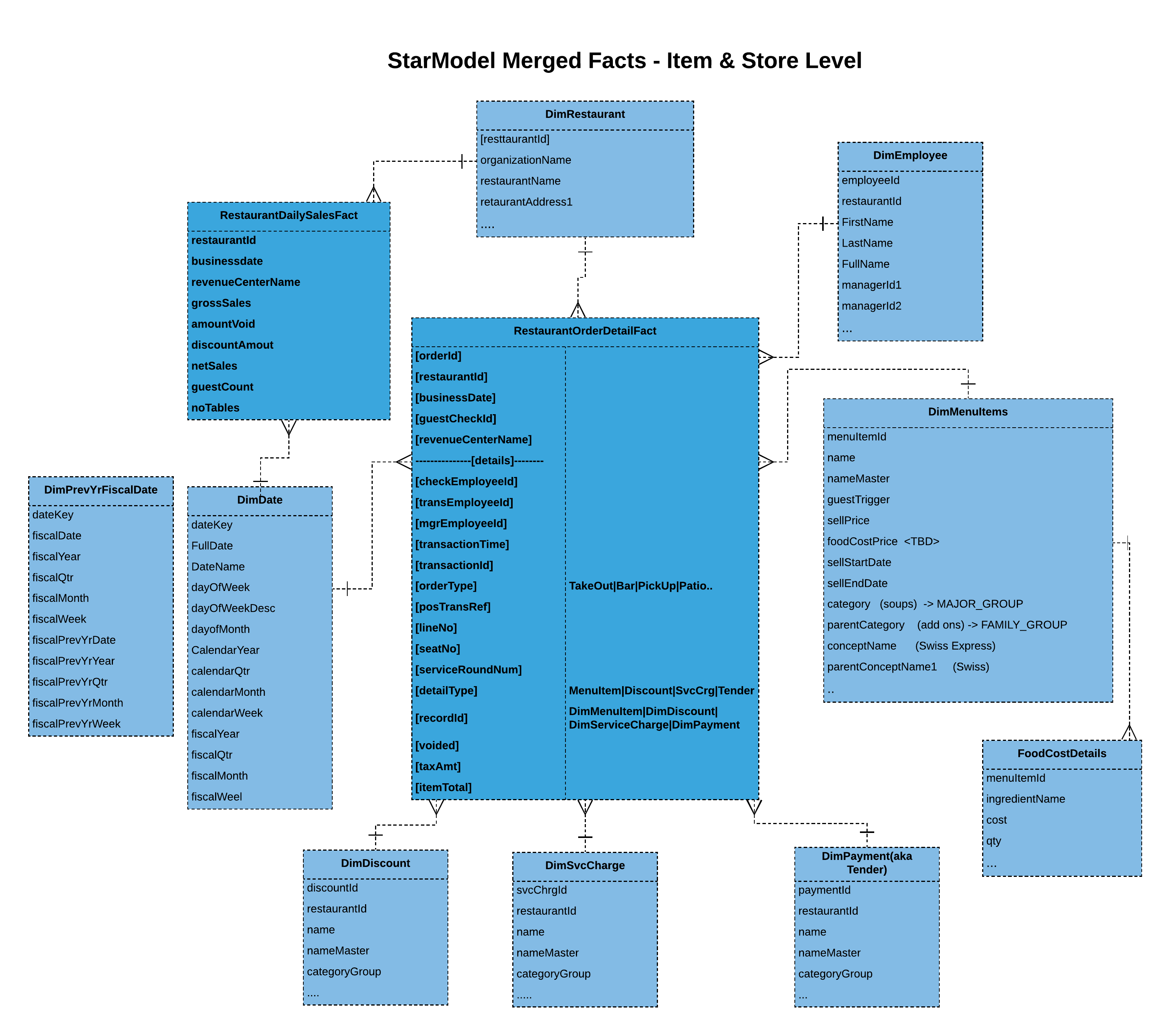
Denormalized fact
Here we have denormalized and flattened fact with its dimensional data. You should be careful in choosing this approach. Go with this option when you don’t expect dimensional data to change often or really don't care for the fact’s integrity with dimensional data, even when it does change. We can always look at other batch options to reflect the integrity of dimensional data. But that’s something to keep in mind.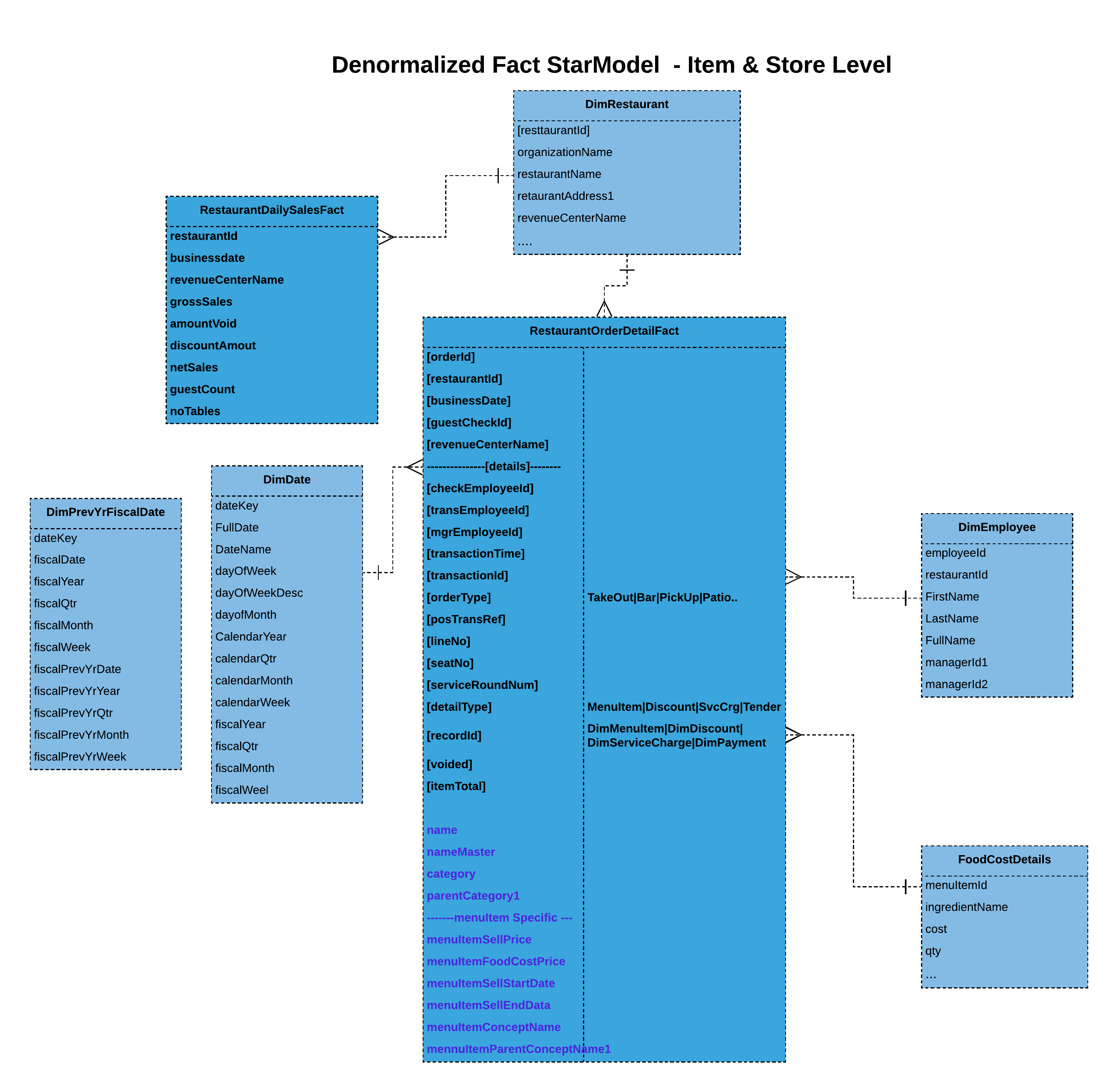 Partially nested fact with merged dimensions (BigQuery specific):
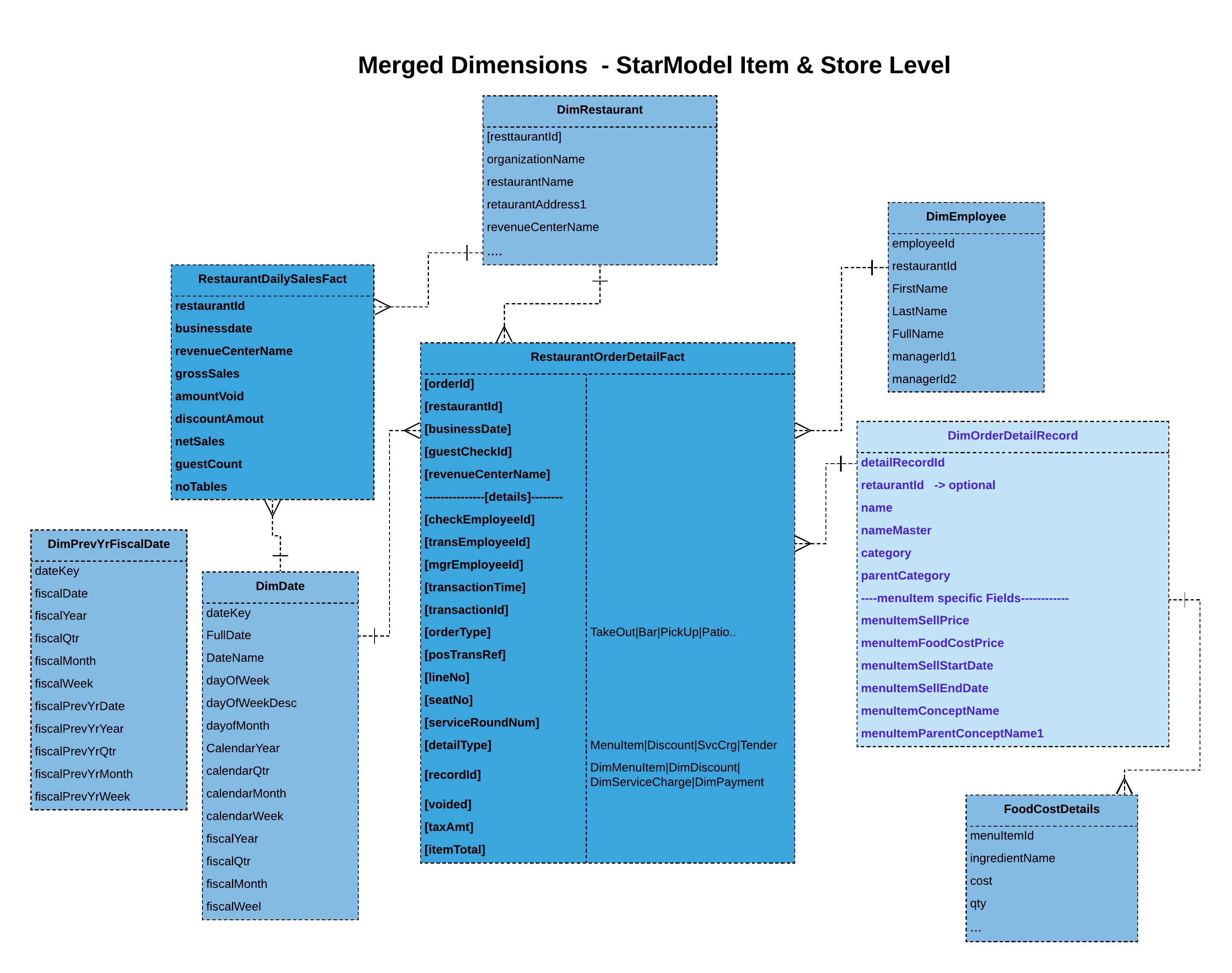
Partially nested fact with merged dimensions (BigQuery specific):
Here we attempt to nest some of the dimensional data along with the fact. This model allows to nest only the required dimensional to allow dimensional changes. Dimensional data is merged/denormalized as well to avoid joins.
 Fully nested and flattened fact (BigQuery specific):
Fully nested and flattened fact (BigQuery specific):
Here we attempt to fully nest the dimensional data along with the fact to leverage BigQuery’s query performance. Again, consider using the previous approach if dimensional data were to change more often.
Key note:
- Nested and repeated fields can maintain relationships without the performance impact of preserving a relational (normalized).
- Denormalization localizes the data to individual slots so execution can be done in parallel. With Redshift, instead denormalizing data, you have the option to specify the distribution keys that allows related data to be co-located.
- If you need to maintain relationships while denormalizing your data, use nested and repeated fields instead of completely flattening your data. When relational data is completely flattened, network communication (shuffling) can negatively impact query performance.

