Apache Kafka and Apache Flink are popular data streaming applications platforms. However, provisioning and managing your own clusters can be challenging and incur operational overhead. Amazon Web Services (AWS) provides a fully managed, highly available version of these platforms that integrate natively with other AWS services. In this blog post, we’ll explore the capabilities and limitations of AWS’s offering by deploying a simple data streaming application.
This blog post is divided into two parts. In Part 1, we’ll create an Apache Kafka cluster and deploy an Apache Kafka Connect connector to generate fake book purchase events. In Part 2, we’ll deploy an Apache Flink streaming application that will read these events to compute bookstore sales per minute.
Apache Kafka on AWS
The managed Apache Kafka service is called Amazon Managed Streaming for Apache Kafka or “Amazon MSK” for short. It was first introduced in November 2018 and reached general availability in May 2019. These are some of its main features:
Fully managed
You only need to provide your desired configuration and the service will take care of provisioning the broker and the Apache Zookeeper nodes. It will also automatically apply server patches and upgrades, and set up monitoring and alarms.
High availability
Your clusters are distributed across multiple Availability Zones (AZ). The service automatically replaces unhealthy nodes without downtime to your applications. Additionally, the service uses multi-AZ data replication to prevent data loss.
Pay-per-use pricing
You pay only for what you use. Moreover, you do not pay for the Apache Zookeeper nodes, or for the data transfer that occurs between brokers and Apache Zookeeper nodes within your cluster.
The managed Apache Kafka Connect service is called Amazon MSK Connect. It is fully compatible with Apache Kafka Connect, so you can deploy any of the available connectors or lift and shift your existing applications. The service takes care of provisioning the infrastructure, monitoring it and automatically scaling it based on connector load.
You can find more details about both services in the documentation.
Demo
The diagram below shows the overall architecture for the data streaming application and the related services that we will be deploying. For simplicity, we will deploy Amazon MSK in only two AZs, and both Amazon MSK and a bastion host will reside in the same public subnet. In a production environment you should use three AZs for higher availability, and deploy Amazon MSK and a bastion host in separate private and public subnets respectively. As a result, your Amazon MSK clusters would be unreachable from outside the AWS network, improving your security posture.
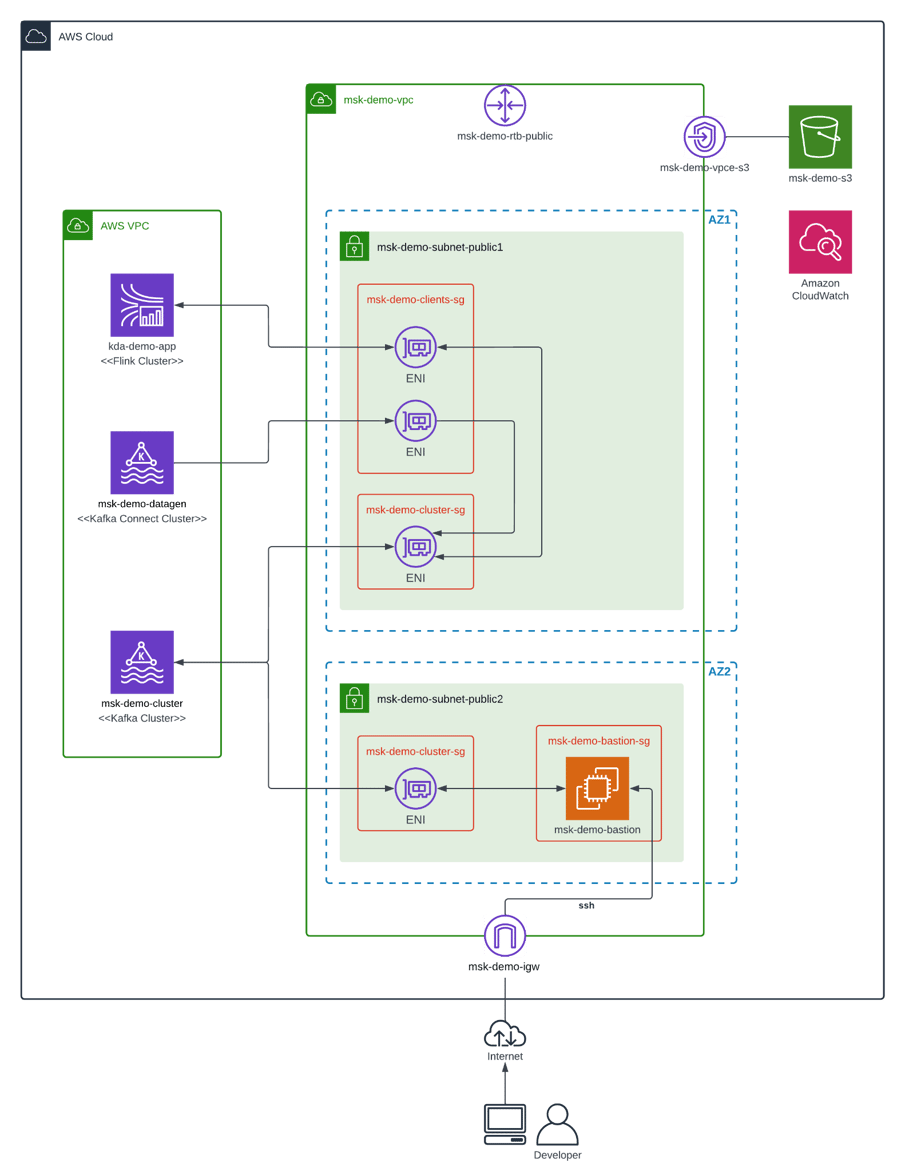
Here’s a brief description of the main components:
msk-demo-cluster
Amazon MSK cluster that stores fake book purchase data in three topics: “book”, “bookstore” and “purchase”.
msk-demo-datagen
Amazon MSK Connect cluster running an instance of Amazon MSK Data Generator. It generates the data for the three topics above.
kda-demo-app
Apache Flink application deployed on Amazon Kinesis Data Analytics or “Amazon KDA” for short. We will learn more about this service in part 2 of this blog. In the meantime, it suffices to say that it is a serverless, fully-managed version of Apache Flink. The data streaming application reads the “purchase” and “bookstore” topics, computes bookstore sales per minute and stores the results in a “sales” topic.
msk-demo-bastion
Amazon EC2 instance that serves as a bastion host. We can connect to it using ssh, and then verify the contents of the Amazon MSK cluster using tools like kafkacat.
msk-demo-s3
Amazon S3 bucket that is needed for deploying JAR files to Amazon KDA and Amazon MSK Connect. In addition, the logs from Amazon MSK and Amazon MSK Connect are dumped here for easy consultation.
msk-demo-vpc
Amazon VPC network that contains the public subnets and other connectivity resources needed by the demo application. Multiple security groups are defined to restrict access to specific ports on source and target resources.
Deployment
We will not go over all the steps needed to deploy the Amazon MSK cluster and the Amazon MSK Data Generator. If you are looking for detailed information, please take a look at the How to Deploy MSK Data Generator on MSK Connect and MSK Labs pages. Rather, we will concentrate on the specific configurations and difficulties we encountered while setting up the clusters.
Amazon MSK
As of the time of this writing, the recommended Apache Kafka version showing in the AWS console is 2.6.2, and the most recent supported version is 2.8.1. However, the latest version of Apache Kafka is 3.2.0. Therefore, Amazon MSK might not be for you if you need the most recent version of Apache Kafka. There is a bit of a lag before the latest version becomes available.
The provisioning of the Amazon MSK cluster is straightforward, you only need to specify the type and number of broker instances, the number of AZs and the storage per broker. AWS provides a handy spreadsheet that can help you right-size your cluster based on your desired throughput. Furthermore, AWS recently launched Amazon MSK Serverless, which automatically provisions and scales compute and storage resources. Moreover, you only pay for the data you stream and retain. However, it comes with some limitations. It can only retain data for 24 hours and the throughput is capped at 200 MBps for ingress and 400 MBps for egress.
Configuration
Since our cluster is deployed in only two AZs we had to adjust the default configuration to set the replication factor to 2 and the in-sync replicas to 1 (see below). The default configuration assumes 3 brokers, so unless you adjust it you will get “NOT_ENOUGH_REPLICAS” errors when the Amazon MSK Data Generator will try to publish messages.
auto.create.topics.enable=true delete.topic.enable=true default.replication.factor=2 min.insync.replicas=1 num.io.threads=8 num.network.threads=5 num.partitions=1 num.replica.fetchers=2 replica.lag.time.max.ms=30000 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 socket.send.buffer.bytes=102400 unclean.leader.election.enable=true zookeeper.session.timeout.ms=18000 transaction.state.log.replication.factor=2 transaction.state.log.min.isr=1 transaction.max.timeout.ms=900000
Amazon MSK Connect
Deploying the Amazon MSK Data Generator on Amazon MSK Connect is also straightforward, however it can be difficult to get it to work properly if something is not set up correctly (security groups, IAM role, authentication, etc.). For this reason, make sure to configure log delivery to the S3 bucket so that you can troubleshoot issues.
Configuration
The Amazon MSK Data Generator configuration below generates data for the “book”, “bookstore” and “purchase” topics every two seconds. Note that the “bookstore_id” and “book_id” attributes in the “purchase” topic reference keys in the “bookstore” and “book” topics. Therefore, the demo application can “join” the events coming from related topics.
connector.class=com.amazonaws.mskdatagen.GeneratorSourceConnector
tasks.max=3
# book
genkp.book.with=#{Internet.uuid}
genv.book.title.with=#{Book.title}
genv.book.genre.with=#{Book.genre}
genv.book.author.with=#{Book.author}
# bookstore
genkp.bookstore.with=#{Internet.uuid}
genv.bookstore.name.with=#{Company.name}
genv.bookstore.city.with=#{Address.city}
genv.bookstore.state.with=#{Address.state}
# purchase
genkp.purchase.with=#{Internet.uuid}
genv.purchase.book_id.matching=book.key
genv.purchase.bookstore_id.matching=bookstore.key
genv.purchase.customer.with=#{Name.username}
genv.purchase.quantity.with=#{number.number_between '1','5'}
genv.purchase.unit_price.with=#{number.number_between '10','75'}
genv.purchase.timestamp.with=#{date.past '10','SECONDS'}
# global
global.throttle.ms=2000
global.history.records.max=1000
The custom worker configuration below serializes the generated data in JSON format without adding a JSON schema to each record. We are not using a schema registry for our demo application, but you can use AWS Glue Schema Registry if you need schema management.
key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.json.JsonConverter value.converter.schemas.enable=false
Bastion host
We launched a Ubuntu EC2 instance in one of the public subnets in the same VPC as the Amazon MSK cluster. If you are not familiar with launching EC2 instances, you can find more information in the Get started with Amazon EC2 Linux instances tutorial.
In order to read the data in the Amazon MSK cluster you need to install a tool such as kafkacat. This can be done by running the following commands through ssh once the instance is up and running:
sudo apt update sudo apt install kafkacat
Configuration
Make sure to set the “Auto-assign public IP” to “Enable” and to create a security group that allows incoming traffic only on port 22. Similarly, the security group for the Amazon MSK cluster needs to allow connections on ports 9092 and 2181 from the security group of the bastion host. Finally, create a key pair and assign it to the EC2 instance to enable connectivity via ssh.
Result
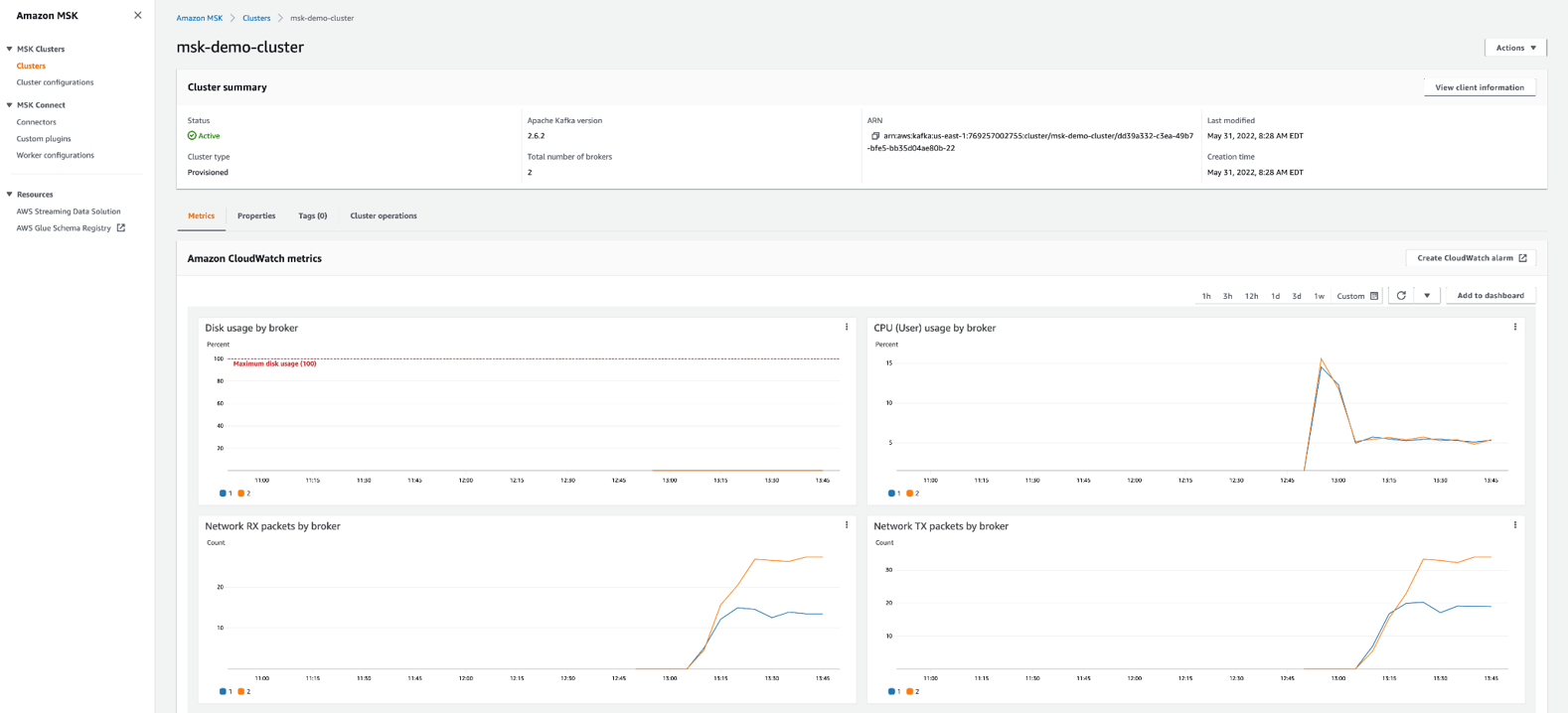
Once the Amazon MSK cluster is in “active” state and the Amazon MSK Data Generator is in “running” state you should see activity in the dashboard:
Let’s now connect to the bastion host to take a look at the data being generated. Since the bastion host is in a public subnet we can connect to it using ssh. You will need the key you assigned to the EC2 instance and the public IP address:

Using the kafkacat command we can connect to the Amazon MSK cluster and print on the screen some of the data being generated for the three topics:
books

bookstores

purchases

Conclusion
Amazon MSK and Amazon MSK Connect provide fully managed, highly available versions of Apache Kafka and Apache Kafka Connect. It is easy to deploy production-ready applications and benefit from the security, reliability and scalability that distinguishes the AWS platform. Additionally, the pay-as-you-go pricing model is attractive for most use cases. We believe that Amazon MSK and Amazon MSK Connect are best suited for the following clients:
- Clients that want to use open source versions of Apache Kafka and Apache Kafka Connect
- Clients that can tolerate running a few versions behind the latest release of Apache Kafka
If a client would like to use the latest version of Apache Kafka or some of the licensed features from Confluent, then Confluent Cloud would be a better option. Moreover, it can also be deployed on the AWS cloud.
In this blog post we saw how easy it is to provision a cluster on Amazon MSK and to deploy a data generator on Amazon MSK Connect. Stay tuned for part 2, where we will deploy an Apache Flink streaming application on Amazon KDA.
Thanks for reading. Feel free to drop any questions or share your thoughts in the comments, and make sure to sign up for updates.

