In the previous blog, we presented a simple database migration approach using Apache Nifi. Following our previous blog, here we present approaches to handling the migration of large database tables. If you have not had a chance to read our previous blog post, please find it here.
 Database migration: Extraction process[/caption]
Database migration: Extraction process[/caption]
 Database Migration: Ingestion Process[/caption]
Database Migration: Ingestion Process[/caption]
Major challenges in database migration
During database migration using Nifi, it is important to understand that some of the Nifi processors read all the data of a flowfile into the memory, thus limiting the size of data to work with. The ‘PutDatabaseRecord’ processor, which inserts data into the database table, is one such example. It loads all the flowfile data into the memory, thus limiting the size of table data it can process at once. So, during the migration, any table with a size exceeding the heap size allocated to the Nifi instance lands into the category of a large table. While migrating the large tables, the ‘PutDatabaseRecord’ processor may generate an ‘OutOfMemory’ error or may crash the Nifi instance if all the table data is ingested using a single flowfile.Solution: two approaches
Large tables can be handled in database migration using Apache Nifi by splitting the table data into multiple chunks. Two different approaches, based on our previous database migration process, can be used for splitting the table data.First: extract data in parts
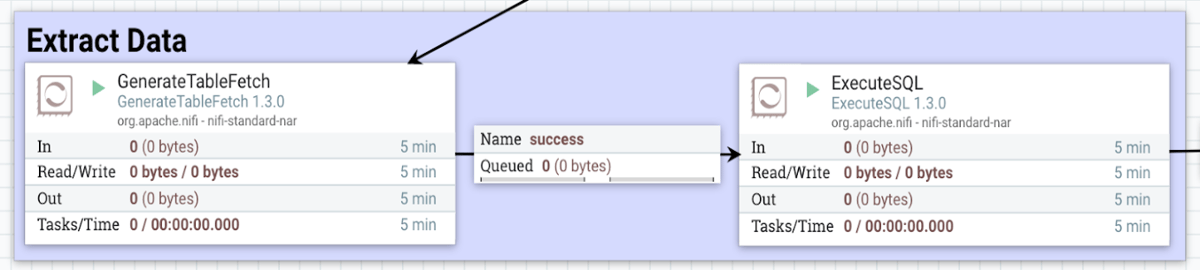
At the ‘Extract Data’ phase of the migration process (see migration process here ), add the ‘GenerateTableFetch’ processor. This processor generates ‘SQL select’ statements to fetch data from the table in multiple chunks. Edit the properties of the processor and set the ‘Partition Size’ property to limit the number of rows fetched in a single chunk. Set the ‘Partition Size’ based on the configuration (heap size) of the Apache Nifi instance. The ‘GenerateTableFetch’ processor is commonly used for incremental data extraction. Given a column/list of columns, which uniquely represents a row, to keep a record of the previously fetched rows, the processor fetches only the new or updated records from the table. Add the column-name(s), which will be used for incremental data extraction, to the ‘Maximum-value Columns’ property of the processor. Note that if the 'Maximum-value Columns' property is left empty, then all columns of the table will be used for incremental fetch and will have a performance impact. One of the drawbacks of the first approach is that, for a better performance, the 'GenerateTableFetch' processor requires a list of column(s) to be added as a property to use for incremental data extraction. [caption id="attachment_104598" align="aligncenter" width="1200"] Database migration: Extraction process[/caption]
Second: split data after extraction
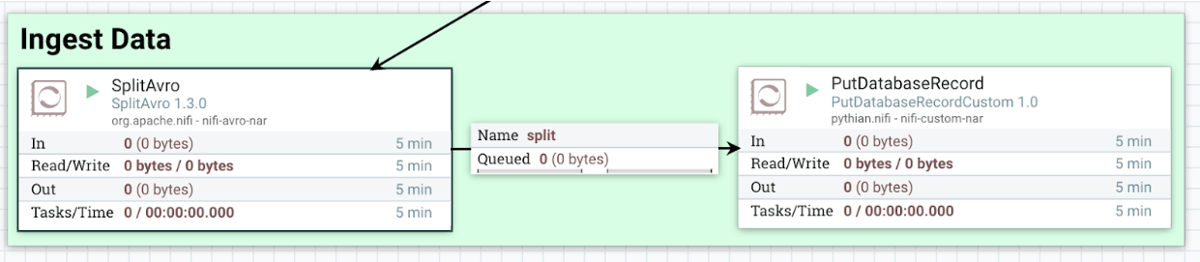
In the second approach, extract all the table data using ExecuteSQL processor at once, and then split the data before ingesting. At the ‘Ingest Data’ phase of the migration process, use the ‘SplitAvro’ processor to split the incoming Avro file into multiple multiple Avro files. Set the ‘Output Size’ property of the processor equal to the number of rows to be contained in a single split file. In this way, the ‘PutDatabaseRecord’ processor will receive multiple small flowfiles, preventing ‘OutOfMemory’ error or Nifi crash. Unlike the previous approach, the advantage of this approach is that the ‘SplitAvro’ processor does not require a list of column name(s) for splitting the flowfile. [caption id="attachment_104597" align="aligncenter" width="1200"] Database Migration: Ingestion Process[/caption]

