“We have many disparate data sources and we’re having a hard time getting a global view of all our data across our organization.”
“Our data is currently all in <enter data warehouse name here> and we want to migrate it to Google Cloud.”
“We’d like to lift-and-shift our data from warehouse X into BigQuery.”
These are a few of the statements that I hear week in and week out (and sometimes daily) when speaking with (potential) clients. Time after time I see that there are some considerable misconceptions about how architecting a data analytics environment on Google Cloud Platform (GCP) (and cloud platforms in general) differs from the more traditional approach. Traditionally it was more along the lines of dumping everything into an enterprise data warehouse and then hammering it with some ETL tools to clean/transform/process your data in order to prep it for analytics workloads. And so, for some the concept of a data pipeline is a foreign one, and for others, the idea that Google BigQuery isn’t just another generic data warehouse isn’t plausible…
To clarify, this isn’t necessarily restricted to GCP, and can actually be applied to cloud-based data analytics platforms, generally. The reason why I’m focusing on GCP is two-fold.
First off, I’m a fan of Google’s big data service offerings and all the value that they provide. Second, I see GCP as being one of the pioneering platforms when it comes to ease, fluidity, and speed of deployments, especially with respect to big data architectures.
So, while BigQuery is the golden child, with all the price and performance benefits that it provides, we can’t forget about the rich ecosystem of managed data services that surround it when architecting data platforms on GCP. And this is where I really see Google shining in the big data space.
Where to begin
As a solutions architect, I’m also a compulsive planner, and that means I always like to see some form of structure in the solutions that we put together; that being said, the “because that’s what worked” answer is hardly ever a satisfactory one. I’m an advocate of layered architectures that usually map to corresponding service assignments. Likewise, when approaching the data analytics platform problem, the idea that the data warehouse is the workhorse and everything gets dumped in there, is a very scary one; it’s a literal translation of putting all your eggs in one basket.

A Layered Architecture
Layers, layers, layers…
Going back to basics, the definition of every system is defined by its functionality and in relating its inputs to certain (desired) outputs. Generally speaking, if we can build a system that gives us the intended output when assigned the corresponding input(s), then we have succeeded in achieving the required functionality. But is that enough? Certainly not!
Functionality: What happens when we start adding more/different inputs? Do we still get the correct/intended outputs?
Modularity: What happens when we need to fix or upgrade a sub-component of this system? Do we just throw it out and build something new from scratch?
Scalability: What happens when demand for the system increases? Can it scale to meet this increased demand? Or do we dump it and build a more performant version of it?
Extensibility: What about when we need to introduce a new form of functionality or a new feature? Is it modular and pluggable enough that it can be augmented with new features? Or is it so monolithic that building a new system altogether is the easier route?
These are all some of the basic questions that an engineer would usually ask themselves before designing any system.
So how do we apply this to the data analytics platform problem?
A data analytics platform running on a cloud platform is a system in and of itself. This means that it has inputs and outputs with the expectation that certain inputs would map to certain outputs. However, is this system only performing a single task under the hood? No, it’s not! (if that were true I would sleep a lot better at night)
To clarify, there are a set of common functional features & characteristics that we aim to achieve when designing such a platform. These features & characteristics can be:
- Ingestion
- Storage
- Processing
- Analytics
- Exploration
- Visualization
Each of these characteristics plays a significant role in order to achieve a platform that is generally functional to provide data analytics to an end-user when fed with data from a number of sources.
Ok, so now what?
Now we can take the concept of a layered architecture, and apply it to this multi-feature definition of a data analytics platform, and formulate a feature-oriented architecture that functional, modular, scalable and extensible. In order to do so, we can assign a layer to each specific feature. Then we define the relationships between the different layers based on how these features would interact with one another.
For example, it goes without saying that data ingestion will be the first point of contact for incoming raw data from external sources. Next data will need to land in a store where it can be explored and processed. Finally, the processed data will need to be exposed to the visualization tool that the end-user will use to interface with the overall system.
N.B. I realize this is written in an oversimplified manner, however, it’s just to provide context to the overarching topic. An actual design process is significantly more complicated and takes a considerable amount of other factors into consideration.
What we come out with is a layered platform architecture, arranging the different layers as follows.
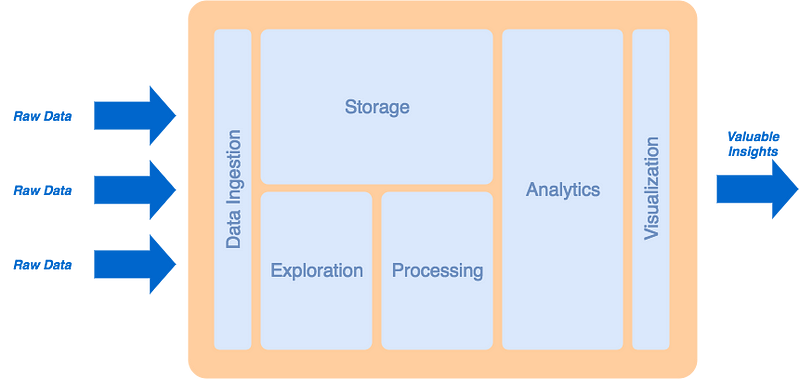 High-level Big Data Platform Architecture[/caption]
High-level Big Data Platform Architecture[/caption]
Enter Google Cloud Platform
As I was saying earlier — before I went off on a tangent on developing a layered big data platform design in a cloud environment — Google Cloud provides a rich ecosystem of managed and serverless big data services, including BigQuery, that align very well with this layered design approach. So much that if you take the above diagram and select the corresponding services that Google offers in each one of these roles you would probably come up with something like this.
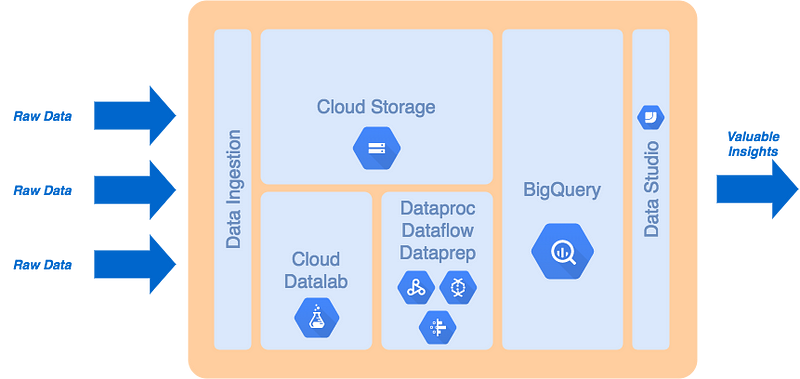 High-level Big Data Platform Architecture on Google Cloud Platform[/caption]
High-level Big Data Platform Architecture on Google Cloud Platform[/caption]
So there definitely are other options and combinations of services, and every organization will have its own requirements, and its specificities, and even limitations that may have repercussions on specific service selection. Not to mention that I didn’t even get into the data timeliness aspect at all (i.e. batching, micro-batching, and streaming) and the effects of that on the choice of services above as well as their integration requirements. What’s important to note though is that even in spite of the different timeliness options, the layered architecture above is still applicable and can serve the required purpose it was set out to achieve.
The added-value of Google Cloud
The best part of all of this is that each one of the services identified above is either a managed service, where Google takes care of automating the underlying infrastructure and deployment (i.e. Datalab and Dataproc), or a purely serverless one, where Google fully manages the whole service for you and provides just a (somewhat pretty) UI and an API to interact with it (i.e. Storage, BigQuery and Data Studio); there’s also Cloud Dataflow and Cloud Dataprep that sit somewhere in between those two categories, but you get the point.
All in all and as you can see, Google makes it very convenient to plug-and-play (now that’s a term I haven’t heard or used in a couple of decades) services that align well with good architectural design practices. This enables any organization to build out an enterprise-grade and production-ready data analytics platform that can support its needs with an extremely quick time-to-value.
N.B. I didn’t assign a data ingestion service on purpose, as there are a number of different options that can be used, all depending on the nature of the data sources being ingested. One of my favorites is Apache NiFi, simply due to its versatility and the simple fact that it’s built primarily as a data ingestion tool. However to-date there is no managed Apache NiFi service on GCP, nor on any other cloud platform as far as I am aware. Another great candidate for data ingestion is Google App Engine if you prefer more of a PaaS deployment.
Key takeaways — TL;DR
- For some, approaching the concept of an enterprise data analytics platform may appear as a bit of a paradigm shift from the traditional method of dumping all your eggs into one basket.
- Building a modern data platform should not be an ad-hoc activity; take your time, define your features, develop a layered feature-oriented architecture, define the corresponding functional role(s) for each layer (per the original feature requirements), and select the technologies that best align with the role of each layer.
- Google provides a rich product suite of managed and serverless big data and analytics services that make it easy and accessible for anyone to leverage and integrate highly performant components when building data analytics platform on GCP.
Learn more about Pythian’s Cloud solutions for Google Cloud Platform and check out our Analytics as a Service solution (A fully-managed end-to-end service that brings your multi-source, multi-format data together in the cloud).


