
Fuzzy Search in SQL Server is not done very well. This post will cover how to implement Fuzzy Search capabilities using several approaches.
 An example search on IMDB[/caption]
I don't like scrolling up.[/caption]
An example search on IMDB[/caption]
I don't like scrolling up.[/caption]
What is it?
Fuzzy Search is the process to locate records that are relevant to a search, even when the search criteria doesn't match. Fuzzy Searches are used to:- Suggest the correct spelling of a word ("Did you mean this...").
- Find results related to your search term ("You might also like...").
- Finding synonyms for search terms (Search for Dog and also get results for Puppies and Pets).
- Probably other things...
What Does it Fix?
As suggested above, Fuzzy Search logic is great for when you or the users don't know the exact term they're looking for. For example, let's say I want to find the latest James Bond movie, but only vaguely know its name. An IMDB search for "Specter" brings up the James Bond "Spectre" movie as a suggestion today. If you actually search for the term, you'll get a wide variety of increasingly weird results (And also the right answer!). I don't have access to the IMDB code, but I believe they're using a combination of the Levenshtein Distance, Trigrams, and maybe Double Metaphones. Coincidentally, those are exactly what we're covering here. [caption id="attachment_81169" align="alignnone" width="360"]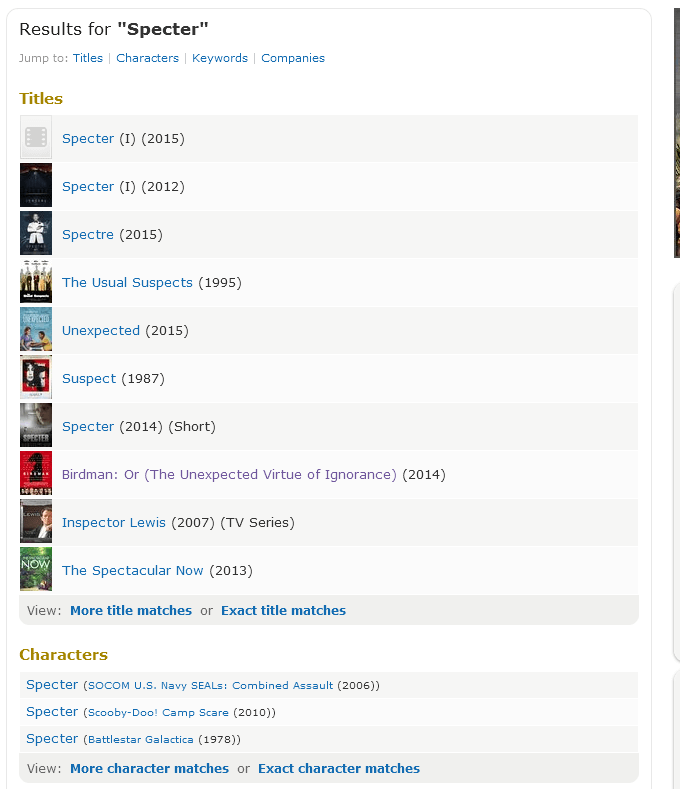 An example search on IMDB[/caption]
An example search on IMDB[/caption]
Fuzzy Search in SQL Server
Before implementing Fuzzy Search in SQL Server, I'm going to define what each function does. As you'll see, they are all complementary to each other and can be used together to return a wide range of results that would be missed with traditional queries or even just one of these functions. The three functions we're going to look at are:- Levenshtein Distance
- Trigrams
- Double Metaphones
Levenshtein Distance
The Levenshtein Distance is a calculation of how different two strings are, and it's expressed as the number of steps required to make StringA look like StringB. The steps are counted in terms of Inserts, Updates, and Deletes of individual letters in the two words being compared. This is good for short strings where not many differences are expected, AKA misspelled words. A simple example is the word Car to Date. The Levenshtein Distance here is 3, and we get there by: Step 1: UPDATE 'C' to 'D' Step 2: UPDATE 'r' to 't' Step 3: APPEND 'e' So, in the IMDB example, my search for "Specter" has a Levenshtein Distance of 2 from "Spectre". Again, we get there by: STEP 1: UPDATE 'r' to 'e' STEP 2: UPDATE 'e' to 'r' There is also the Damerau-Levenshtein Distance. This is built on the Levenshtein Distance, but accounts for transpositions of letters right next to each other. That would have returned a value of 1 with this logic: STEP 1: Flip 'r' and 'e'Trigrams
Trigrams are used to find matching sets of words or characters in words or phrases. As the name implies, each Trigram is a set of 3 characters or words, and you simply count how many trigrams in each string match the other string's trigrams to get a number. These are great for comparing phrases. An easy example is to compare a search for "SQL Server" to "SQL Sever": STEP 1: Break 'SQL Server' up into trigrams 'SQL', 'QL ', 'L S', ' Se', 'Ser', 'erv', 'rve', 'ver' STEP 2: Break 'SQL Sever' up into trigrams 'SQL', 'QL ', 'L S', ' Se', 'Sev', 'eve', 'ver' STEP 3: Count the number of trigrams that match: 5 A matching set of 5 trigrams might mean these are close enough for the application to suggest as an alternative. Another example is comparing the phrase "Oracle" to "Relational Database Management System". STEP 1: Break 'Oracle' up into trigrams 'Ora', 'rac', 'acl', 'cle' STEP 2: Break 'Relational Database Management System' into trigrams 'Rel', 'ela', 'lat', 'ati', 'ona', 'nal', 'al_', 'l_D', ..., 'tem' STEP 3: Count the number of trigrams that match between them: 0 As you can see, Oracle isn't very close to being an RDBMS at all. Finally, in our IMDB example, you can see that the movie Unexpected was returned. Why? I don't actually know, but I believe it's because there are several matching trigrams between "Specter" and "Unexpected" which pushed it into the possible suggestions. [caption id="attachment_81169" align="alignnone" width="360"]
I don't like scrolling up.[/caption]


