
This is the next post in my series about Oracle GoldenGate Big Data adapters. For reference, the other posts in the series so far:
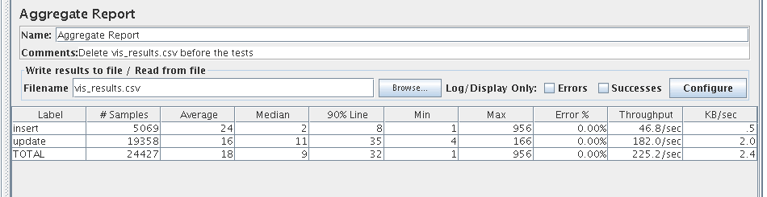 Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.
Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.
- GoldenGate 12.2 Big Data Adapters: part 1 - HDFS
- GoldenGate 12.2 Big Data Adapters: part 2 - Flume
- GoldenGate 12.2 Big Data Adapters: part 3 - Kafka
- GoldenGate 12.2 Big Data Adapters: part 4 - HBASE
Here is a short summary. The MongoDB adapter is easy to use, it has most of expected configuration options, replicates all DML correctly and with good speed. It doesn't replicate truncates and some other DDL like an index creation, and cannot handle Create Table As Select (CTAS) clause. You need to keep in mind all table changes will be applied to only new inserted rows. I would advise to switch logging from "DEBUG" to "INFO" and use "op" (operational) mode for the replicat to improve performance and avoid memory related issues with big transactions. Also, you may need to tune java memory parameters for the adapter since the default value did show instability on large transactions. And the last thing I would love to see in the package is a piece of proper documentation with a description of all possible parameters. I hope you have found this article helpful. Happy implementations.


