Welcome to the 3rd and final part of this blog. You can find the first part of the series here, and the second part here.
In the previous parts of the series, we created the GCP infrastructure and the Cockroach DB cluster which is up and running. The cluster consists of nine different nodes which are running on three different GCP Regions. We have chose this design to make our cluster available in case of an Availability Zone failure or in case of a Region failure, and also to support users around the world with good latency connections.
Cluster Console
With the current configuration incoming connections to the Load Balancer will be redirected to the nodes that have better connection latency. For example, if a connection is originated in Madrid-Spain the Load Balancer will redirect the session to any of the three nodes running in the Europe Southwest Region. Additionally if you want to connect directly to any specific node, you can also do it, without using the Load Balancer. From the CockroachDB Console we can take a look at the network latency across the cluster:
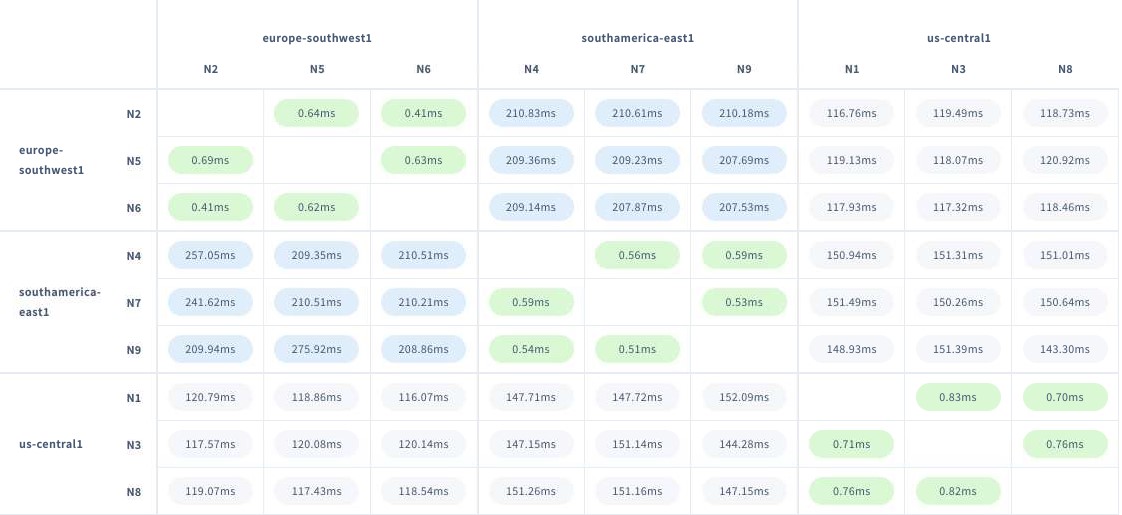
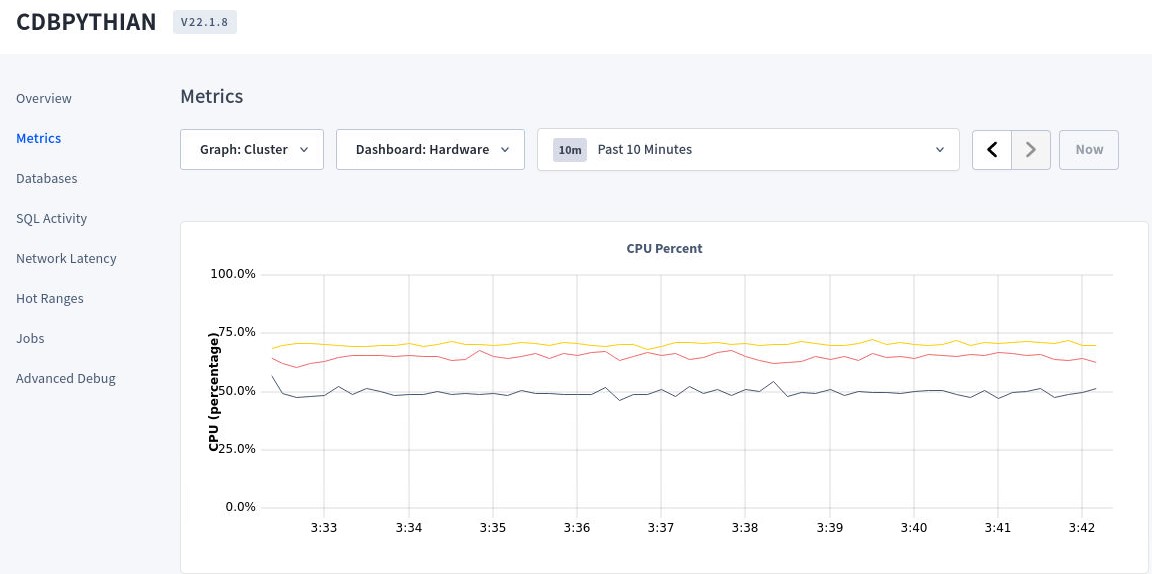
From the console we can also check different Metrics to manage the cluster. We can check the amount of connections, to which nodes, the hardware usage, which SQL queries are running, etc.
Its important to review the Metrics to confirm the cluster is behaving as we want and to verify if the Load is being balanced as expected. There are CockroachDB testing workloads that can be used to simulate several DB connections from different locations. With the simulation running, from the console we can verify which nodes are processing the workload to confirm the Load Balancing is working fine. We can also stress out our cluster to confirm the amount of nodes is sufficient for the required workload. You can find the details for the built-in load generators here.
High Availability
Like mentioned before CockroachDB is built to be fault-tolerant and to recover easily, that is why the data is replicated across the cluster to make the data available in the case of node failure. Lets test our cluster to see if it can resist a Region failure, which will make unavailable 3 of the 9 nodes. Before doing it, we need to increase the replication range which is 3 by default to 5.
root@10.14.1.4:26257/defaultdb> ALTER RANGE default CONFIGURE ZONE USING num_replicas=5; CONFIGURE ZONE 1 Time: 939ms total (execution 939ms / network 0ms) root@10.14.1.4:26257/defaultdb>
With the following query we can verify if the tables from the Database are being replicated in five different nodes:
root@10.14.1.4:26257/defaultdb> SELECT start_pretty, end_pretty, database_name, table_name, replicas FROM crdb_internal.ranges_no_leases;
start_pretty | end_pretty | database_name | table_name | replicas
--------------------------------+-------------------------------+---------------+---------------------------------+--------------
/Min | /System/NodeLiveness | | | {2,3,4,6,9}
/System/NodeLiveness | /System/NodeLivenessMax | | | {2,3,4,7,8}
/System/NodeLivenessMax | /System/tsd | | | {2,3,7,8,9}
/System/tsd | /System/"tse" | | | {1,3,5,6,9}
/System/"tse" | /Table/SystemConfigSpan/Start | | | {4,5,6,7,8}
/Table/SystemConfigSpan/Start | /Table/11 | | | {2,3,4,6,8}
/Table/11 | /Table/12 | system | lease | {2,5,7,8,9}
/Table/12 | /Table/13 | system | eventlog | {2,5,7,8,9}
/Table/13 | /Table/14 | system | rangelog | {1,2,3,7,9}
/Table/14 | /Table/15 | system | ui | {1,4,6,8,9}
/Table/15 | /Table/16 | system | jobs | {3,4,5,6,7}
/Table/16 | /Table/17 | | | {2,3,4,8,9}
/Table/17 | /Table/18 | | | {1,2,3,4,9}
/Table/18 | /Table/19 | | | {1,2,3,7,9}
/Table/19 | /Table/20 | system | web_sessions | {1,3,4,5,7}
/Table/20 | /Table/21 | system | table_statistics | {5,6,7,8,9}
/Table/21 | /Table/22 | system | locations | {2,4,5,8,9}
/Table/22 | /Table/23 | | | {1,3,4,5,6}
/Table/23 | /Table/24 | system | role_members | {2,4,6,8,9}
/Table/24 | /Table/25 | system | comments | {1,2,3,5,7}
/Table/25 | /Table/26 | system | replication_constraint_stats | {1,2,6,8,9}
/Table/26 | /Table/27 | system | replication_critical_localities | {1,2,4,6,7}
/Table/27 | /Table/28 | system | replication_stats | {1,5,6,7,9}
/Table/28 | /Table/29 | system | reports_meta | {1,3,4,5,7}
/Table/29 | /NamespaceTable/30 | | | {1,3,5,6,7}
/NamespaceTable/30 | /NamespaceTable/Max | system | namespace | {4,5,6,7,8}
/NamespaceTable/Max | /Table/32 | system | protected_ts_meta | {2,3,4,6,7}
/Table/32 | /Table/33 | system | protected_ts_records | {1,3,4,5,9}
/Table/33 | /Table/34 | system | role_options | {2,4,5,7,8}
/Table/34 | /Table/35 | system | statement_bundle_chunks | {1,2,3,4,6}
/Table/35 | /Table/36 | system | statement_diagnostics_requests | {3,4,5,6,8}
/Table/36 | /Table/37 | system | statement_diagnostics | {1,2,5,7,8}
/Table/37 | /Table/38 | system | scheduled_jobs | {1,3,4,5,7}
/Table/38 | /Table/39 | | | {1,2,6,8,9}
/Table/39 | /Table/40 | system | sqlliveness | {2,6,7,8,9}
/Table/40 | /Table/41 | system | migrations | {1,5,6,7,9}
/Table/41 | /Table/42 | system | join_tokens | {1,5,6,8,9}
/Table/42 | /Table/43 | system | statement_statistics | {1,2,4,6,9}
/Table/43 | /Table/44 | system | transaction_statistics | {2,3,7,8,9}
/Table/44 | /Table/45 | system | database_role_settings | {1,5,7,8,9}
/Table/45 | /Table/46 | system | tenant_usage | {1,3,4,5,6}
/Table/46 | /Table/47 | system | sql_instances | {3,5,6,8,9}
/Table/47 | /Table/50 | system | span_configurations | {2,4,6,7,8}
/Table/50 | /Max | system | tenant_settings | {1,2,3,5,9}
(44 rows)
Time: 129ms total (execution 127ms / network 1ms)
root@10.14.1.4:26257/defaultdb>
We can now confirm the data is now being replicated from 3 to 5 nodes.
If we stop the three nodes of the Europe-Southwest Region, and we check the cluster Console, we will see the nodes will be marked as “Suspect Nodes”. And the data handled by those nodes wil l be showed as “Under-replicated”.
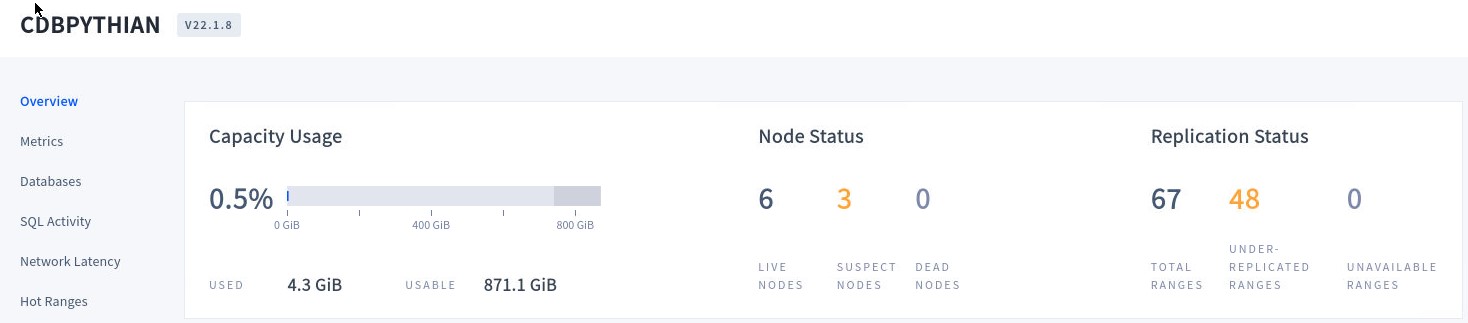
As soon a node is marked as “Suspect” the cluster will wait 5 minutes by default before considering it dead, at which point the cluster will automatically repair itself by re-replicating any of the replicas on the down nodes to other available nodes. Any connection working on the failed nodes will be redirected to the available node with the better network latency and the cluster will continue to work without issues. After 5 minutes, if the nodes are not able to recover, they will be marked as “Dead” by the cluster. The “Under-replicated” data will be replicated across the available nodes.
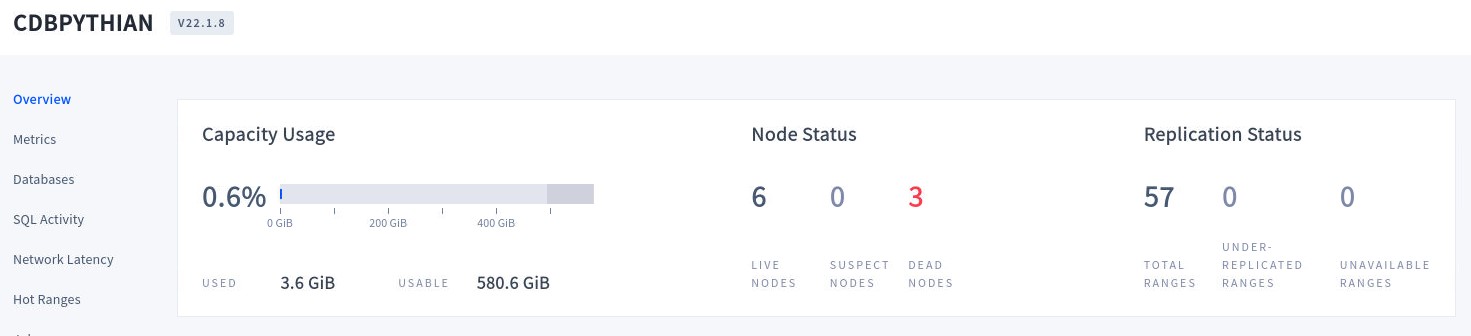
All the data is now replicated. You can now decide to recover the failed nodes, or just decommission the nodes to add new nodes in the same or different region. If the nodes recover, the cluster will automatically recover to the pre-failure status.
Scale
One of the great features of CockroachDB is that it can scale easily. We saw it during our cluster creation, we manage to create 9 nodes with a few steps and in a short period of time. You can scale a cluster in the case you need more resources in a particular Zone/Region or if you want to have a dedicated node for a new Region. Adding or removing nodes from a Cluster is going to add some load to the cluster since its going to have to replicate data across the nodes. If you can, try to perform these tasks when there isn’t heavy traffic. If your cluster needs more resources its generally more effective to increase the size of the nodes, before adding new ones. For example, if you have a cluster with 3 nodes of 4vCPUs each, consider scaling up to 8vCpus before adding a fourth node. If you decide that adding a new node is more convenient for your solution, just use the same steps we used to create the cluster, using the Machine Image template and GCP commands to deploy new nodes. You would be able to spin-up a new node in less than 5 minutes.
Removing and adding nodes from the cluster on demand can reduce costs during the quiet times and maintain performance and availability during heavy-load periods. These can be scripted and scheduled to reduce the managing effort.
Conclusion
During the blog series we were able to see how easy is to deploy a CockroachDB cluster in GCP that is resilient and distributed. We covered all the GCP infrastructure creation and how to create the cluster with a few commands. We also reviewed some of its most important features, but there are many more to play around.
It provides a simple solution on areas where other offerings add more complexity, making it easier to deploy and manage. Im sure its going to continue getting more market share in the Database market while most of the workloads migrate to the cloud.
If you have any questions, or would like to know more about CockroachDB, please contact us.

