
The Levenshtein Distance, as discussed in my
last post, is a way to measure how far two strings are located from each other. There are several T-SQL implementations of this functionality, as well as many compiled versions. In addition, the MDS library in SQL Server has a
Similarity function which uses the Levenshtein Distance to find how similar two words are. In this post, I've done a simple comparison of performance using a C# CLR implementation of Levenshtein Distance (
The code is from the Wiki), and a well written T-SQL implementation from
Arnold Fribble. As many of you might expect, the C# implementation is much quicker. Needing only 2504 ms to run through dictionary table of 203,118 words. The T-SQL implementation took 42718 ms for the same work. [caption id="attachment_81563" align="alignnone" width="360"]
 Levenshtein Distance Comparison[/caption]
Levenshtein Distance Comparison[/caption]
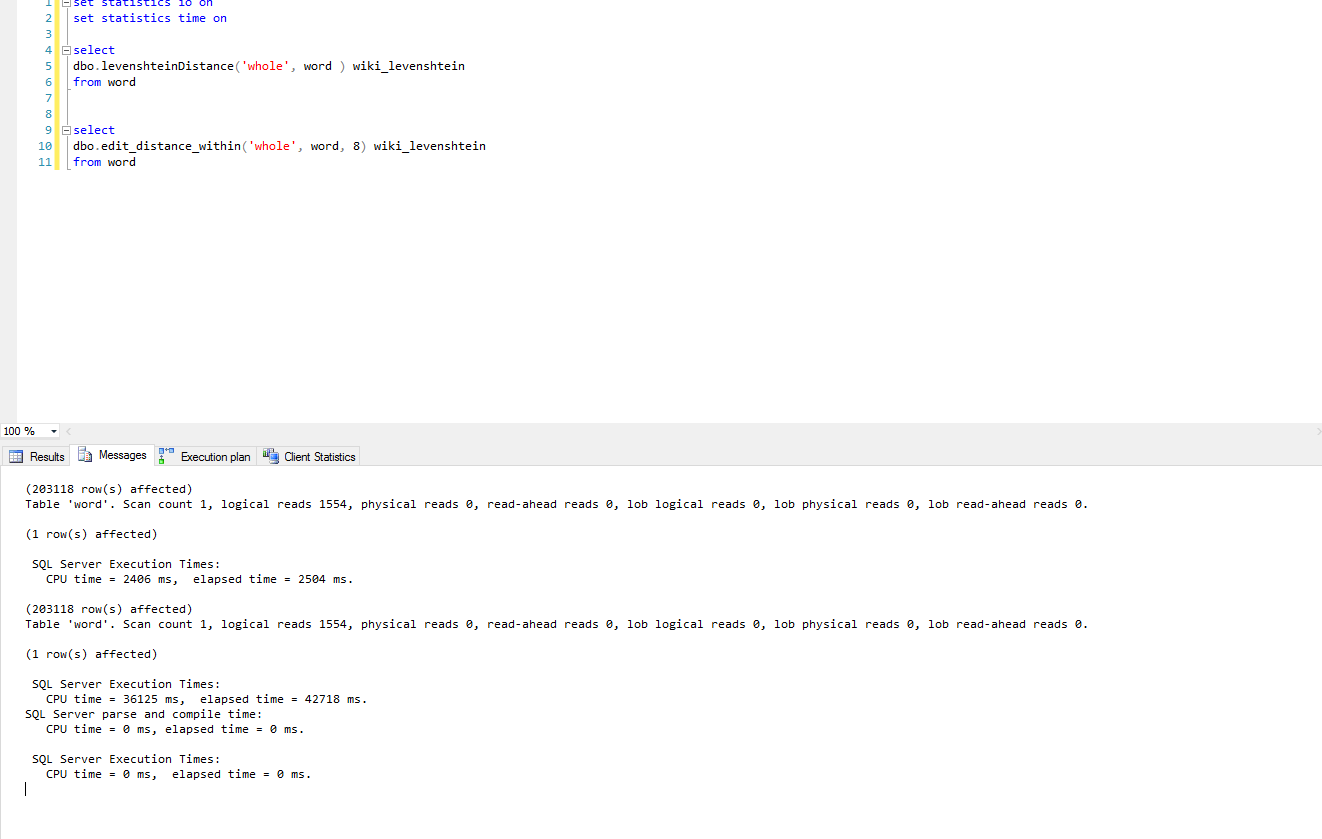 Levenshtein Distance Comparison[/caption]
Levenshtein Distance Comparison[/caption]


