
I published a blog post called "
Investigating IO Performance on Amazon RDS for Oracle" recently, and soon after posting it I received several questions asking if IO worked the same way on EC2 instances. My immediate though was it did, mostly because RDS for Oracle is basically an EC2 instance with Oracle Database on top of it, where the configuration is fully managed by Amazon. But as always, it's better to test than assume, so here we go!
Although the testing was done by running a workload in an Oracle database, the results will apply to any other type of workload because the performance characteristics purely depend on the type of instance, type of EBS volume and the size of the IO requests, and it doesn't matter how the data is processed after it's retrieved from the storage.
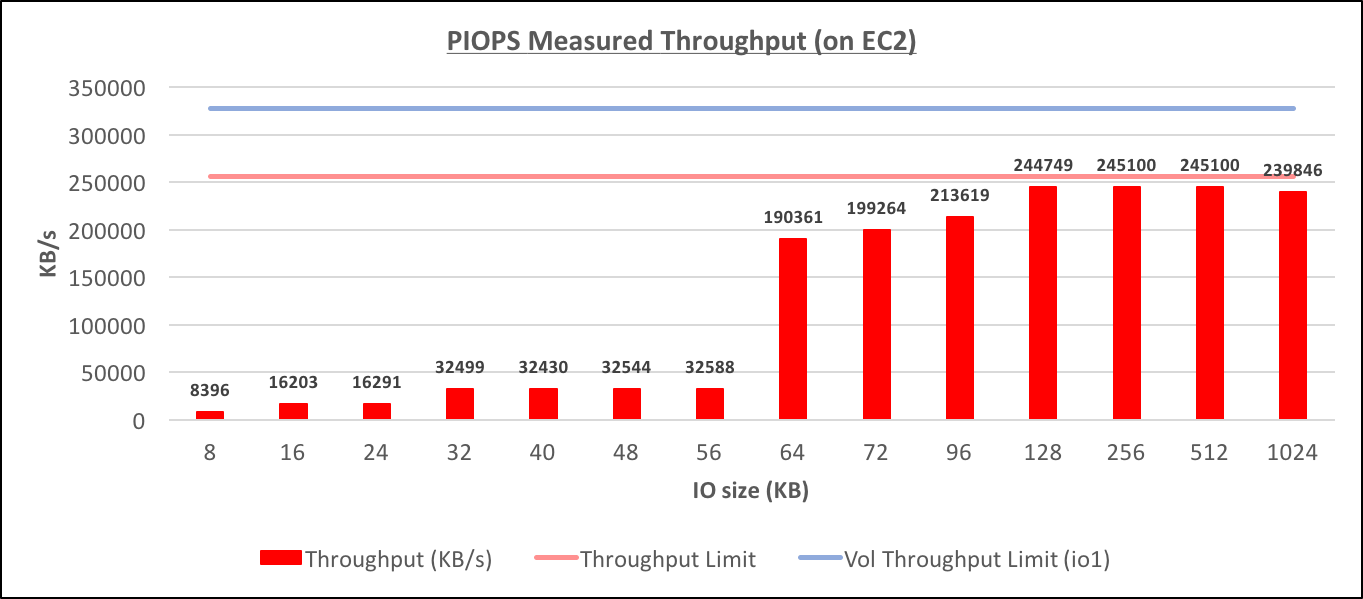 Provisioned IOPS Throughput (on EC2)[/caption] [caption id="attachment_95855" align="aligncenter" width="1362"]
Provisioned IOPS Throughput (on EC2)[/caption] [caption id="attachment_95855" align="aligncenter" width="1362"]
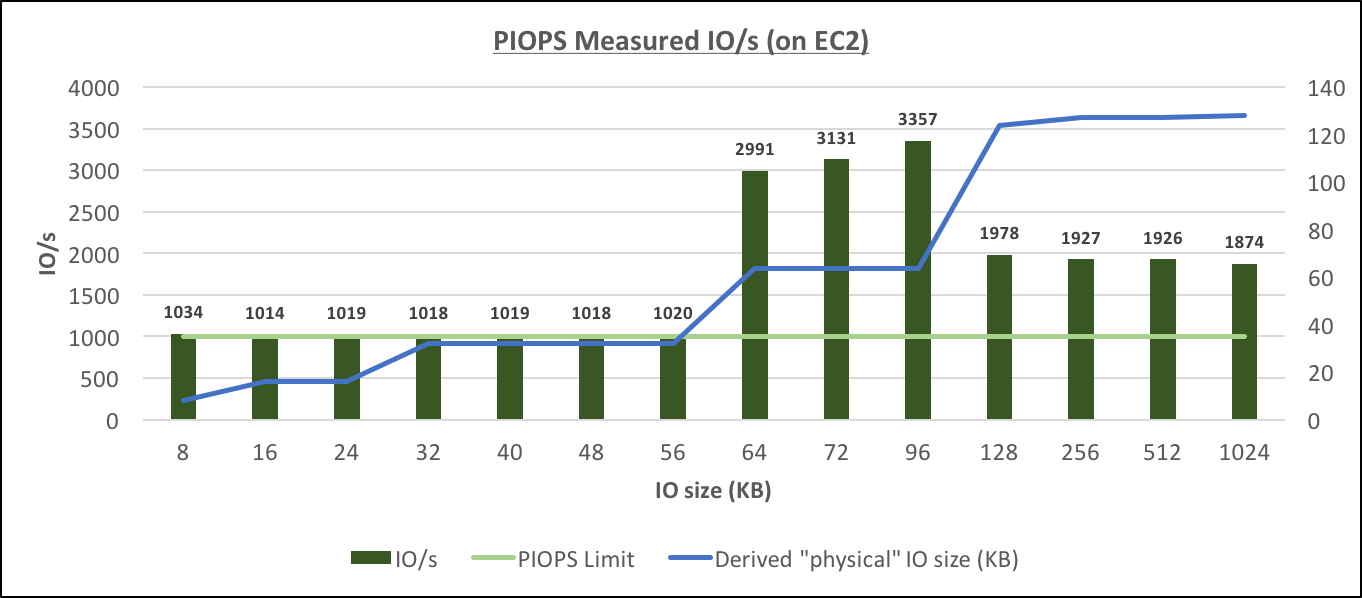 Provisioned IOPS Measured IO/s (on EC2)[/caption] These results confirm that (the same as with RDS), there are several sizes of physical IOs: (8), 16, 32, 64 and 128, and starting with 64K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
Provisioned IOPS Measured IO/s (on EC2)[/caption] These results confirm that (the same as with RDS), there are several sizes of physical IOs: (8), 16, 32, 64 and 128, and starting with 64K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
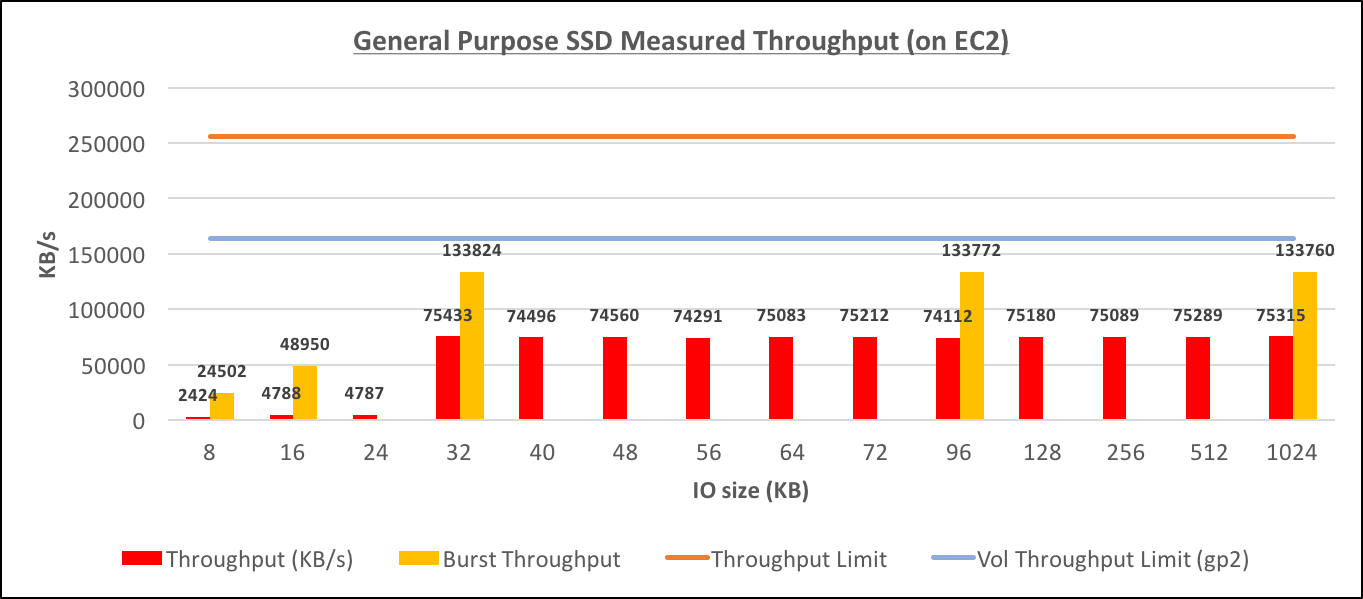 General Purpose SSD Throughput (on EC2)[/caption] [caption id="attachment_95887" align="aligncenter" width="1362"]
General Purpose SSD Throughput (on EC2)[/caption] [caption id="attachment_95887" align="aligncenter" width="1362"]
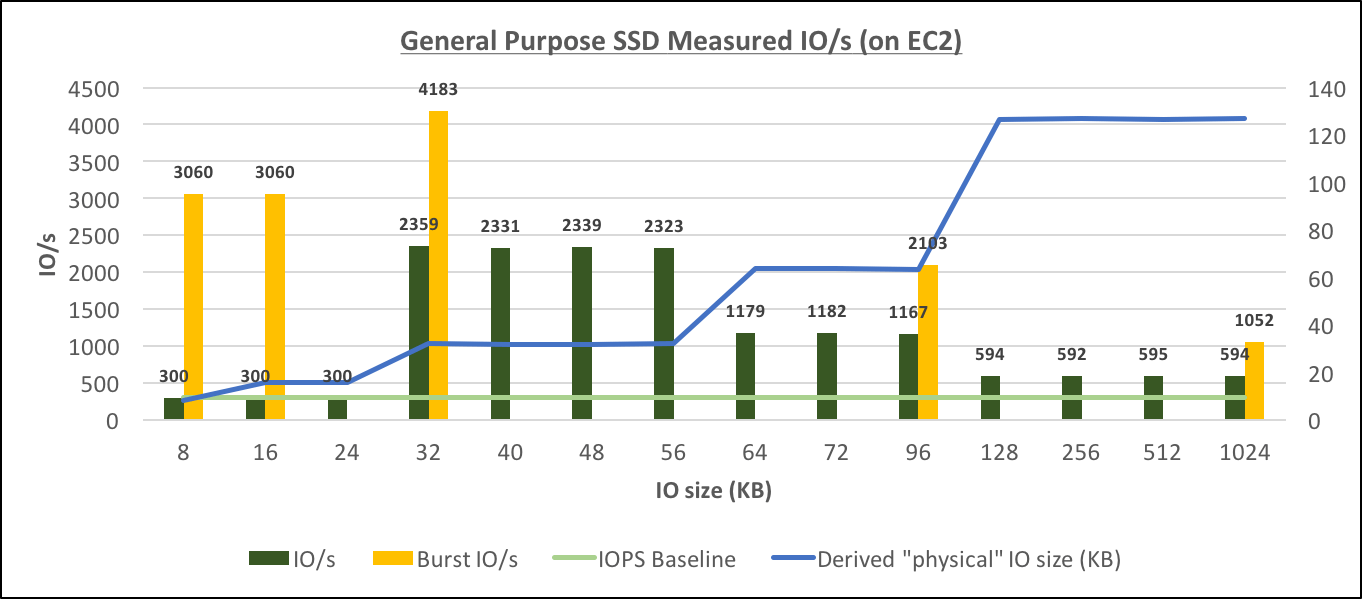 General Purpose SSD Measured IO/s (on EC2)[/caption] These results also confirm that (the same as with RDS), there are several sizes of physical IOs: 16, 32, 64 and 128, and starting with 32K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
General Purpose SSD Measured IO/s (on EC2)[/caption] These results also confirm that (the same as with RDS), there are several sizes of physical IOs: 16, 32, 64 and 128, and starting with 32K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
The Testing
The testing was done exactly the same way as described in the previous blog post, the only difference was that I had to create an oracle database manually by myself. I used the 12.1.0.2.0 database Enterprise Edition and ASM, and the EBS volume was used as an ASM disk.Measuring the IO performance
On RDS we had the nice Enhanced Monitoring which I set up with a refresh interval of a few seconds and I used it to collect performance statistics quickly. For EC2 (specifically for EBS volumes), there is no such thing as enhanced monitoring, so I needed to use the standard CloudWatch monitoring with the minimum refresh rate of 5 minutes (very inconvenient, because a single test case would have to be run for 5 to 10 minutes to collect reliable data). This was not acceptable, so I looked for alternatives and found thatiostat displayed the same values the monitoring graphs did:
[root@ip-172-31-21-241 ~]# iostat 5 500 ... avg-cpu: %user %nice %system %iowait %steal %idle 0.32 0.00 0.11 0.11 0.43 99.04 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn xvda 0.00 0.00 0.00 0 0 xvdf 0.40 0.00 8.00 0 40 xvdg 3060.00 24496.00 14.40 122480 72 ...the "tps" showed IO per second, and "kB_read/s"+"kB_wrtn/s" allowed me to calculate the throughput (I actually ended up using just the kB_read/s as my workload was 100% read only and the values in kB_wrtn/s were tiny).
iostat is even more convenient to use than the
enhanced monitoring, it didn't take long to see the first benefit of EC2 over RDS!
The Results
It was no surprise, the outcome of testing on EC2 was quite similar to the results from testing on RDS.Provisioned IOPS Storage on an EC2 Instance
As on RDS, the testing was done on db.m4.4xlarge with 100G of io1 with 1000 provisioned IO/s. Also the results are very very similar, the only notable difference that I could observe (although I can't explain it, and I'm not sure there is a pattern in it or not, as I did't do too many tests), was the fact that the throughput for 64K-96K IOs didn't reach the same level as 128K+ IOs. [caption id="attachment_95857" align="aligncenter" width="1363"]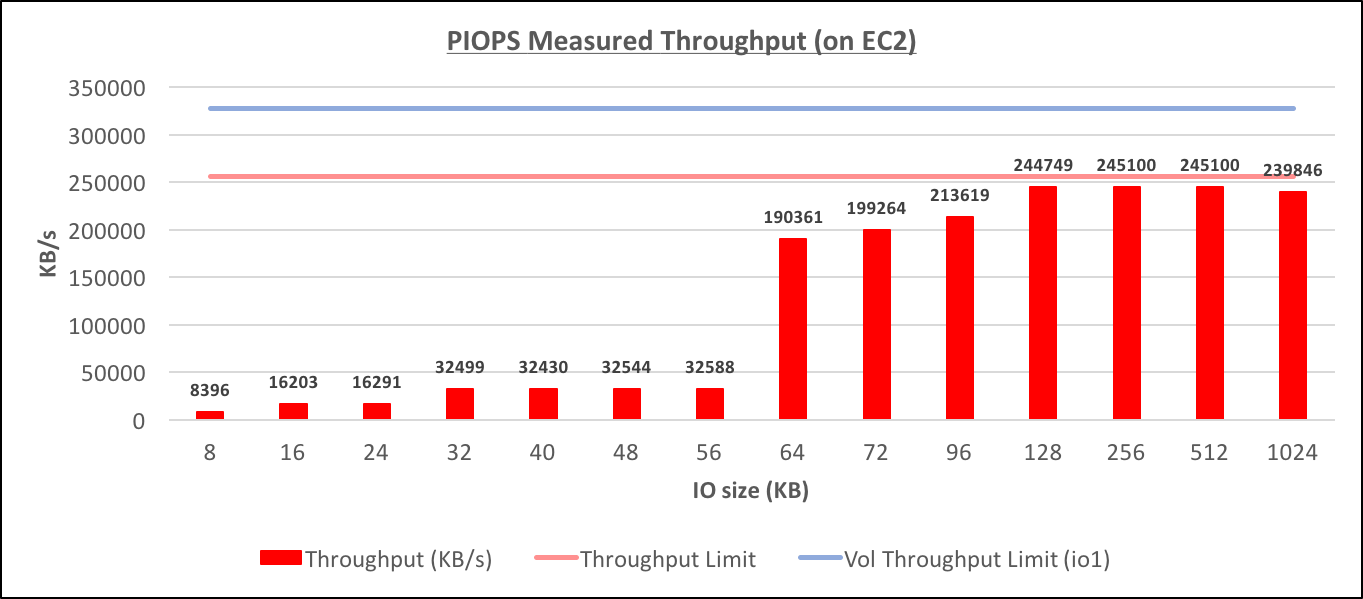 Provisioned IOPS Throughput (on EC2)[/caption] [caption id="attachment_95855" align="aligncenter" width="1362"]
Provisioned IOPS Throughput (on EC2)[/caption] [caption id="attachment_95855" align="aligncenter" width="1362"]
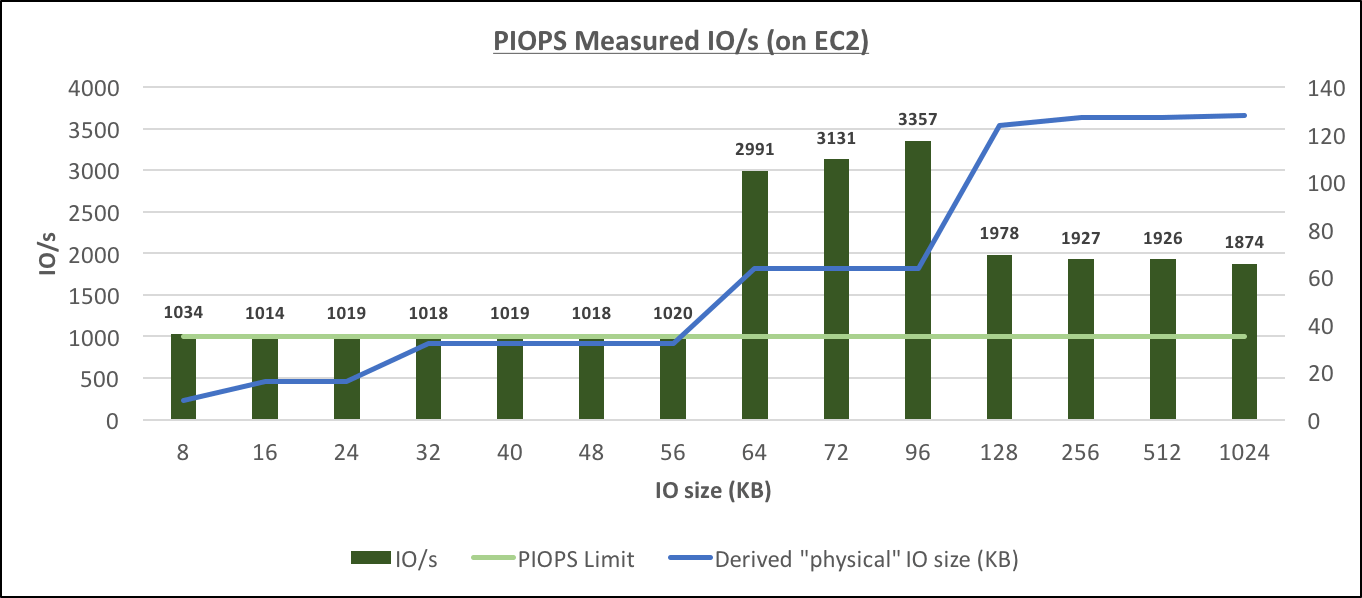 Provisioned IOPS Measured IO/s (on EC2)[/caption] These results confirm that (the same as with RDS), there are several sizes of physical IOs: (8), 16, 32, 64 and 128, and starting with 64K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
Provisioned IOPS Measured IO/s (on EC2)[/caption] These results confirm that (the same as with RDS), there are several sizes of physical IOs: (8), 16, 32, 64 and 128, and starting with 64K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
General Purpose Storage on an EC2 Instance
The testing with General Purpose SSDs (100G with 300 baseline IOPS) didn't provide any surprises and the results were exactly the same as for RDS. The only difference in the graphs is the "bust performance" measures for IOs of different sizes that I've added to outline how the "bursting" improves both IO/s and Throughput. [caption id="attachment_95853" align="aligncenter" width="1363"]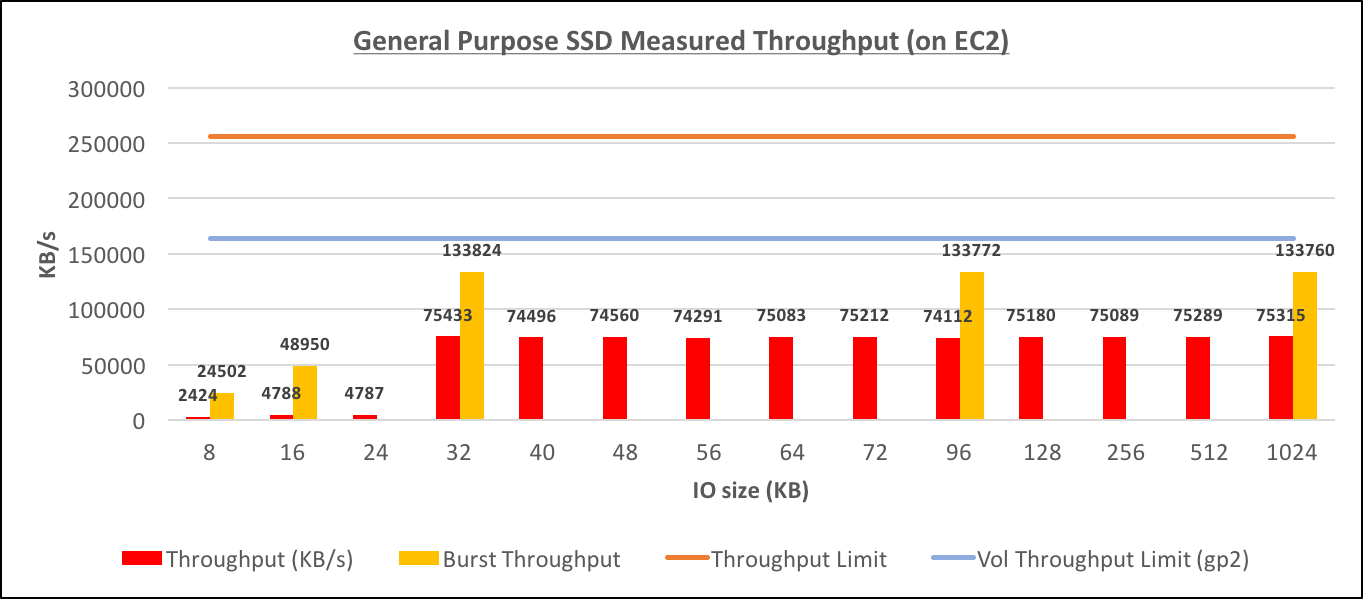 General Purpose SSD Throughput (on EC2)[/caption] [caption id="attachment_95887" align="aligncenter" width="1362"]
General Purpose SSD Throughput (on EC2)[/caption] [caption id="attachment_95887" align="aligncenter" width="1362"]
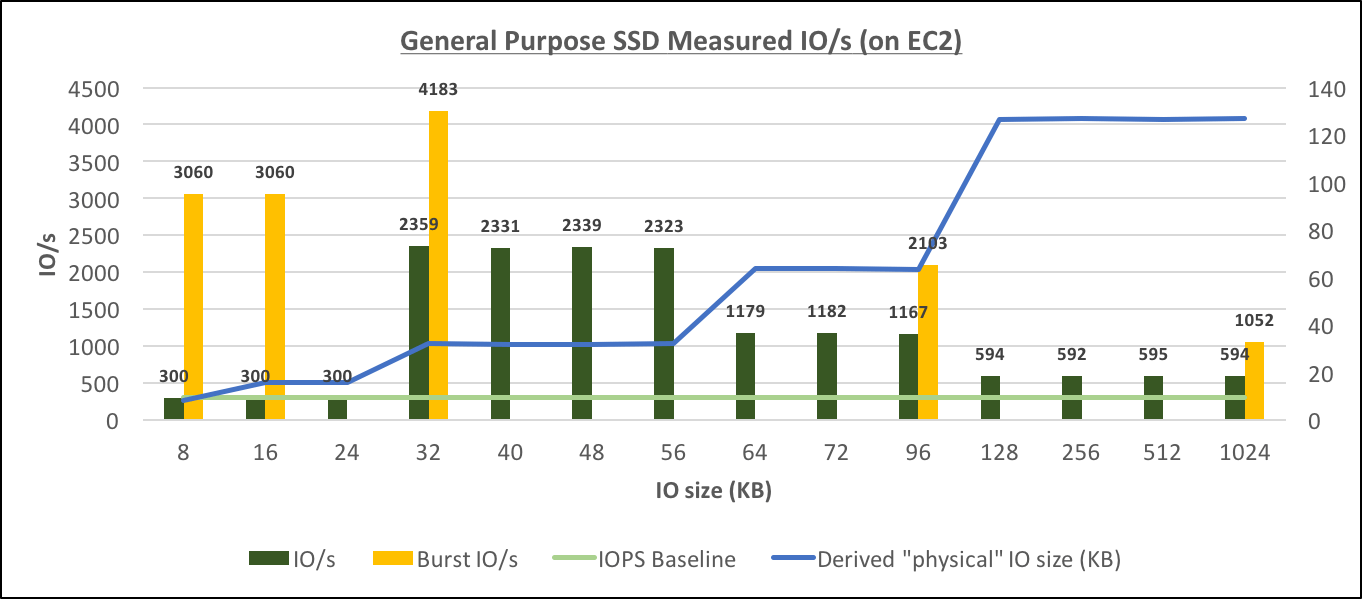 General Purpose SSD Measured IO/s (on EC2)[/caption] These results also confirm that (the same as with RDS), there are several sizes of physical IOs: 16, 32, 64 and 128, and starting with 32K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
General Purpose SSD Measured IO/s (on EC2)[/caption] These results also confirm that (the same as with RDS), there are several sizes of physical IOs: 16, 32, 64 and 128, and starting with 32K, the performance is throughput-bound, but with IOs of smaller size, it's IOPS-bound.
Additional Flexibility with EC2
Using Multiple gp2 Volumes
Opposite to RDS, I can configure my storage and instance more freely, so instead of having just a single gp2 volume attached to it I added five 1G-sized (yes tiny) volumes to the +DATA disk group. the minimum IOPS for a gp2 volume is 100, so my 5 volumes gave cumulative 500 baseline IOPS. As ASM was used, the IOs were +/- evenly distributed between the volumes. I didn't do too thorough testing, but still I noticed a few things. Take a look at theseiostat outputs from testing done with 8K reads (this is burst performance):
[root@ip-172-31-21-241 ~]# iostat 5 500 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn xvda 0.00 0.00 0.00 0 0 xvdf 3.40 0.00 16.80 0 84 xvdg 1203.40 9632.00 1.60 48160 8 xvdi 1199.60 9596.80 0.00 47984 0 xvdj 1211.60 9691.20 3.20 48456 16 xvdk 1208.60 9670.40 0.00 48352 0 xvdl 1203.00 9625.60 3.20 48128 16
- Bursting performance applies to each volume separately. It should allow getting up to 3000 IOPS per volume, but I reached only ~1200 per volume with cumulative throughput of 48214 KB/s (not even close to the limit). So there's some other limit or threshold that applies to this configuration (and it's not the CPU). But look! I've got 6024 IO/s burst performance, which is quite remarkable for just 5G.
- As I was not hitting the maximum 3000 bursting IOPS per volume, the burst credit was running out much slower. if it lasts normally ~40 minutes at 3000 IOPS, it lasts ~3 times longer at ~1200 IOPS, which would allow running at better performance longer (i.e if one used 5x2G volumes instead of 1x10G volume)
iostat output is from testing done with 1M reads (this is burst performance):
[root@ip-172-31-21-241 ~]# iostat 5 500 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn xvda 0.00 0.00 0.00 0 0 xvdf 3.40 0.00 16.80 0 84 xvdg 384.40 48820.80 0.80 244104 4 xvdi 385.80 49155.20 0.00 245776 0 xvdj 385.00 49014.40 6.40 245072 32 xvdk 386.80 49225.60 0.00 246128 0 xvdl 385.00 48897.60 6.40 244488 32
- The cumulative throughput is 245111 KB/s, which is very close to the throughput limit of the instance. I wasn't able to reach such throughput on a single volume of gp2, where the maximum I observed was just 133824 KB/s, and 163840 KB/s is a throughput limit for a single gp2 volume which was bypassed too. It appears that configuring multiple volumes allows reaching the instance throughput limit that was not possible with a single volume.
Database with a 32K Block Size
We have observed that starting with 32K block reads the EBS volume become's throughput-bound, not IOPS-bound. Obviously I wanted to see how it performed if the database was created with a 32K block size. I ran a few very simple tests using 1 data block sized IOs (32K) on these two configurations:- db.m4.4xlarge with 100G / 1000 PIOPS (io1)
- db.m4.4xlarge with 20G / 100 IOPS (gp2)
- During burst period I measured up to 4180 IO/s at 133779 KB/s, which was 4 times faster than Provisioned SSD.
- During non-burst period I measured up to 764 IOs at 24748 KBs/s throughput. Which is somewhat slower than Provisioned SSD. Also 24748 KBs/s, was slower than the throughput I measured on a 100G gp2 volume (we already ow that the non-burst throughput limit for gp2 depends on the size of the disk). If I used a 100G gp2 volume, I'd get 2359 IO/s at 75433 KB/s (this is from the graph above), which is also better that what one can get from a Provisioned SSD volume, and costs less.


