
Recently I was working with a Redshift cluster located in one of the west AWS regions and was asked if we could move the data to the east region. So, I started to move the required data over. The task looks more or less simple enough if you need to move one table data but it can be tricky if you have to move multiple tables. I will try to describe some ways I used to copy the Redshift data.
Let's start from a simple case when you need to move one or a couple of tables. In this case you may just use the unload procedure from your database to a S3 bucket. Let's assume we have a S3 bucket 's3://source-stage/misc/redshift_upload/' . The command is simple and depending from size of the source table(s) you can use a nonparallel option for the 'UNLOAD' command like :
unload ('select * from user_account') to 's3://source-stage/misc/redshift_upload/user_account_' credentials 'aws_access_key_id=########################;aws_secret_access_key=######################' parallel off;
It will create a file with the name "user_account_000" in the bucket on your S3 storage in the same region where your source Redshift cluster is located. In our case it was us-west-1 (Oregon). You also can see that I've disabled parallel explicitly. The parallel option is on by default and it unloads to one (or more) file per slice.
In case of a big table it is recommended to use parallelism and add a manifest file with all uploaded files listed there. The command is:
unload ('select * from user_account') to 's3://source-stage/misc/redshift_upload/user_account_' credentials 'aws_access_key_id=########################;aws_secret_access_key=######################' manifest;
And here you can see what you get on S3 after that:
2016-11-15 10:43:29 673248 user_account_0000_part_00
2016-11-15 10:43:29 671656 user_account_0001_part_00
2016-11-15 10:43:29 200 user_account_manifest
You see that I got two files according to number of slices in my cluster and each file has one part. If a part for a file exceeds 6.2 Gb you are getting more than one part per slice with name ending by *_part_02, *_part_03 etc. The user_account_manifest file contains list of all the parts for the uploaded table:
{
"entries": [
{"url":"s3://source-stage/misc/redshift_upload/user_account_0000_part_00"},
{"url":"s3://source-stage/misc/redshift_upload/user_account_0001_part_00"}
]
}
The data in the user_account_0000_part* files by default will be in flat text delimited by "|" sign. You can change the default delimiter using "DELIMITER" option. Also I strongly recommend to use "ESCAPE" option if you have even slightest possibility to have any characters like your delimiter, carriage return, quote or escape character in your text data. If you do not do that you may not be able to copy the data back from your export.
So, having uploaded the data to the S3 we need now to copy it to our target database in the east region. But before copying the data we need to create the table. You can get DDL for the table using a v_generate_tbl_ddl view prepared by AWS team and located on GitHub along with other useful utilities. Using the code from GitHub you can create the view on the source database and extract DDL for your table(s) issuing a statement like:
select ddl from v_generate_tbl_ddl where tablename='user_accounts' and schemaname = 'public' order by seq;
It will give you full DDL statement to run on the target to create the destination table.
After creating the table on the target we can copy the data from our S3 storage. It is simple enough and you can use the 'COPY' command for that using a statement for a single file like:
copy user_account from 's3://wheelsup-source-stage/misc/redshift_upload/user_account_000' credentials 'aaws_access_key_id=########################;aws_secret_access_key=######################'' region 'us-west-2';
or for the multiple files :
copy user_account from 's3://wheelsup-source-stage/misc/redshift_upload/user_account_manifest' credentials 'aaws_access_key_id=########################;aws_secret_access_key=######################'' manifest region 'us-west-2';
You have noticed I explicitly added the region to the command because by default it will try to search files in the home region and your target cluster may not be in the same region where the files were uploaded.
The described method works pretty well when you need to copy only a couple of tables. But when you start to move tens or hundreds of tables the way doesn't look too simple at all. The unload command doesn't allow you to upload all tables for entire schema and the ddl extract is not perfect too. So for multiple tables it requires a lot of effort to unload, generate ddl and copy data. A simple export and import utility would be extremely handy here. I used a sql to generate a script to unload the data :
select 'unload ('''|| table_name ||') to ''s3://wheelsup-source-stage/misc/redshift_upload/'||table_name||'_'' credentials ''aws_access_key_id=########################;aws_secret_access_key=######################'' manifest;'
from (select distinct table_name from information_schema.columns where table_schema = 'public') ORDER BY table_name;
And uploaded DDL for all tables using :
select ddl from v_generate_tbl_ddl where schemaname = 'public' order by tablename,seq;
After that I ran the DDL script on the target and generated another script to load the data using the same approach:
select 'copy '|| table_name ||' from ''s3://wheelsup-source-stage/misc/redshift_upload/'|| table_name||'_manifest'' credentials ''aws_access_key_id=########################;aws_secret_access_key=######################'' manifest region ''us-west-2'';'
from (select distinct table_name from information_schema.columns where table_schema = 'public') ORDER BY table_name;
Using the generated scripts I moved the data but hit few issues. The first problem was related to default delimiter '|'. Values for some of my columns had the character and it broke the load. The 'ESCAPE' clause for the unload command should help me to prevent the issue. With the 'ESCAPE' clause an escape character (\) would be placed before any occurrence of quotes, carriage returns or delimiter characters. The second issue was with wrong data types for some tables in my DDL script and should fix it. As example I got a 'TIMESTAMP WITHOUT TIME ZONES' instead of original 'FLOAT4'. Nevertheless the method worked for me and I was able to move all the data.
The procedure of moving the tables looks bit cumbersome and long. Can you imagine if you need to move entire database with hundreds of tables? In this case way more acceptable way is to copy entire cluster to the different region. According to documentation it looks easy enough. You need to copy an automated or manual snapshot to another region and restore your cluster there. But when you try to copy snapshot from the snapshots page it doesn't provide such option. You can make a copy of an automated snapshot but it will be located in the same region: 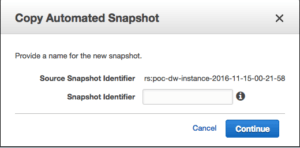 And you don't have an option to copy your manual snapshot at all. So, what you need is to go to cluster configuration page and click on the "Backup" and choose "Configure Cross-Region Snapshots":
And you don't have an option to copy your manual snapshot at all. So, what you need is to go to cluster configuration page and click on the "Backup" and choose "Configure Cross-Region Snapshots": 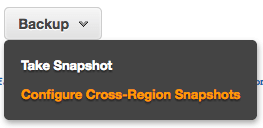 There you can choose the desired region and after that all snapshots whether they are automated or manual will be copied over to the destination region. On the Redshift service page for the destination region you will be able to find the copy of the snapshots. As soon as you have the snapshot you can easy restore full cluster with all the data. You will be able to rename the cluster when you restore it. Short summary. It is not difficult to move a coupe of tables but it requires some effort and manual scripting when you need to move more than that. It would be great to have an export utility to move data along with DDL in one file. Also in my opinion some things should be noted more clearly in documentation. It would be great to have some warnings about "ESCAPE" clause to be placed on the top of main help page and included to the examples for unloading data. And the documentation about copying Redshift snapshots to different region has to be fixed because now it is not fully correct.
There you can choose the desired region and after that all snapshots whether they are automated or manual will be copied over to the destination region. On the Redshift service page for the destination region you will be able to find the copy of the snapshots. As soon as you have the snapshot you can easy restore full cluster with all the data. You will be able to rename the cluster when you restore it. Short summary. It is not difficult to move a coupe of tables but it requires some effort and manual scripting when you need to move more than that. It would be great to have an export utility to move data along with DDL in one file. Also in my opinion some things should be noted more clearly in documentation. It would be great to have some warnings about "ESCAPE" clause to be placed on the top of main help page and included to the examples for unloading data. And the documentation about copying Redshift snapshots to different region has to be fixed because now it is not fully correct.


