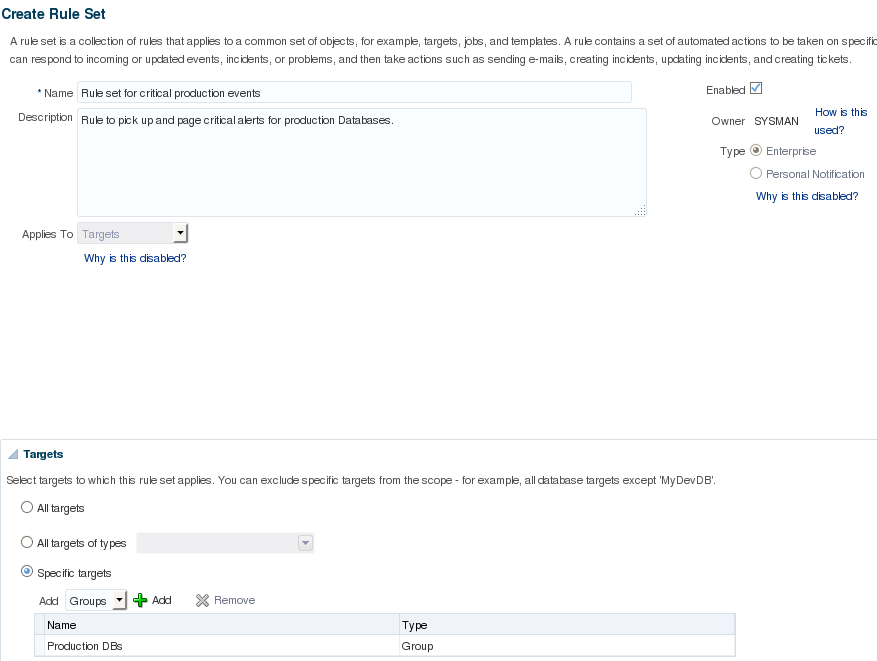
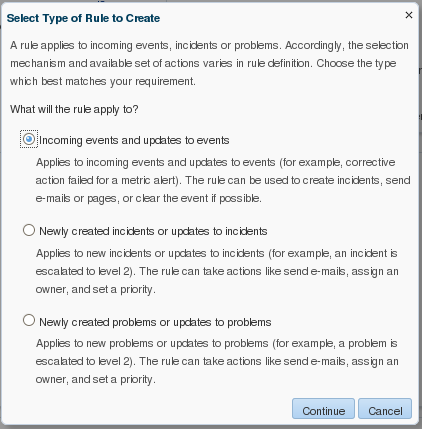
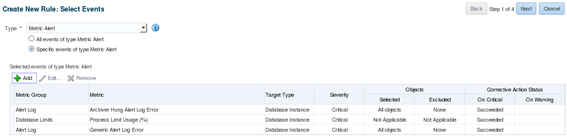
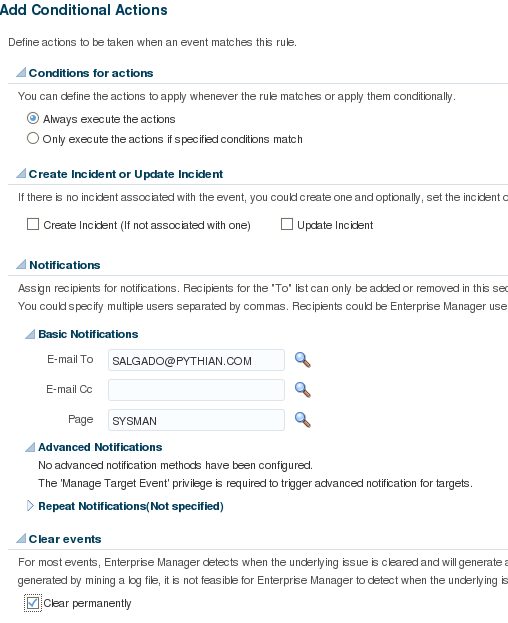
This is the first in a series of blog posts covering the most important topics you should know to completely monitor your IT infrastructure with Oracle Enterprise Manager Cloud Control 13c. Oracle Enterprise Manager (OEM) offers solid monitoring capabilities with various built-in metrics, as well extended metrics, which allows OEM to monitor virtually anything, and gives the possibility of creating additional metrics using SQL (PL/SQL) or any type of server scripting language, like shell, MS-DOS batch files, etc.
Overview
To take advantage of OEM's monitoring tools, it's important to set it up according to your needs. In terms of basic monitoring, these are the most important items you'll have to go through to make sure you're properly monitoring your IT environment:- Target groups
- Metrics and thresholds
- Monitoring templates
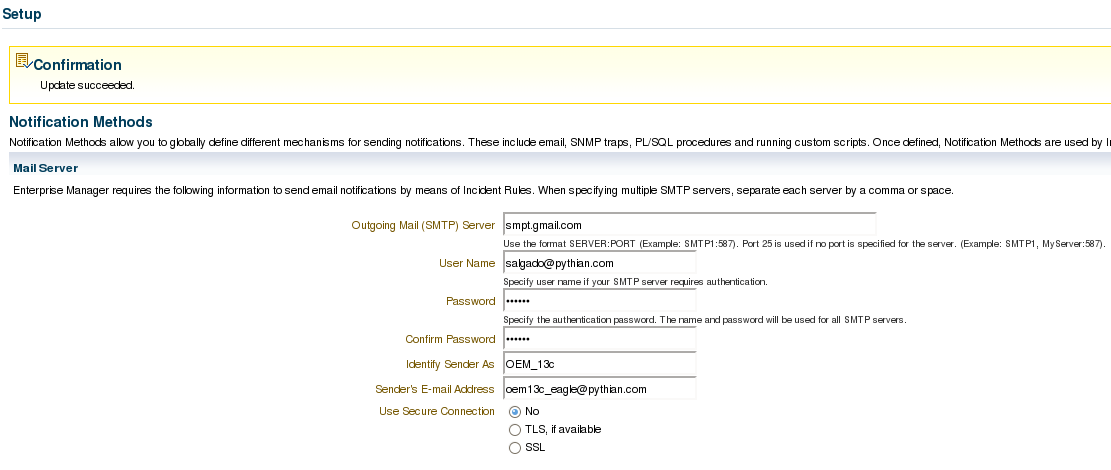
- Notification methods
- Incident rules
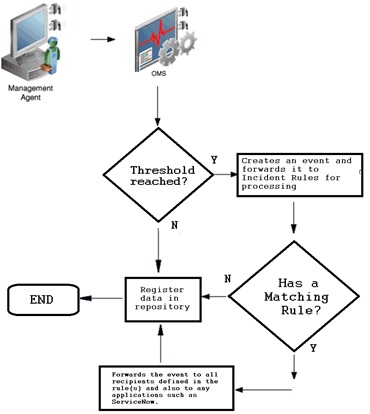
Basic monitoring features
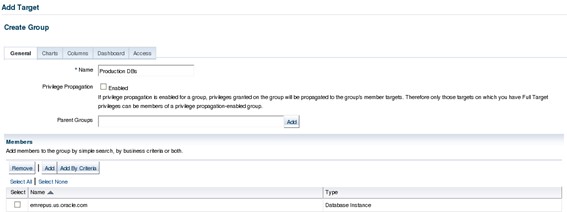
To send proper notification, OEM uses metrics thresholds and incident rules. To properly monitor the IT environment with OEM, it's important to carefully select which metrics should be collected and on which targets. The best way to achieve this is by setting up different target groups and monitoring templates. Depending on the needs of each target, there's usually a group for production targets: one for development, and so on. But groups may be created based on other criteria such as database sizes, serviced applications, etc. Groups can be created on "Targets -> Groups" page: