In part 1, we defined and deployed two data services to Cloud Run. Each service provides endpoints that perform specific tasks, such as loading a file to BigQuery or running dbt models. In this post, we’ll define and deploy some Google Workflows to orchestrate those tasks.
Google Workflows
Google Workflows can be written in either YAML or JSON. The syntax allows you to define variables, control conditions and handle errors. It also comes with a small standard library of functions for text processing, http calls and logging among others. Moreover, it provides connectors that make it easier to access Google Cloud products within workflows. However, it doesn’t come with a scheduler, so you would need to use Google Cloud Scheduler to trigger recurring workflows. Check the documentation for more details.
bq-dbt-load-landing-table
The workflow orchestrates the loading of CSV files in GCS into the BigQuery bq_demo_ldg dataset. It consists of a main workflow and three subworkflows. The main workflow defines the steps to load a table and the subworkflows call the Cloud Run services and handle errors.
To start, the getSourceDefinition step calls the bq-dbt-svc service to get the load config and column layout for the table to load. The response from the service is stored in the dbtServiceResponse variable. If no errors occur, execution passes to the loadBQTable step, which calls the bq-load-svc to load the table. Note that the dbtServiceResponse variable is passed as parameter to the callBQLoadService subworkflow, so that it can include the source_definition in the request to the service. The code below shows the definition for the bq-dbt-load-landing-table workflow:
# bq-dbt-load-landing-table.yml
main:
params: [args]
steps:
- start:
assign:
- dbtServiceUrl: "https://bq-dbt-svc-b7rdt3fiza-uc.a.run.app/source"
- bqLoadServiceUrl: "https://bq-load-svc-b7rdt3fiza-uc.a.run.app/load"
- getSourceDefinition:
call: callDbtService
args:
step: "getSourceDefinition"
url: ${dbtServiceUrl}
schemaFile: ${args.dbtSchemaFile}
sourceName: ${args.dbtSourceName}
tableName: ${args.dbtTableName}
result: dbtServiceResponse
- checkSourceDefinition:
call: raiseExceptionIfError
args:
step: "checkSourceDefinition"
response: ${dbtServiceResponse}
- loadBQTable:
call: callBQLoadService
args:
step: "loadBQTable"
url: ${bqLoadServiceUrl}
sourceDefinition: ${dbtServiceResponse.body.result.source_definition}
sourceFileUri: ${args.sourceFileUri}
bqProjectId: ${args.bqProjectId}
bqDatasetId: ${args.bqDatasetId}
result: bqLoadServiceResponse
- checkBQTable:
call: raiseExceptionIfError
args:
step: "checkBQTable"
response: ${bqLoadServiceResponse}
- finish:
steps:
- setReturnValue:
assign:
- returnValue: {}
- returnValue.status: "ok"
- returnValue.message: "Execution completed successfully."
- exit:
return: ${returnValue}
callDbtService:
params: [step, url, schemaFile, sourceName, tableName]
steps:
- logRequest:
call: sys.log
args:
text: ${"[" + step + "] Sending request to " + url + " -> " + schemaFile + "," + sourceName + "," + tableName}
- sendRequest:
call: http.get
args:
url: ${url}
auth:
type: OIDC
query:
schema_file: ${schemaFile}
source_name: ${sourceName}
table_name: ${tableName}
result: response
- logResponseStatus:
call: sys.log
args:
text: ${"[" + step + "] Response status :" + " " + response.body.result.status}
- returnResponse:
return: ${response}
callBQLoadService:
params: [step, url, sourceDefinition, sourceFileUri, bqProjectId, bqDatasetId]
steps:
- logRequest:
call: sys.log
args:
text: ${"[" + step + "] Sending request to " + url + " -> " + sourceDefinition.name + "," + sourceFileUri}
- sendRequest:
call: http.post
args:
url: ${url}
auth:
type: OIDC
body:
params:
source_definition: ${sourceDefinition}
source_file_uri: ${sourceFileUri}
project_id: ${bqProjectId}
dataset_id: ${bqDatasetId}
result: response
- logResponseStatus:
call: sys.log
args:
text: ${"[" + step + "] Response status :" + " " + response.body.result.status}
- returnResponse:
return: ${response}
raiseExceptionIfError:
params: [step, response]
steps:
- verifyResponse:
switch:
- condition: ${response.body.result.status != "ok"}
steps:
- exit:
raise:
status: ${response.body.result.status}
step: ${step}
output: ${response.body.result.command_output}
message: ${response.body.result.message}
After deploying a workflow to Google Cloud Platform (GCP), you can see its visual representation in the GCP console. The screenshot below shows the graph for the bq-dbt-load-landing-table workflow: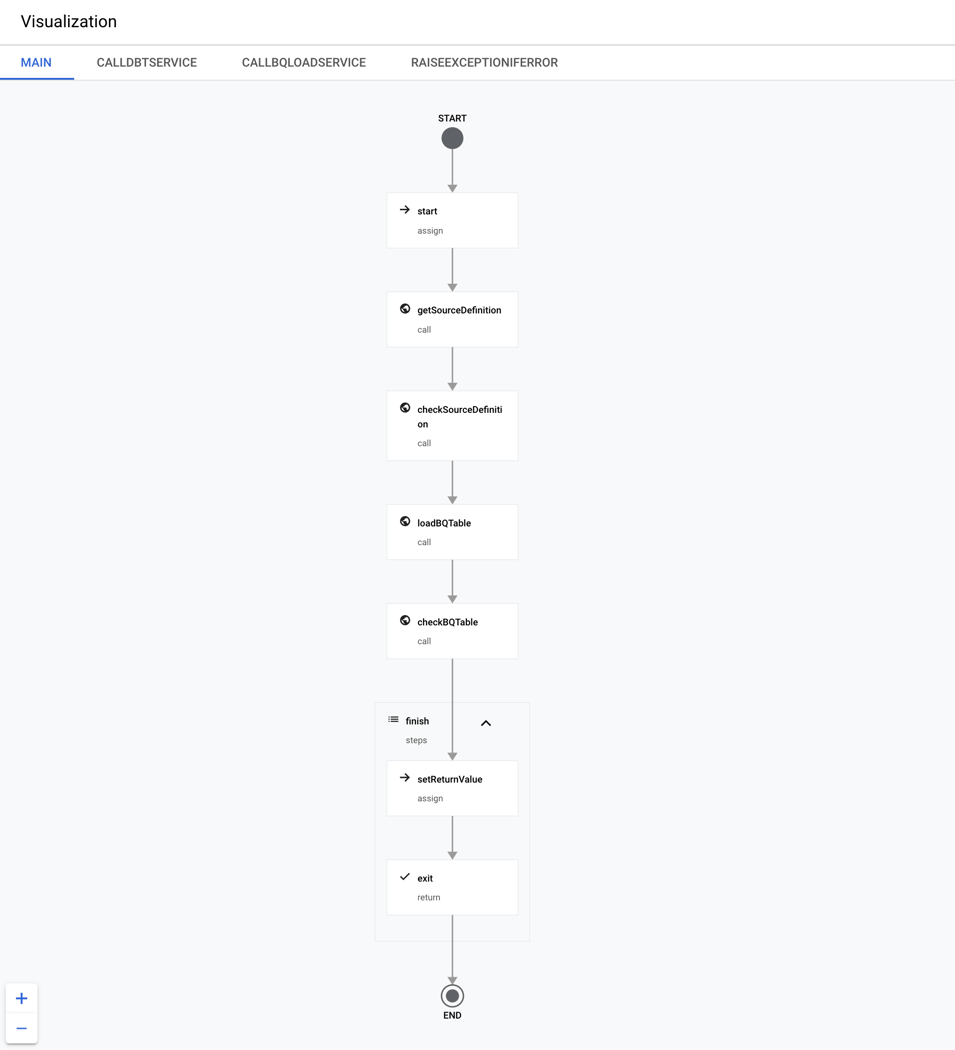
bq-dbt-load-landing
The workflow simply calls the bq-dbt-load-landing-table workflow for each of the four tables to load. Note that the calls are made in parallel to improve performance. Furthermore, the parameters for loading the tables such as project, dataset and table are defined as variables at the top. The code below shows the definition for the bq-dbt-load-landing workflow:
# bq-dbt-load-landing.yml
main:
steps:
- start:
assign:
- dbtSchemaFile: "models/staging/usda/src_usda.yml"
- dbtSourceName: "usda"
- bqProjectId: "bigquery-sandbox"
- bqDatasetId: "bq_demo_ldg"
- tableFileMapping:
stdRefFdGroup:
tableName: "stdref_fd_group"
sourceFileUri: "gs://gcs-ingestion/SR-Leg_ASC/FD_GROUP.txt"
stdRefFdDesc:
tableName: "stdref_fd_desc"
sourceFileUri: "gs://gcs-ingestion/SR-Leg_ASC/FOOD_DES.txt"
stdRefNutData:
tableName: "stdref_nut_data"
sourceFileUri: "gs://gcs-ingestion/SR-Leg_ASC/NUT_DATA.txt"
stdRefNutrDef:
tableName: "stdref_nutr_def"
sourceFileUri: "gs://gcs-ingestion/SR-Leg_ASC/NUTR_DEF.txt"
- parallelExecution:
call: experimental.executions.map
args:
workflow_id: bq-dbt-load-landing-table
arguments:
- dbtSchemaFile: ${dbtSchemaFile}
dbtSourceName: ${dbtSourceName}
dbtTableName: ${tableFileMapping.stdRefFdGroup.tableName}
bqProjectId: ${bqProjectId}
bqDatasetId: ${bqDatasetId}
sourceFileUri: ${tableFileMapping.stdRefFdGroup.sourceFileUri}
- dbtSchemaFile: ${dbtSchemaFile}
dbtSourceName: ${dbtSourceName}
dbtTableName: ${tableFileMapping.stdRefFdDesc.tableName}
bqProjectId: ${bqProjectId}
bqDatasetId: ${bqDatasetId}
sourceFileUri: ${tableFileMapping.stdRefFdDesc.sourceFileUri}
- dbtSchemaFile: ${dbtSchemaFile}
dbtSourceName: ${dbtSourceName}
dbtTableName: ${tableFileMapping.stdRefNutData.tableName}
bqProjectId: ${bqProjectId}
bqDatasetId: ${bqDatasetId}
sourceFileUri: ${tableFileMapping.stdRefNutData.sourceFileUri}
- dbtSchemaFile: ${dbtSchemaFile}
dbtSourceName: ${dbtSourceName}
dbtTableName: ${tableFileMapping.stdRefNutrDef.tableName}
bqProjectId: ${bqProjectId}
bqDatasetId: ${bqDatasetId}
sourceFileUri: ${tableFileMapping.stdRefNutrDef.sourceFileUri}
result: result
- returnResult:
return: ${result}
bq-dbt-load-dwh
The workflow orchestrates the preparation/validation of raw data and the loading of the bq_demo_dwh dataset. It consists of a main workflow and two subworkflows. The main workflow prepares the raw data, runs tests and finally loads the data warehouse if all tests pass. The subworkflows call bq-dbt-svc and handle errors. It’s a simple workflow, but it demonstrates how to run specific dbt models/commands and handle validation errors. For instance, the runStaging step executes the dbt run command only for the staging models by specifying the –models=models/staging/usda/* flag. Any available dbt CLI command or flag can be specified in the command argument, giving full access to its functionality. After each “run” step there’s a “check” step that verifies the response from bq-dbt-svc. Therefore, the “check” steps can halt execution if required.
The runStaging step deploys the staging models (materialized as views) to the bq_demo_stg dataset. These models perform type casting, clean values and identify duplicates on the raw data in the bq_demo_ldg dataset. Please check my previous post if you’d like to know more about how the staging models work.
After deploying the staging models, the runStagingTests step executes tests on them to make sure the data is valid. In this solution, the tests include verification of null values and duplicates for some columns, but there are many other options. If any of the tests fail, the checkStagingTests step halts the workflow execution, effectively stopping invalid data from getting into the data warehouse. The code below shows the definition of the bq-dbt-load-dwh workflow:
# bq-dbt-load-dwh.yml
main:
steps:
- start:
assign:
- dbtServiceUrl: "https://bq-dbt-svc-b7rdt3fiza-uc.a.run.app/dbt"
- runStaging:
call: callDbtService
args:
step: "runStaging"
url: ${dbtServiceUrl}
command: "run --target=prod --models=models/staging/usda/*"
result: dbtServiceResponse
- checkStaging:
call: raiseExceptionIfError
args:
step: "checkStaging"
errorMessage: "Error found while running staging models."
response: ${dbtServiceResponse}
- runStagingTests:
call: callDbtService
args:
step: "runStagingTests"
url: ${dbtServiceUrl}
command: "test --target=prod --models=models/staging/usda/*"
result: dbtServiceResponse
- checkStagingTests:
call: raiseExceptionIfError
args:
step: "checkStagingTests"
errorMessage: "Some staging tests failed."
response: ${dbtServiceResponse}
- runDataWarehouse:
call: callDbtService
args:
step: "runDataWarehouse"
url: ${dbtServiceUrl}
command: "run --target=prod --models=models/dwh/*"
result: dbtServiceResponse
- checkDataWarehouse:
call: raiseExceptionIfError
args:
step: "checkDataWarehouse"
errorMessage: "Error found while running data warehouse models."
response: ${dbtServiceResponse}
- finish:
steps:
- setReturnValue:
assign:
- returnValue: {}
- returnValue.status: "ok"
- returnValue.message: "Execution completed successfully."
- exit:
return: ${returnValue}
callDbtService:
params: [step, url, command]
steps:
- logRequest:
call: sys.log
args:
text: ${"[" + step + "] Sending request to " + url + " -> " + command}
- sendRequest:
call: http.post
args:
url: ${url}
auth:
type: OIDC
body:
params:
cli: ${command}
result: response
- logCommandStatus:
call: sys.log
args:
text: ${"[" + step + "] dbt status:" + " " + response.body.result.status}
- logCommandOutput:
call: sys.log
args:
text: ${"[" + step + "] dbt output:" + " " + response.body.result.command_output}
- returnResponse:
return: ${response}
raiseExceptionIfError:
params: [step, errorMessage, response]
steps:
- verifyResponse:
switch:
- condition: ${response.body.result.status != "ok"}
steps:
- exit:
raise:
status: ${response.body.result.status}
step: ${step}
output: ${response.body.result.command_output}
message: ${errorMessage}
Deployment to GCP
Deploying the workflows to GCP can be done easily with Cloud Build. You just need to specify the service account to use and the location of the workflow definition file. The code below shows the Cloud Build config for the bq-dbt-load-dwh workflow:
# cb-bq-dbt-load-dwh.yml
steps:
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args: ['workflows', 'deploy', 'bq-dbt-load-dwh',
'--location', 'us-central1',
'--service-account', 'bq-dbt-sa@bigquery-sandbox.iam.gserviceaccount.com',
'--source', 'bq-dbt-load-dwh.yml']
The command below starts the deployment by submitting the build config to Cloud Build:
gcloud builds submit ./cloud-workflows \ --config=./cloud-build/workflows/cb-bq-dbt-load-dwh.yml \ --project bigquery-sandbox
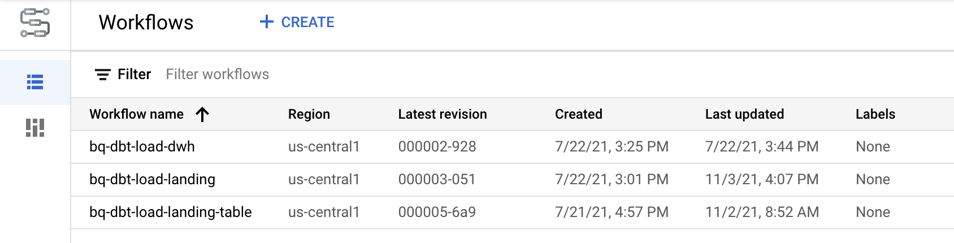
Here’s a screenshot of the workflows after being deployed to GCP:
Executing the workflows
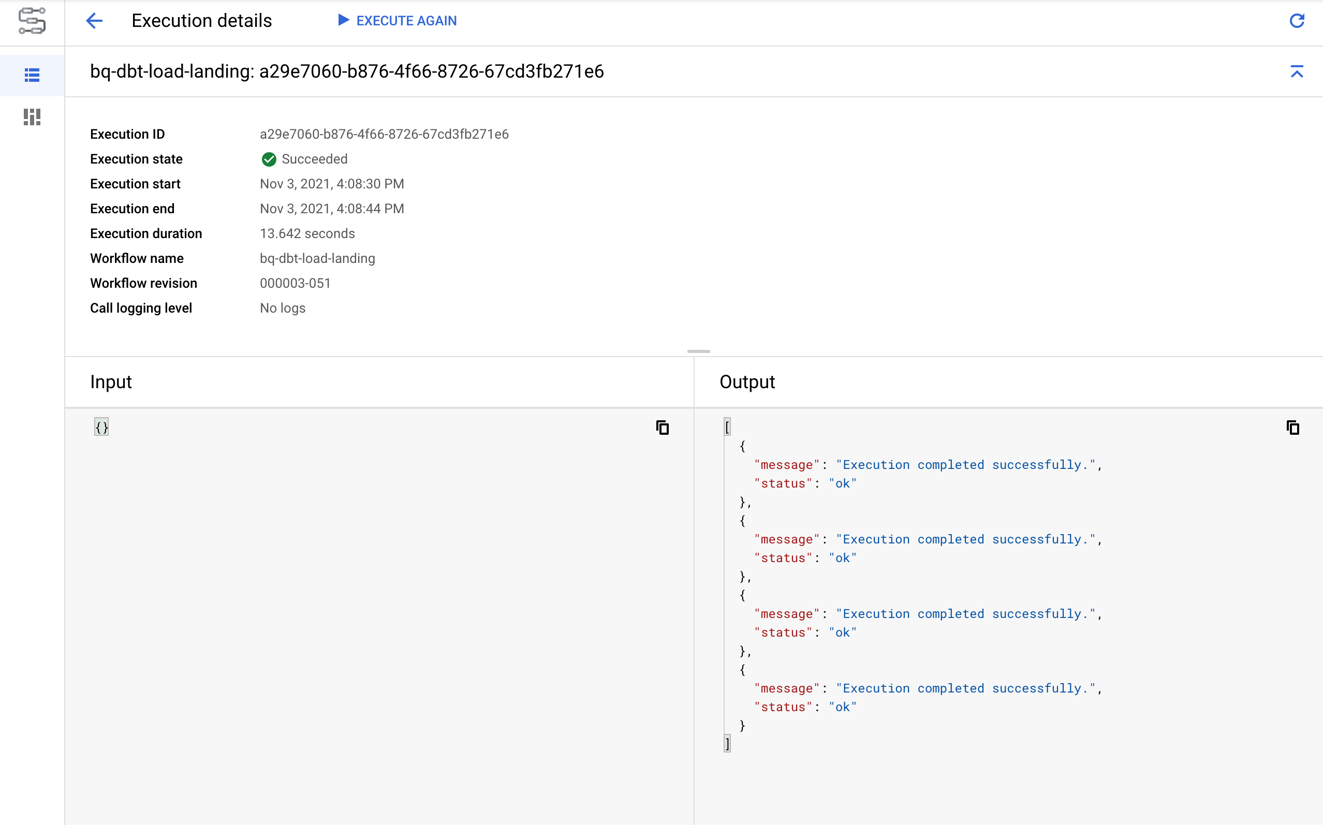
There are many options for executing a workflow: client libraries, the GCP console, the gcloud command or the REST API. We’ll use the GCP console for simplicity; we just need to click on the desired workflow and click on the “Execute” button. Let’s start by executing the bq-dbt-load-landing workflow to load the tables in the bq_demo_ldg dataset. The screenshot below shows the result of the execution:
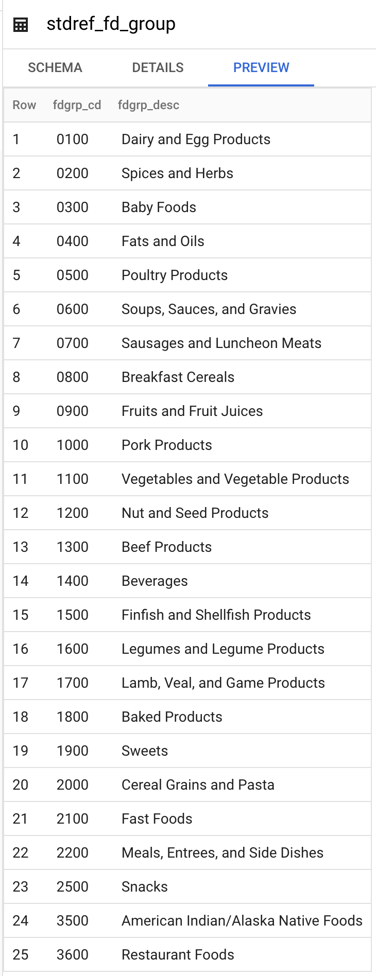
At this point, the four tables in the bq_demo_ldg dataset have been created and loaded from the files in GCS. For example, the screenshot below shows the contents of the stdref_fd_group table:
A test was configured in dbt on the fdgrp_cd column to make sure there are no duplicate codes. Therefore, before executing the bq-dbt-load-dwh workflow let’s create a fake duplicate in the table. As a result, we’ll see how the workflow stops when a test fails. The code below creates a duplicate code in the stdref_fd_group table:
# Create a fake duplicate by changing the code of a food group code update `bigquery-sandbox.bq_demo_ldg.stdref_fd_group` set fdgrp_cd = '0700' where fdgrp_desc = 'Poultry Products'; # Verify that there are duplicates now select * from `bigquery-sandbox.bq_demo_ldg.stdref_fd_group` where fdgrp_cd = '0700'; fdgrp_cd fdgrp_desc -------- ---------- 0700 Sausages and Luncheon Meats 0700 Poultry Products
As expected, the bq-dbt-load-dwh workflow stops when the test fails. The screenshot below shows the result of the execution:
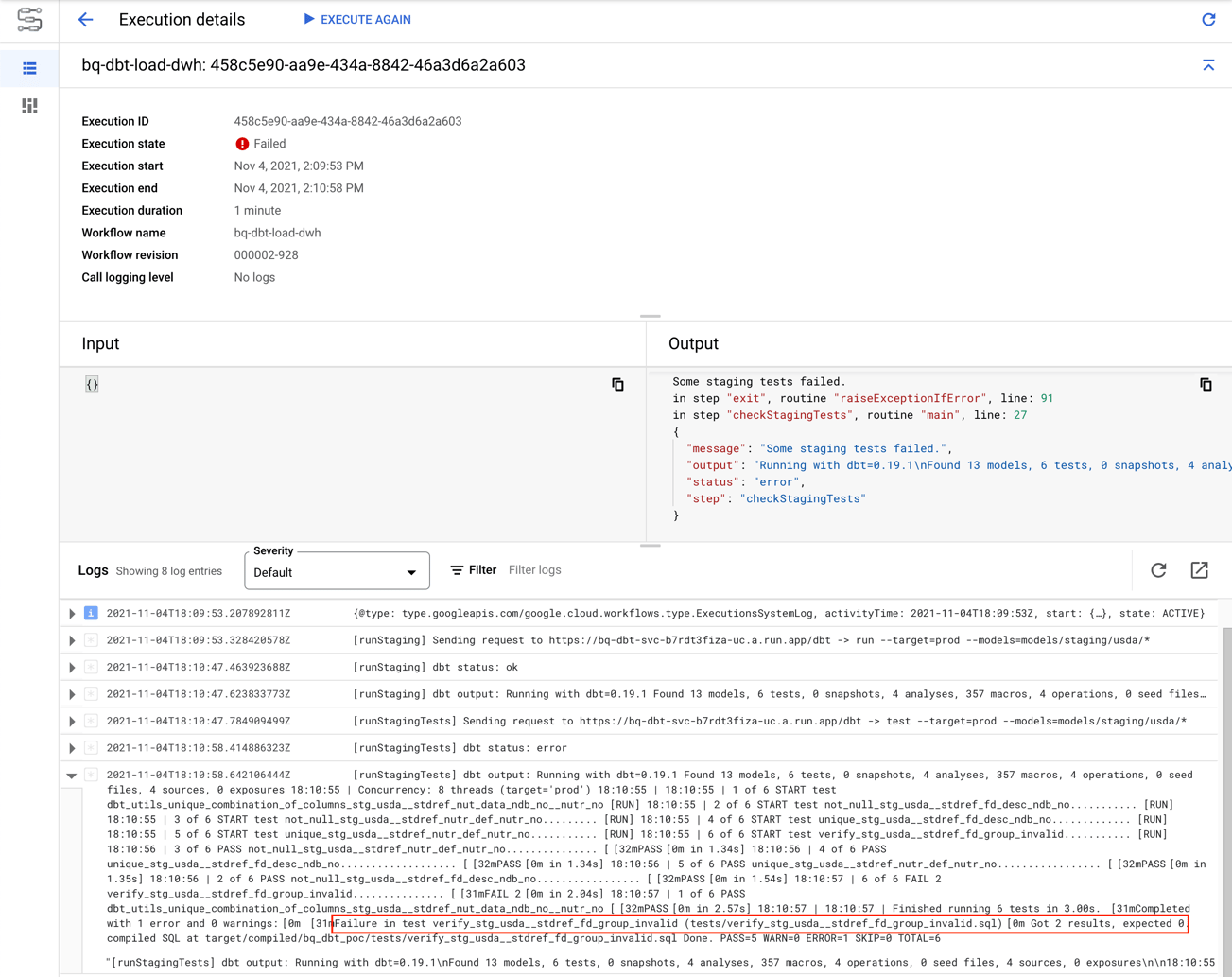
Now, let’s revert the change to create the fake duplicate so that we can execute the full bq-dbt-load-dwh workflow. The code below reverts the change to create a duplicate code in the stdref_fd_group table:
# Revert the change to make a fake duplicate update `bigquery-sandbox.bq_demo_ldg.stdref_fd_group` set fdgrp_cd = '0500' where fdgrp_desc = 'Poultry Products'; # Verify that there are no duplicates now select * from `bigquery-sandbox.bq_demo_ldg.stdref_fd_group` where fdgrp_cd = '0700'; fdgrp_cd fdgrp_desc -------- ---------- 0700 Sausages and Luncheon Meats
This time, the bq-dbt-load-dwh workflow completes successfully. As a result, the data warehouse models (materialized as tables) get deployed to the bq_demo_dwh dataset. Moreover, we can be confident that our assumptions about the data are correct since all our tests pass. The screenshot below shows the result of the execution:
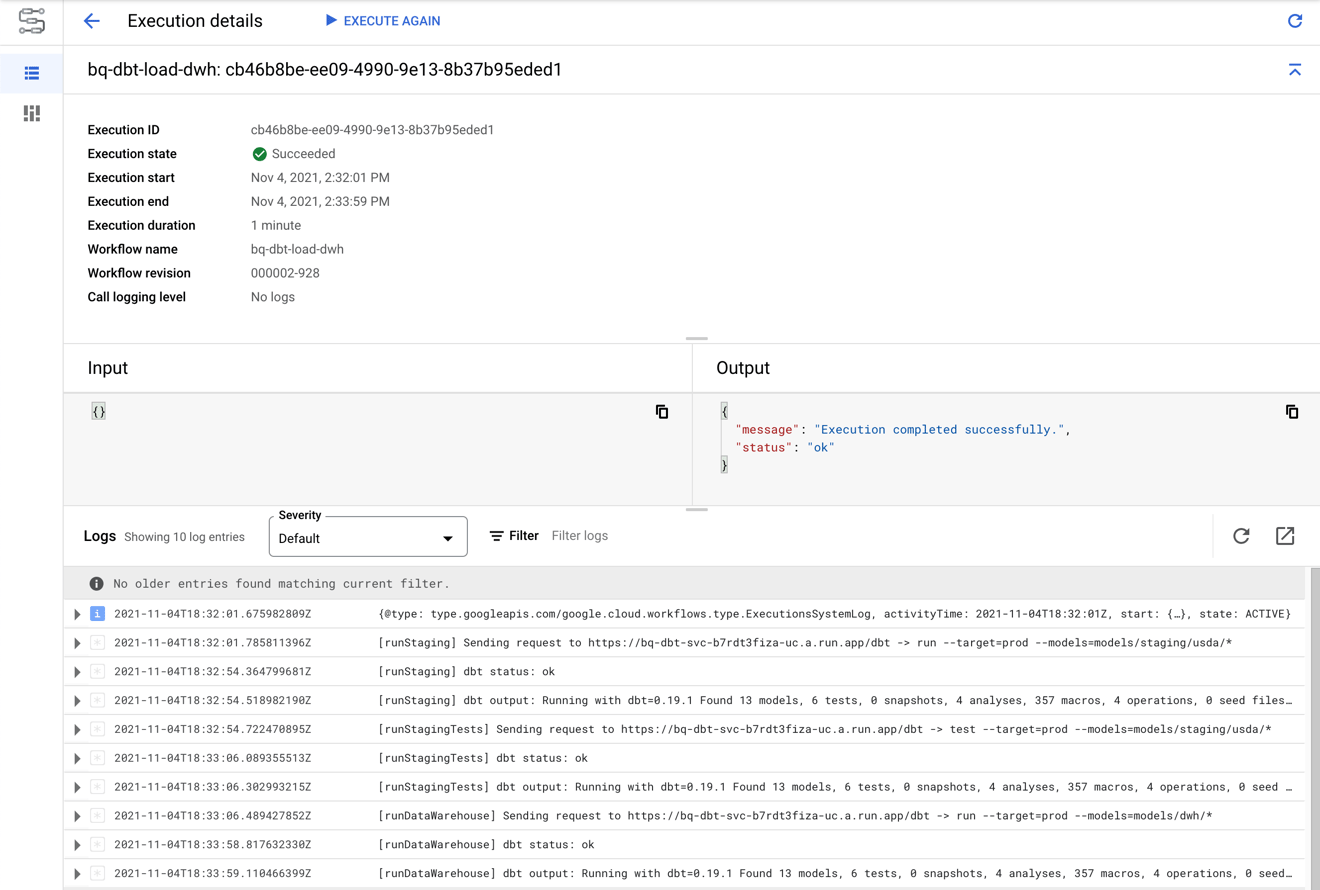
Conclusion
We have seen before how dbt can help us easily define transformations and tests in our data pipelines. In this post, we saw how Google Workflows and Cloud Run can be used to effectively orchestrate those dbt pipelines. The result is a fully serverless and pay-per-use solution that can automatically scale up to handle heavier workloads.
Google Workflows provides a set of features to build robust enterprise workflows, however it might not be the right orchestrator for you. Very complex workflows or workflows that are date- sensitive (need to catch up missed executions) are better suited for Cloud Composer. It’s not a serverless, pay-per-use product, but it can orchestrate Cloud Run services or execute custom Python code.
Thanks for reading. Feel free to drop any questions or share your thoughts in the comments.
Don’t forget to sign up for more updates here.

