
When it comes to data warehouse modernization, we’re big fans of moving to the cloud. The cloud brings unprecedented flexibility that allows you to easily accommodate the growing velocity, variety, volume, veracity and value of today’s data. It also allows you to take advantage of cost elasticity; meaning you only pay for what you use.
Initially, decision-makers don't always put cloud costs high on their priority lists. Instead, the decision to move data warehouses to the cloud is primarily driven by a) the obvious cost savings over an on-premises solution, and b) the benefits of agility.
That said, we’re predicting that once you’ve modernized and you’re in the cloud, corporate eyes will turn to an examination of cloud costs with a view to cost optimization. IT managers will need to be ready and be able to demonstrate that their platforms have been designed to optimize cloud costs which are driven by a number of factors; mostly storage and data processing.
When we design solutions for data warehouse modernization in the cloud, we spend a lot of time thinking about how to optimize costs (see this
blog pos
t for a higher-level discussion of building cost considerations into data platform architectures). It takes time but it pays off in the long run. While there are many ways to incorporate cost considerations into a design, one way is to use a data lake with your data warehouse (it also has many other benefits, but let’s stick with cost optimization for purposes of this blog post).
What follows is a simple analysis we did for one of our projects that demonstrates how adding a cloud data lake to your cloud data warehouse can keep your costs lower than a data warehouse alone, even as it brings other benefits.
Our simple data platform example looked like this:
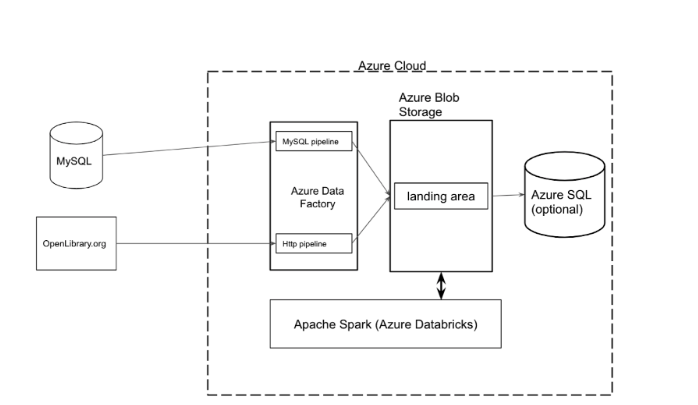 The components contributing to the overall cost of this simple, but quite typical, data platform solution running in Azure are the following:
The components contributing to the overall cost of this simple, but quite typical, data platform solution running in Azure are the following:
The components contributing to the overall cost of this simple, but quite typical, data platform solution running in Azure are the following:
- Storing data on Azure Blob Storage
- Executing pipelines with Data Factory
- Running multiple Databricks Spark cluster nodes
- Running an Azure SQL instance


