One of the many things to love about Cassandra is how operationally simple it is to add, remove or even replace nodes in a cluster.
Replacing a node in Cassandra is as easy as setting your configuration files to match the old node (except server-specific settings like listen_address and rpc_address) and adding the following line to cassandra-env.sh:
JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address=<address_of_replaced_node>"
Once you start Cassandra on the new node, it goes through a few steps before starting the replacement, at which point it inherits the token ranges owned by the replaced node and streams data from existing replicas for each of those token ranges.
When the bootstrap process finishes, you must remove the replace line that we appended to the cassandra-env.sh file and that’s it–node replaced.
While both adding (using auto_bootstrap) and removing nodes come at no cost to data consistency, replacing a node introduces a few variables, making it slightly more nuanced behind the scenes in regards to consistency impact.
Common Gotchas
Before moving on to the consistency bit, I’ll address a few things to bear in mind when performing a node replacement and how to address common roadblocks. First, there are two conditions to be verified in the cassandra.yaml file for the replacing node:
- The new node isn’t a seed.
- You’ve set
auto_bootstrap: true– this is the default value.
When you’re not satisfying both, you’ll bump into this error in the system.log during bootstrap:
Replacing a node without bootstrapping risks invalidating consistency guarantees as the expected data may not be present until repair is run.
Replacing seed nodes
Replacing a seed node? No problem. In this situation you should promote another node in the same datacenter to seed on all nodes’ cassandra.yaml, but don’t restart the nodes in the cluster until the replacement is completed–this will render the replacement impossible by causing gossip information on the downed node to be lost. This happens because gossip information cannot survive full restarts.
Node info not in gossip
If you ever run into a situation where a replacement is failing and you’re seeing the following error in the replacement node system.log:
Cannot replace_address /127.0.0.1 because it doesn't exist in gossip
it’s likely that the nodes have already restarted and lost the gossip information on the node to be replaced. The best procedure in this case is to remove the downed node from the cluster by running on any live node:
nodetool removenode <old_node_ID>
Then, bootstrap the replacement node as you would do to expand a cluster–without a replacement flag. Before you start adding a node, make sure that the old node has been removed from gossip on the cluster. You can check it by running on every live node:
nodetool status | grep <old_node_ID>
With this check, we either want to get no results or see the node with status “down and leaving” (DL). It isn’t entirely uncommon to see inconsistent gossip information across all nodes in the cluster–a consequence of the decentralized nature of the gossip protocol. If there’s no consensus after around (two minutes x number_of_nodes), you can restart Cassandra on the nodes that didn’t yet recognize the old node as decommissioned or DL. In some situations, this might not be enough to remove the node from the ring. When that happens, we can resource to the last and least graceful nodetool option to remove a node from the cluster:
nodetool assassinate <old_node_IP_address>
However, this option isn’t one I can recommend lightly. It’s advisable to let gossip allow for a cluster consensus on node removal over the course of 72 hours after running nodetool removenode before considering nodetool assassinate. If you do need to run assassinate, follow it with a repair to allow data to be streamed to new replicas.
Node still recognized as bootstrapped
Another common error in system.log you might bump into when attempting to replace a node is:
Cannot replace address with a node that is already bootstrapped
If you see this, here are the main suspects blocking the replacement:
- A node with the replacement address is up and running in the cluster.
- The replacement node has data in its data directory and/or commit log directory.
- The replacement node is running a different Cassandra version.
Data Consistency on Cluster Scaling
When you’re adding a node to an existing cluster, the token distribution will inevitably be rearranged among the nodes. More precisely, this means that all the data that the new node will be responsible for will be passed on from other existing replicas in the cluster. Once the new node finishes bootstrapping, the older replicas will still have the data, but will no longer serve read requests for that data. Removing this data from storage is the reason we run a cleanup on clusters after expanding. To ensure consistency, the new node on bootstrap will stream the data from the exact replicas that are going to lose their ownership.
The same principle is applied when decommissioning nodes. When you decommission a node, it will stream all the data that it owns to future replicas. When the node finishes decommissioning, new replicas not only take over the node’s token ranges but also its data, meaning that no data is lost as a result of the process.
What’s the consistency cost of a node replacement?
Unlike adding and removing nodes, replacing can’t ensure that data is streamed from the node we’re replacing. Unless we can somehow restore sstables from the downed node, there’s no way to directly inherit data since the node we’re replacing must be down before it’s replaced.
During a node replacement Cassandra picks a single replica for each of the token ranges being inherited to stream the data to the replacement node.
This system introduces two drawbacks in regards to consistency:
- The data isn’t streamed from the node that lost its ownership. This means there’s a chance of data loss. This would happen in any scenario where the replaced replica was the only replica with updated values for any given row or column.
- The streaming is done from a single replica for each partition. This isn’t ideal because there’s no guarantee that the replica streaming the data will have the latest values. In order to maximize consistency, it would make sense to either stream each partition from all (replication factor -1) existing replicas or perform a consistency check for data in inherited token ranges.
The most practical way to mitigate these drawbacks is by leveraging anti-entropy repairs:
- Run anti-entropy repairs often enough to avoid data loss when a node needs to be replaced.
- Perform an anti-entropy repair as soon as the replacement node finishes bootstrapping, as a means to get all replicas owning updated data on the replaced token ranges.
Even if we follow these two guidelines, there’s a period where the replacement node is serving requests with potentially inconsistent data:
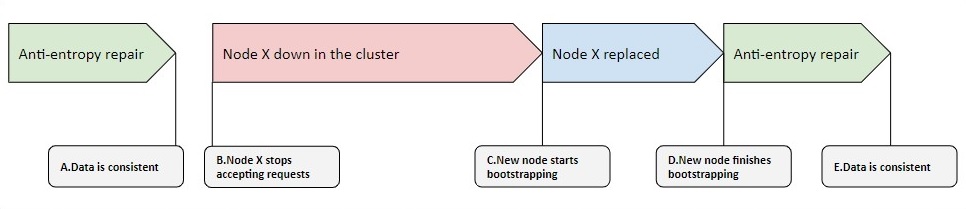
Between the replacement completion at D and the end of repair at E, there’s a period where there’s an increased risk of having quorum replies with inconsistent data. The risk of running into these requests scales with the length of the period between A and B.
As previously mentioned, you can’t replace a node without auto_bootstrap: true :this flag defines whether or not streaming takes part during bootstrapping.
But there’s a workaround by adding this flag to the file cassandra-env.sh:JVM_OPTS="$JVM_OPTS -Dcassandra.allow_unsafe_replace=true”
This isn’t something we usually recommend, as it can expose users to unnecessary risks during node replacements, namely: bootstrapping serviceable nodes to the ring with no data, or worse–replacing nodes as seeds, which will cause tokens to be reshuffled in the ring without syncing the data first (not even a repair can save us here).
Introducing unsafe replacement
The following matrix explains the interactions between replacing the nodes with the flags allow_unsafe_replace, auto_bootstrap and being a seed:
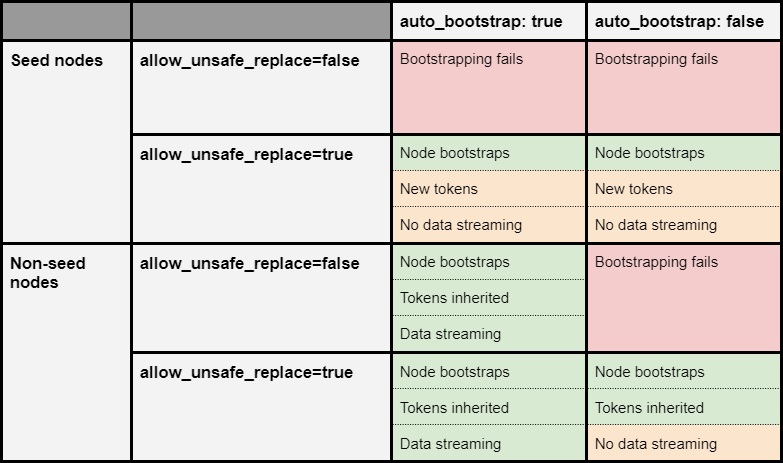
As you can see, the flag allow_unsafe_replace does exactly what we’d expect from its name. It allows you to replace nodes under circumstances where you normally wouldn’t be able to due to failed safety checks in Cassandra.
There is, however, another scenario where you can use this flag to our advantage: when the replacement node has some, or all the data from the replacement node. This is common when you’re spanning data across multiple disks per host and run into a disk failure.
In this situation, you can replace the node and skip the auto bootstrap process. Nonetheless, you must follow this replacement with a repair to recover any lost data and the process must fulfill three conditions:
- The node must not be a seed node on its own list.
- Clear the system keyspace directories on the replacement host.
- The time since the replaced node has been down must be less than the smallest value of
gc_grace_secondsin any of the tables. By default this is 10 days.
You don’t want the node to be a seed because on bootstrap the node would re-generate token ranges, effectively losing ownership of the data you’re trying to recover, while also not streaming data for the tokens it’s taking over.
Clearing the system keyspace in this situation is harmless, as the node will populate it once again during replacement.
Finally, in Cassandra you never want to bring back data after gc_grace_seconds have passed, at the risk of resurrecting deleted data. This process is commonly known as zombie data–here’s a post that better explains the whole deal.
TLDR
- Node replacements don’t ensure consistency the same way that commissioning or decommissioning nodes in a cluster do.
- Running frequent repairs mitigates consistency costs.
- There are a few workarounds that can guarantee strong consistency, but ultimately you can always lose data on a node replacement unless you can physically retrieve it from the replaced host–either via restore or persisting the data while using
allow_unsafe_replaceto your advantage.
I hope you find this post helpful. Feel free to drop any questions in the comments and don’t forget to sign up for the next post.

