
After eight years in business, Snowflake filed its prospectus with the USA's Securities and Exchange Commission to become a publicly traded company this week (August 24, 2020). Details are
here. This is the next step in the history of the Data Platform as a Service (dPaaS) company, which has crafted itself a valuable and rising position in the battle of cloud data platforms. With Snowflake's increased popularity, we have seen a corresponding increase in interest and adoption. I have no doubt the IPO, and influx of capital and coverage by the business news media will only accelerate the momentum. At Pythian, we have started to spot patterns and best practices, and begun to accumulate lessons learned to apply to our Snowflake engagements going forward. As usual, we want to help clients start off on the right track. It's best to avoid having to backtrack or worse, start accumulating technical debt from the very beginning! With this in mind, I decided to flesh out the top five recommendations for accelerating your Snowflake adoption.

1. Find the right balance of virtual warehouses
Snowflake's ability to spin up separate compute clusters that can use the same data is one of its most attractive features. Not only does it allow for resource isolation, but it's also a beautifully simple resource management and billing model. Some people believe that since a virtual warehouse has no cost unless it's actively querying, it makes a lot of sense to simply create a large amount of one- or two-node virtual warehouses and practically assign one for each user. This approach wastes a lot of credits spinning up warehouses all day and ends up being a manageability nightmare. The best approach is to bucket your users based on their query workload patterns. If you're planning to chargeback the warehouse cost, you can also organize it by paying the business unit. This way you will likely end up with 10 or fewer warehouses in most cases. Below you can see a minimum setup of a virtual warehouse for computing queries and a virtual warehouse for loading data. This is the bare minimum to at least avoid contention between loading and reading. Also, the loading virtual warehouse usually operates under a fixed reduced schedule.
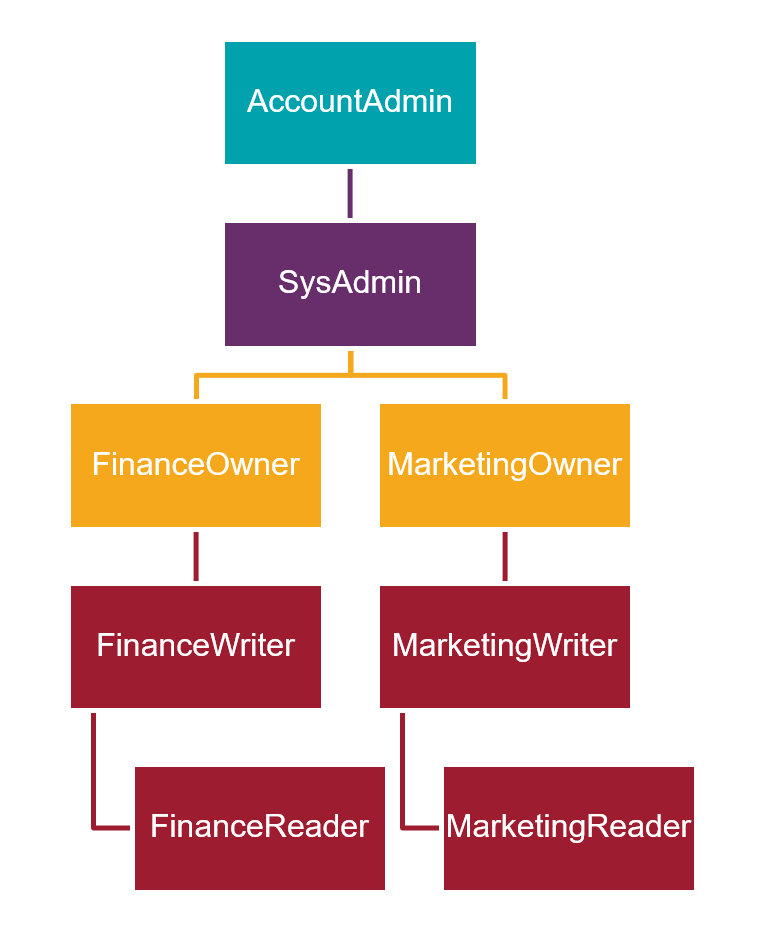
2. Design your role hierarchy and initial assignments before going live
Snowflake supports role-based authorization similar to many other database systems. However, by default it only comes pre-populated with a few account level roles (account admin, sysadmin, security admin, etc.), leaving it up to you to create the right role hierarchy for your organization's requirements. There are two interesting things about role implementation: one is that roles own the objects and second, roles can be nested with other roles. This means you can take a top-down approach to go from ownership, to assigned read / write privileges, to read-only privileges, as a starting point for a given database. Then you assign the roles bottom-up: reader assigned, to read / writer assigned, to owner, and finally all created roles assigned to your sysadmin. This will save you time down the line since the security hierarchy will be easy to manage while at the same time preserving the principle of least privilege. Here's an example of what I mean:
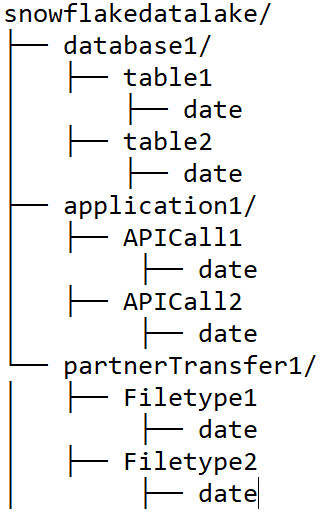
3. Prep and secure your cloud storage that will be integrated with your account
Being a multi-cloud product, Snowflake supports AWS S3, Google Cloud Storage, Azure Blob Storage, or Azure Data Lake. While not 100 percent necessary, odds are very high that you will end up using cloud storage as a landing pad for data, long term archive, or raw data lake as well. Meaning, your Snowflake account will be interacting regularly with your cloud storage through a feature Snowflake calls an "external stage." The actual implementation is very neat, and once it's configured, it's transparent to use the cloud storage, and not too hard to swap one cloud storage for another (in the event you want to migrate to a different cloud or for DR). This means that once again, it's better to get this properly setup and configured before you go live with your data platform. Below is a common folder structure we recommend for clients. At a minimum, we recommend this breakdown to the date level. Depending on requirements there could be more levels down such as "pending" or "processed" folders or more. Using the cloud provider's own security model you can protect the top-level folders (e.g. for a specific app or ETL tool) and the subfolders (e.g. read-only access to the "processed" folder). Here's an example:
4. Due diligence and selection of external services
While Snowflake provides data loading and visualization capabilities, they might not meet all your requirements depending on the complexity of what you need to orchestrate, or the visualization, analysis, and collaboration capabilities you're looking for. Most enterprise clients will end up using services like AWS Glue, Google Cloud Dataflow, or Azure Data Factory. Similarly, clients might use their Snowflake data with downstream tools like Alteryx, Tableau, or Power BI. Deciding whether you need any of these services, and if so which one(s), is a decision that must be tailored to the client, their requirements and their budget.5. Decide which (if any) encryption features you need
Snowflake supports the following encryption features:- Encryption at rest with Snowflake keys
- Encryption at rest with customer keys
- End-to-end file encryption for loading data
- Column encryption managed by code
- External tokenization of sensitive values


