Transfer learning is an approach where the model pre-trained for one task is used as a starting point for another task. It’s extremely useful in scenarios where there are limited data available for model training, or when training a large amount of data could potentially take a lot of time. This post illustrates the Transfer Learning technique with a hands-on code walk-through on the pre-trained convnet image classification model.
Why Transfer Learning?
- Less training data: Having lots of training data is not always practical. You might not have all the data or time required for training large datasets. This might turn out to be both cost and time prohibitive. In the case of CNN models for image recognition, initial outer layers of the deep learning model focus more on the higher-level abstract features, while top layers focus more on the details of the image. In this case, it makes sense to reuse the outer layers trained on the abstract features.
- Better generalization and therefore better results: Pre-trained models used for transfer learning are usually trained on a large amount of the data. Models trained on the pre-trained models as a base tend to generalize better on the unseen data, as they have been trained to identify more generic features.
- Better accessibility for DL: Many DL models are now readily available online. This can speed up training and boost the performance for various DL use cases.
Problem Statement
Let’s look at the concrete use case of identifying cats versus dogs from a picture. Even though its a fairly straightforward image classification problem, let’s look at how transfer learning might help us boost the model performance while working with a small dataset. In this case, we’ll focus on large convnet trained on the ImageNet dataset with 1.4 million labelled images and 1000 different classes. We’ll use the simple and widely used VGG16 convnet architecture.
There are two ways to leverage a pre-trained network: Feature extraction and fine-tuning.
Feature Extraction
We can use representations learnt by a higher-level network to extract relevant features from it. You can then run these features with a new classifier and trained from scratch. Convnets consist of two parts pooling a convolution layer with a densely connected classifier on top. The first part is referred to as the convolution base of the model. So in this case, feature extraction consists of re-using the convolution base layer from ImageNet and training it with a new classifier on the top.
You might ask: “So why not use the densely connected layer from ImageNet?” The representations learnt by the convolution base tend to be more generic and therefore reusable. Whereas representations learnt by dense classifiers are more specific to the use case and the data it’s trained on. This is the reason why only the convolution base is recommended to be reused, as it’ll have more general information more likely to be applicable for a variety of image classification problems.
The level of generality of the representations captured, therefore, depends on the depth of the layer. The higher up the layer the more “general” it is. In this case, we’re using the entire convolution base as the base of the new model since it has already been trained on the cat and dog datasets. But in cases where your target dataset greatly differs from the source pre-trained model, it’s recommended to only use selected layers from the convolution base than the entire one.
Let’s see this in action.
Instantiate the VGG16 model:
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
Print the model summary:
conv_base.summary()
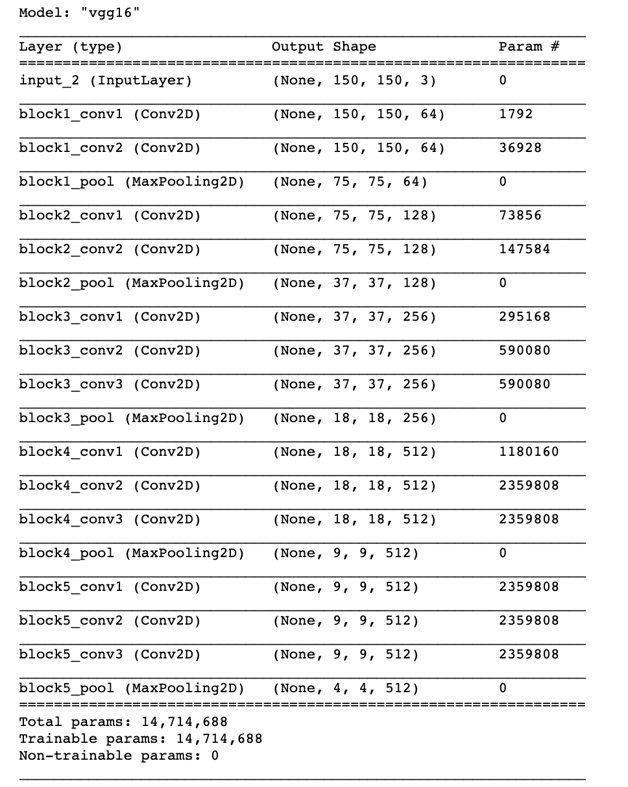
The final feature map has shape (4,4,512). That’s the feature on top of which we’ll stick a densely-connected classifier.
Let’s define our new model and add convo_base as a layer:
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Let’s see the model summary:
model.summary()

Before we can compile and train our model, we need to “freeze” our conv_base to prevent base layer weights from getting updated during training. This is a critical step; If we don’t do this then it will effectively destroy the previously learnt representations and would defeat the purpose of using a pre-trained model base.
We can “freeze” the convo_base” layer by setting its trainable attribute to “False,” as shown below. But first, let’s verify the number of trainable attributes before setting the flag:
print('Trainable weights '
'before freezing the conv base:', len(model.trainable_weights))
conv_base.trainable = False
Now, let’s start training our model:
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
Save the model:
model.save('transfer_learning_model.h5')
Lets plot the results:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend()plt.show()
And here are the plots:
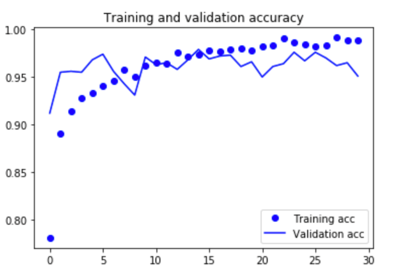
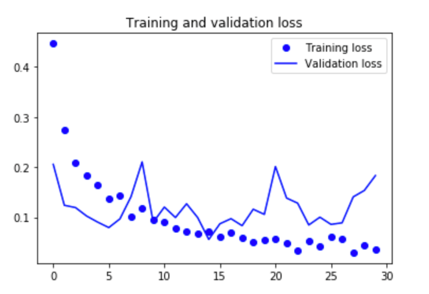
The validation accuracy is almost 95%.
Fine Tuning
We can take the above approach bit further. We can unfreeze a few of the top layers as part of the feature extraction process and train them together with our original dense classifier. This technique is called “fine-tuning,” as it uses more representations from the model to make them more relevant to the current use case. Fine-tuning is only possible when top layers of the convo base layers have already been trained. If not, then the error propagates through the network would be amplified to be useful.
Here are the high-level steps for fine-tuning:
- Add a custom layer on top of the pre-trained base layer (in this case, dense classifier).
- Freeze the base.
- Train the network (base + classifier).
- Unfreeze a few layers in the base.
- Train again.
We’ve already seen the first three steps, so lets start from step four.
For a quick refresher, here’s the model summary again:
conv_base.summary()
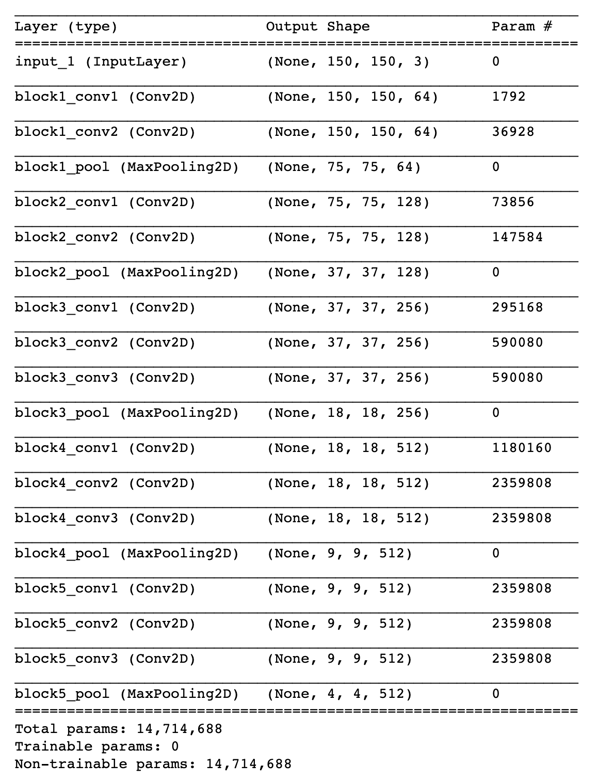
Let’s fine-tune the last three convo layers:
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
Let’s fine-tune our network:
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Save the model:
model.save('transfer_learning_model2.h5')
Plot the results:
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
Here are the plots:
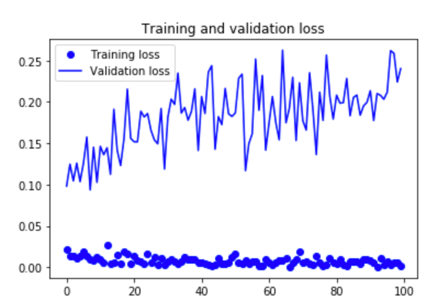
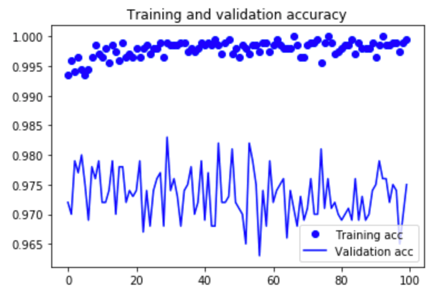
Lets evaluate this model on the test data:
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)

The accuracy has improved from 95 % to almost 97% with the use of fine-tuning. That’s not bad at all.
Summary
As you can see, we’ve taken the pre-trained model for image classification and reused its base to “extract features” relevant to solving a “dogs versus cats” classification problem. We’ve added a classifier on top of our pre-trained model and used very little generated data to train our final model (and gained impressive model prediction accuracy). You can use fine-tuning as a complementary approach to feature extraction to squeeze out more performance from the model.

