Data warehouse or data lake? We break down the pros and cons of each
In the book Designing Cloud Data Platforms, separating storage from compute is a key tenet of a layered cloud data platform design. It brings scalability, cost savings, flexibility and maintainability. But established ways of operating are slow to change — traditional data warehouse architects advocate for processing in the data warehouse while modern cloud platform design dictates that processing should happen outside the data warehouse. Modern cloud analytics data platforms are complex things – in more ways than one. To start, they include many different components and layers all working simultaneously. This includes an extract, transform, load (ETL) layer; an ingestion layer; fast and slow storage; a data warehouse; and a data lake, among other components. That’s a lot of things all working in concert, each playing a critical role in a modern data platform’s scalable storage, performance and ability to work with the latest and most in-demand data types, APIs, and data visualization tools. But processing (integration, deduplication, and transformation of data) is where the real magic happens. It’s where required business logic is applied to data. It’s where vital data validations and data transformations take place. It’s also where organizations really begin seeing the value of their data, in the form of business insights derived from a single, organization-wide version of the truth. This processing layer in a data platform is responsible for reading data from storage, transforming it, and saving it back to storage for further consumption down the road. Transformations can include the implementation of common data cleanup steps – such as ensuring all date fields follow the same format – or the implementation of specific business logic such as joining two datasets to produce the insights needed for a specific report.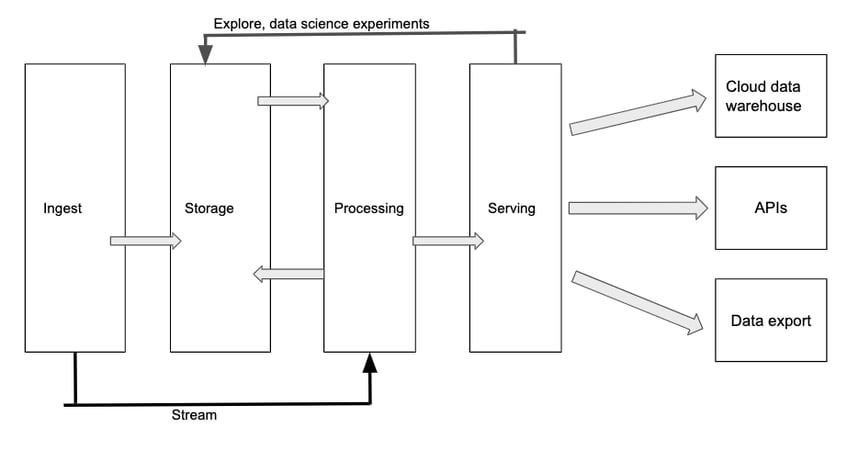
Processing in a modern data platform: The great debate
Where the processing actually happens in a data platform is often hotly debated. Some people maintain the data warehouse is the best neighborhood for data processing. Others swear by the data lake as the most appropriate spot. While separating storage from compute is a key tenet of a layered cloud data platform design, thanks to the benefits of scalability, cost savings, flexibility and maintainability, traditional data warehouse architects will sometimes advocate for processing to happen in the data warehouse. This is despite the dictates of modern cloud platform design that processing should happen outside the data warehouse. Proponents of using SQL to apply business logic in the data warehouse usually readily agree that this violates the principles of a layered design. But they also point to other reasons why they believe it’s the best avenue.The showdown
 We took two data experts and asked one to argue that data should be processed in the data warehouse using SQL, and the other to argue that data should be processed in the data lake using Spark which is available as a managed service from all three of the public cloud vendors:
Azure Databricks, Google Cloud’s
Dataproc and
EMR from AWS. Here’s the summary of the arguments:
We took two data experts and asked one to argue that data should be processed in the data warehouse using SQL, and the other to argue that data should be processed in the data lake using Spark which is available as a managed service from all three of the public cloud vendors:
Azure Databricks, Google Cloud’s
Dataproc and
EMR from AWS. Here’s the summary of the arguments:
| Processing data in the data lake via Spark | Processing data in the data warehouse via SQL | |
| Flexibility | Processing done in the data lake brings additional flexibility; outputs can be used not just for data served in the data warehouse, but also for data that can be delivered to or consumed by other users and / or systems. | Outputs of data processing are typically restricted to use in the data warehouse. |
| Developer Productivity | Once trained, developers typically appreciate the power and flexibility of Spark, with its sophisticated testing frameworks and libraries to help accelerate code delivery. | While not designed as a programming language, SQL’s popularity means that finding people who know it is relatively easy, which can mean a faster time to value. |
| Data Governance | Processing data as close to the source as possible supports more consistent use of transformed data across different sinks, and reduces the risk of multiple people transforming data and defining data differently. | Processing data in the data warehouse can support a data governance program but if processing is also done in the data lake, conflicting data definitions may emerge. |
| Cross- Platform Portability | Spark produces fully portable code independent of the cloud vendor. That means changing from one data warehouse to another is easier; no migration is required, testing is minimal, and transformations don’t need changing. | Transformations done in ANSI-SQL are supported by all the major cloud providers’ data warehouse offerings, and are portable provided that no cloud vendor-specific add-ons have been added. Work, however, will be required to migrate and test code. |
| Performance | No amount of processing will impact data warehouse users when processing is done outside the data warehouse. | Most modern cloud data warehouses provide great out-of-the-box performance, but some may suffer as processing load increases. |
| Speed of Processing | Real-time analytics is always possible. | Real-time analytics is possible in some cloud data warehouses, but involves multiple steps and / or products. |
| Cost | It’s typically less expensive to do processing in the data lake BUT we strongly encourage data platform designers to research and understand their cloud consumption pricing as we’ve seen instances where the opposite is true. | Depending on the data warehouse selected and the associated commercial terms, processing in the data warehouse can be expensive. |
| Reusability | Reusable functions and modules are readily available in Spark. All processing jobs are available, not just to deliver processed data to the data warehouse but also to other destinations (an increasingly popular use of cloud data platforms). | When available in cloud data warehouses, stored procedures and functions can provide reusable code. |

