(In the previous post, Part 1, we covered Data Writing.)
In this blog post, we continue on our series of exploring MyRocks mechanics by looking at configurable server variables and column family options. In our last post, I explained at a high level how data first entered memory space and in this post, we’re going to pick up where we left off and talk about how the flush from immutable memtable to disk occurs. We’re also going to talk about how newly created secondary indexes on existing tables get written to disk.
We already know from our previous post in the series that a flush can be prompted by one of several events, the most common of which would be when an active memtable is filled to its maximum capacity and is rotated into immutable status.
When your immutable memtable(s) is ready to flush, MyRocks will call a background thread to collect the data from memory and write it to disk. Depending on how often your records are updated, it’s possible that multiple versions of the same record may exist in the immutable memtable(s), so the flush thread will have to
check and remove any record duplication so only the latest record state gets added to the data file
.
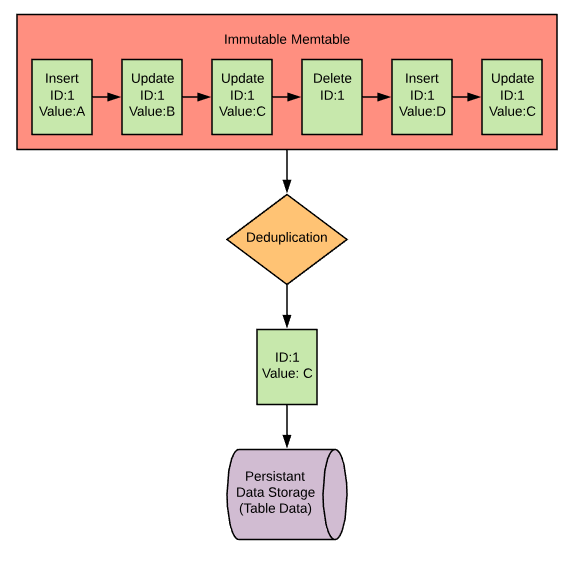 Once deduplication is complete, the contents of the immutable memtable are written to disk in a series of data blocks (4k by default) that make up the data file that you can find in your MyRocks data directory with the extension ‘.sst’. The size of the data file is going to be the same size as the immutable memtable(s). Remember, the size of your memtable is designated by the column family option write_buffer_size.
There is also metadata added to the file including checksums to ensure that there have been no issues with storage between the time the data file was written and the next time it’s read. Top level index information is also written in order to speed up the time it takes to locate the record you’re seeking within the file itself. Other forms of metadata within the data file will be addressed later in the series when we cover bloom filters.
Once deduplication is complete, the contents of the immutable memtable are written to disk in a series of data blocks (4k by default) that make up the data file that you can find in your MyRocks data directory with the extension ‘.sst’. The size of the data file is going to be the same size as the immutable memtable(s). Remember, the size of your memtable is designated by the column family option write_buffer_size.
There is also metadata added to the file including checksums to ensure that there have been no issues with storage between the time the data file was written and the next time it’s read. Top level index information is also written in order to speed up the time it takes to locate the record you’re seeking within the file itself. Other forms of metadata within the data file will be addressed later in the series when we cover bloom filters.
Once deduplication is complete, the contents of the immutable memtable are written to disk in a series of data blocks (4k by default) that make up the data file that you can find in your MyRocks data directory with the extension ‘.sst’. The size of the data file is going to be the same size as the immutable memtable(s). Remember, the size of your memtable is designated by the column family option write_buffer_size.
There is also metadata added to the file including checksums to ensure that there have been no issues with storage between the time the data file was written and the next time it’s read. Top level index information is also written in order to speed up the time it takes to locate the record you’re seeking within the file itself. Other forms of metadata within the data file will be addressed later in the series when we cover bloom filters.
Variables and CF_OPTIONS
Now that we know a little bit about how data is flushed from memory to disk, let’s take a more detailed look at the mechanics associated with the flushing process as well as the variables and options that are associated with them.Rocksdb_max_background_jobs
In my last post, we mentioned when flushing would occur based on memtable capacity, the size of the write buffer, etc. Once the system determines that a flush is required it will use a background thread to take the data from an immutable memtable and write it to disk. The variable rocksdb_max_background_jobs allows you to specify how many threads will sit in the background to support flushing. Keep in mind that this pool of background threads are used to support both flushing and compaction (we’ll discuss compaction in the next post in the series). In previous versions, the number of threads to support memtable to disk flushes was defined by the variable rocksdb_max_background_flushes; however, this is no longer the case as rocksdb_max_background_jobs replaced this variable and similar variables used to define the number of threads that would support compaction. Now all of these have been grouped together and the number of threads that will be used for memtable to disk flushes versus compaction will be automatically decided by MyRocks . Default: 2 The value of 2 isn’t all that surprising considering that in previous versions the value of rocksdb_max_background_compactions and rocksdb_max_background_flushes were both 1, meaning there was one thread for flushing and one for compaction, two threads total. We still have two threads, but now MyRocks will decide which process those threads are allocated to.Rocksdb_datadir
When MyRocks flushes data from immutable memtable to disk with the extension ‘.sst’, it will add data files to the MyRocks data directory. You can specify the location of this directory using the system variable rocksdb_datadir. Default: ./.rocksdb The default indicates that a directory called ‘.rocksdb’ will be created in the MySQL data directory. The MySQL data directory is defined in system variable datadir , which has a default value of /var/lib/mysql. Assuming both datadir and rocksdb_datadir are their default values, the location of the MyRocks data directory would be /var/lib/mysql/.rocksdb. I mentioned in my first post in this series that it’s not uncommon for users to want to separate sequential and random I/O, which is why you may want to put your write-ahead logs on one set of disks and your data directory on another. You can take this a step further by isolating your logs, data, and operating system. This is becoming less common as SSDs and similar technologies become the database storage of choice, but if you want to go the route of isolating your OS, data, and logs, you can leverage the rocksdb_datadir system variable for that purpose.Rocksdb_block_size
Data from immutable memtables are flushed into data files in their entirety after deduplication, but are further broken down into data blocks . These blocks serve as a way to partition the data within the data file in order to speed up lookups when you are looking for a specific record by its key. In each data file there is also what’s called a "top-level index" that provides a key name and offset for each block based on the last key that’s found in each block. If you’re looking for a specific key it will let you know what data block it’s, in leveraging the top level index and a blockhandle. You can specify how large each data block will be using the system variable rocksdb_block_size. Default: 4096 (4 Kb)Rocksdb_rate_limiter_bytes_per_sec
When the background thread is called upon to do a flush from memtable to disk, it will limit its disk activity based on the value of this variable. Keep in mind that this is the total amount of disk throughput allowed for all background threads, and as we stated earlier, background threads include memtable flushing and compaction. Default: 0 The default of 0, in this case, means that there is no limit imposed for disk activity. It may be worth considering setting this to a non zero value if you want to make sure disk activity from flushing and compaction doesn’t consume all of your I/O capacity, or if you want to save capacity for other processes such as reads. Keep in mind that if you slow down the process of writing memtable data to disk, under significant load you could theoretically stop write activity if you hit the maximum number of immutable memtables. For those of you that are familiar with InnoDB you may want to think of this as acting like innodb_io_capacity_max . One other important thing to note is that according to the documentation, this variable should be able to be changed dynamically; however, my testing has shown that changing this variable to/from a zero value requires a restart. I have created a bug with Percona to bring it to their attention.Rocksdb_force_flush_memtable_now
In the case that you would like to flush all the data in memtables to disk immediately, you can toggle this variable. A flush will occur, and then the variable will go back to its original value of ‘OFF’. One important thing to note is that during this flush process, all writes will be blocked until the flush has completed . Another important point to raise is that during my testing, I found that you could set this variable to any value including false and ‘OFF’ and it would still flush data to disk. You will need to exercise caution when working with this variable as setting it to its default value will still force a flush. In short, don’t set this variable to anything unless you want a flush to occur. I have opened a bug with Percona to raise bring this to their attention. Default: OFFRocksdb_checksums_pct
When data is written to disk there is a checksum that’s written to the SST file of a percentage of its contents . Much like the InnoDB variable innodb_checksum_algorithm , for those of you who are familiar, the purpose of this is to ensure that a checksum can be read as a data file is retrieved from disk in order to assure disk storage issues such as bit rot didn’t corrupt the data between the time it was written to disk and the time when it was later retrieved for a read operation. Default: 100 You may be able to increase overall performance by reducing the amount of data that is read to support the checksum, but I would recommend against it as you want to have that assurance that data being read is the same as when it was written.Rocksdb_paranoid_checks
In addition to checksumming, there is another fault tolerance measure you can take to ensure the accuracy of written data and this is called "‘ paranoid checking" . With paranoid checking enabled, data files will be read immediately after they are written in order to ensure the accuracy of the data. Default: ON I would be inclined to leave this enabled as I prefer to do all possible checking in order to make sure data is written with the highest degree of accuracy.Rocksdb_use_fsync
When data files are written to disk, they are typically done using fdatasync() which utilizes caching in Linux, but doesn’t offer assurances that data is actually on disk at the end of the call. In order to get that assurance, you can use the variable rocksdb_use_fsync to specify that you would rather have MyRocks call fsync() which will assure a disk sync at the time that the request to write data is complete. Default: OFF The most likely reason that this is disabled is to allow for the performance gains achieved by the asynchronous data writing nature of fdatasync(). Potential data loss of data sitting in the OS cache but not on disk during a full system crash may or may not be acceptable for your workload, so you may want to consider adjusting this variable.Rocksdb_use_direct_io_for_flush_and_compaction
If you would rather avoid the disk caching elements of fdatasync() or fsync() for writes to data files via memtables flushes or compaction, you have the option to do so by enabling the variable rocksdb_use_direct_io_for_flush_and_compaction. When it comes to flushing and compaction this will override the value of rocksdb_use_fsync and instead will specify that MyRocks should call O_DIRECT() when writing data to disk. Default: OFF In the wiki for RocksDB , you will see that performance gains from using O_DIRECT() are dependent on your use case and are not assured. This is true of all storage engines and testing should always be performed before attempting to adjust a variable like this. Keep in mind that I have recommended O_DIRECT in the past for InnoDB , but that doesn’t apply here as MyRocks is a very different engine and there really isn’t enough data out there to say what is the best write method for most use cases so far. Exercise caution when changing your write method.Rocksdb_bytes_per_sync
Another thing that is important to understand about syncing to disk is knowing how often it occurs, and that’s where rocksdb_bytes_per_sync comes into play. This variable controls how often a call is made to sync data during the process while data is being written to disk, specifically after how many bytes have been written. Keep in mind that write-ahead logs have their own variable, rocksdb_wal_bytes_per_sync, so rocksdb_bytes_per_sync is just for data files. Also, be aware that depending on what syncing function is called (see above for rocksdb_use_fsync and rocksdb_use_direct_io_for_flush_and_compaction) this may be an asynchronous request for a disk sync. Default: 0 With the default value of 0, MyRocks will disable the feature of requesting syncs after the designated number of bytes and instead will rely on the OS to determine when syncing should occur. It is recommended that users of MyRocks not use this feature as a way of ensuring a persistency guarantee.Rocksdb_merge_buf_size
Typically, when new data gets flushed into persisted space, it ends up in the highest compaction layer, L0. This will be explained in more detail in the next blog post. There is one exception to this rule and that’s when a new secondary index is added to an existing table, which will skip this process and gets written to the bottom-most level of compaction available, which in MyRocks is L6 by default. Think of this as a way for secondary index data to get to its final destination faster. It does this by doing a merge sort of existing data to support the secondary index. In order to better understand merge sort processes, I would recommend reading this blog post on hackernoon . There is a memory cache that is used to support the merge sort process specifically for secondary index creation and it’s called the ‘merge buffer’. The rocksdb_merge_buf_size determines how large this buffer will be. Default: 64MbRocksdb_merge_combine_read_size
If you checked out the blog post on hackernoon that I mentioned, you’ll know that sorting eventually requires combining the smaller broken down sub-arrays back into the full sorted list. In the case of MyRocks, this uses a completely separate buffer called the "merge combine buffer". The variable rocksdb_merge_combine_read_size determines how large the merge combine buffer will be. Default: 1 Gb You’ll see in the next variable we cover (rocksdb_merge_tmp_file_removal_delay_ms) that MyRocks will create merge files on disk to help support the process of creating new secondary indexes so I/O can occur, but with larger memory buffers you will see less IO. My take on this would be to not change the global value of this variable, but instead to change it only within the session that I’m using to create the secondary index. Keep in mind that the tradeoff here is that you’re using more memory to speed up index creation; however, if you set the global value of this variable to a large size and forget about it, that large amount of memory may be allocated when you didn’t expect it, which may consume more memory resources than you anticipated, which could lead to issues like OOM, etc.Rocksdb_merge_tmp_file_removal_delay_ms
In addition to the in-memory resources used to work with the merge sort process of creating new secondary indexes, you may also get merge files created on disk. These are temporary files that you will find in the MyRocks data directly with the .tmp extension. Once the secondary index completion process is created, it will immediately delete these files. For storage solutions like flash, removing large amounts of data can cause trim stalls. This variable will allow you to apply a rate limit delay to this process in order to help prevent this issue. Default: 0 (no delay) I wouldn’t change the value of this variable unless you have flash storage. If you do use flash storage, you can test by creating and removing indexes to determine what value would be best for this variable. Given that there are no other implications to setting this variable, I would recommend setting the variable globally, including an addition to the my.cnf.Associated Metrics
Here are some of the metrics you should be paying attention to when it comes to initial data flushing. You can find the following information using system status variables- Rocksdb_flush_write_bytes: Shows the amount of data that has been written to disk as part of a flush, in bytes, since the last MySQL restart.
- Rocksdb_number_sst_entry_delete: The number of record delete markers written by MyRocks to a data file since the last MySQL restart.
- Rocksdb_number_sst_entry_singledelete: The number of record single delete markers written by MyRocks to a data file since the last MySQL restart. This will make a bit more sense after we cover SingleDelete() markers in the next post in the series.
- Rocksdb_number_deletes_filtered: Shows the number of times a deleted record was not persisted to disk if it made reference to a key that not exist since the last MySQL restart.
- Rocksdb_stall_memtable_limit_slowdowns: The number of slowdowns that have occurred due to MyRocks getting close to the maximum number of allowed memtables since the last MySQL restart.
- Rocksdb_stall_memtable_limit_stops: The number of write stalls that have occurred due to MyRocks hitting the maximum number of allowed memtables since the last MySQL restart.
- Rocksdb_stall_total_slowdowns: The total number of slowdowns that have occurred in the MyRocks engine since the last MySQL restart.
- Rocksdb_stall_total_stops: The total number of write stalls that have occurred in the MyRocks engine since the last MySQL restart.
- Rocksdb_stall_micros: How long the data writer had to wait for a flush to finish since the last restart of MySQL.
- MEM_TABLE_FLUSH_PENDING: Shows you if there is a pending operation to flush an immutable memtable to disk.
- wait/synch/mutex/rocksdb/sst commit: Shows the amount of mutex time wait during the sst (data file) commit process.

